Обычно выделяют две общие категории потоков: потоки на уровне пользователя (user-level threads — ULT) и потоки на уровне ядра (kernel-level threads — KLT). Потоки второго типа в литературе иногда называются потоками, поддерживаемыми ядром, или облегченными процессами.
Потоки на уровне пользователя
В программе, полностью состоящей из ULT-потоков, все действия по управлению потоками выполняются самим приложением; ядро, по сути, и не подозревает о существовании потоков. На рис. 4.6,а проиллюстрирован подход, при котором используются только потоки на уровне пользователя. Чтобы приложение было многопоточным, его следует создавать с применением специальной библиотеки, представляющей собой пакет программ для работы с потоками на уровне ядра. Такая библиотека для работы с потоками содержит код, с помощью которого можно создавать и удалять потоки, производить обмен сообщениями и данными между потоками, планировать их выполнение, а также сохранять и восстанавливать их контекст.
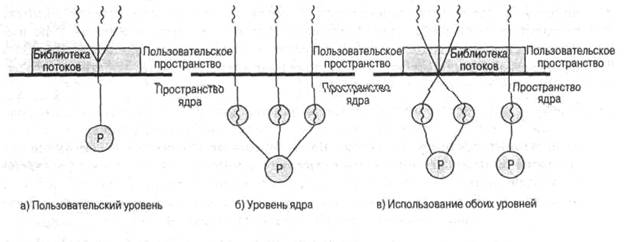
Рис. 4.6. Потоки на пользовательском уровне и на уровне ядра
По умолчанию приложение в начале своей работы состоит из одного потока и его выполнение начинается как выполнение этого потока. Такое приложение вместе с составляющим его потоком размещается в едином процессе, который управляется ядром. Выполняющееся приложение в любой момент времени может породить новый поток, который будет выполняться в пределах того же процесса. Новый поток создается с помощью вызова специальной подпрограммы из библиотеки, предназначенной для работы с потоками. Управление к этой подпрограмме переходит в результате вызова процедуры. Библиотека потоков создает структуру данных для нового потока, а потом передает управление одному из готовых к выполнению потоков данного процесса, руководствуясь некоторым алгоритмом планирования. Когда управление переходит к библиотечной подпрограмме, контекст текущего потока сохраняется, а когда управление возвращается к потоку, его контекст восстанавливается. Этот контекст в основном состоит из содержимого пользовательских регистров, счетчика команд и указателей стека.
Все описанные в предыдущих абзацах события происходят в пользовательском пространстве в рамках одного процесса. Ядро не подозревает об этой деятельности. Оно продолжает осуществлять планирование процесса как единого целого и приписывать ему единое состояние выполнения (состояние готовности, состояние выполняющегося процесса, состояние блокировки и т.д.). Приведенные ниже примеры должны прояснить взаимосвязь между планированием потоков и планированием процессов. Предположим, что выполняется поток 2, входящий в процесс В (см. рис. 4.7). Состояния этого процесса и составляющих его потоков на пользовательском уровне показаны на рис. 4.7,а. Впоследствии может произойти одно из следующих событий.
- Приложение, в котором выполняется поток 2, может произвести системный вызов, например запрос ввода-вывода, который блокирует процесс В. В результате этого вызова управление перейдет к ядру. Ядро вызывает процедуру ввода-вывода, переводит процесс В в состояние блокировки и передает управление другому процессу. Тем временем поток 2 процесса В все еще находится в состоянии выполнения в соответствии со структурой данных, поддерживаемой библиотекой потоков. Важно отметить, что поток 2 не выполняется в том смысле, что он работает с процессором; однако библиотека потоков воспринимает его как выполняющийся. Соответствующие диаграммы состояний показаны на рис. 4.7,6.
- В результате прерывания по таймеру управление может перейти к ядру; ядро определяет, что интервал времени, отведенный выполняющемуся в данный момент процессу В, истек. Ядро переводит процесс В в состояние готовности и передает управление другому процессу. В это время, согласно структуре данных, которая поддерживается библиотекой потоков, поток 2 процесса В по-прежнему будет находиться в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,в.
- Поток 2 достигает точки выполнения, когда ему требуется, чтобы поток 1 процесса В выполнил некоторое действие. Он переходит в заблокированное состояние, а поток 1 — из состояния готовности в состояние выполнения. Сам процесс остается в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,г.
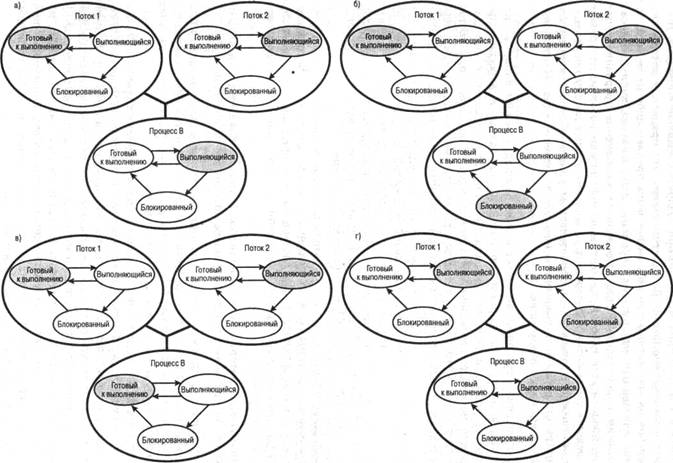
Рис. 4.7. Примеры взаимосвязей между состояниями потоков пользовательского уровня и состояниями процесса
В случаях 1 и 2 (см. рис. 4.7,6 и в) при возврате управления процессу В возобновляется выполнение потока 2. Заметим также, что процесс, в котором выполняется код из библиотеки потоков, может быть прерван либо из-за того, что закончится отведенный ему интервал времени, либо из-за наличия процесса с более высоким приоритетом. Когда возобновится выполнение прерванного процесса, оно продолжится работой процедуры из библиотеки потоков, которая завершит переключение потоков и передаст управление новому потоку процесса.
Использование потоков на пользовательском уровне обладает некоторыми преимуществами перед использованием потоков на уровне ядра. К этим преимуществам относятся следующие:
- Переключение потоков не включает в себя переход в режим ядра, так как структуры данных по управлению потоками находятся в адресном пространстве одного и того же процесса. Поэтому для управления потоками процессу не нужно переключаться в режим ядра. Благодаря этому обстоятельству удается избежать накладных расходов, связанных с двумя переключениями режимов (пользовательского режима в режим ядра и обратно).
- Планирование производится в зависимости от специфики приложения. Для одних приложений может лучше подойти простой алгоритм планирования по круговому алгоритму, а для других — алгоритм планирования, основанный на использовании приоритета. Алгоритм планирования может подбираться для конкретного приложения, причем это не повлияет на алгоритм планирования, заложенный в операционной системе.
- Использование потоков на пользовательском уровне применимо для любой операционной системы. Для их поддержки в ядро системы не потребуется вносить никаких изменений. Библиотека потоков представляет собой набор утилит, работающих на уровне приложения и совместно используемых всеми приложениями.
Использование потоков на пользовательском уровне обладает двумя явными недостатками по сравнению с использованием потоков на уровне ядра.
- В типичной операционной системе многие системные вызовы являются блокирующими. Когда в потоке, работающем на пользовательском уровне, выполняется системный вызов, блокируется не только данный поток, но и все потоки того процесса, к которому он относится.
- В стратегии с наличием потоков только на пользовательском уровне приложение не может воспользоваться преимуществами многопроцессорной системы, так как ядро закрепляет за каждым процессом только один процессор. Поэтому несколько потоков одного и того же процесса не могут выполняться одновременно. В сущности, у нас получается многозадачность на уровне приложения в рамках одного процесса. Несмотря на то, что даже такая многозадачность может привести к значительному увеличению скорости работы приложения, имеются приложения, которые работали бы гораздо лучше, если бы различные части их кода могли выполняться одновременно.
Эти две проблемы разрешимы. Например, их можно преодолеть, если писать приложение не в виде нескольких потоков, а в виде нескольких процессов. Однако при таком подходе основные преимущества потоков сводятся на нет: каждое переключение становится не переключением потоков, а переключением процессов, что приведет к значительно большим накладным затратам.
Другим методом преодоления проблемы блокирования является использование преобразования блокирующего системного вызова в неблокирующий. Например, вместо непосредственного вызова системной процедуры ввода-вывода поток вызывает подпрограмму-оболочку, которая производит ввод-вывод на уровне приложения. В этой программе содержится код, который проверяет, занято ли устройство ввода-вывода. Если оно занято, поток передает управление другому потоку (что происходит с помощью библиотеки потоков). Когда наш поток вновь получает управление, он повторно осуществляет проверку занятости устройства ввода-вывода.
Потоки на уровне ядра
В программе, работа которой полностью основана на потоках, работающих на уровне ядра, все действия по управлению потоками выполняются ядром. В области приложений отсутствует код, предназначенный для управления потоками. Вместо него используется интерфейс прикладного программирования (application programming interface — API) средств ядра, управляющих потоками. Примерами такого подхода являются операционные системы OS/2, Linux и W2K.
На рис. 4.6,6" проиллюстрирована стратегия использования потоков на уровне ядра. Любое приложение при этом можно запрограммировать как многопоточное; все потоки приложения поддерживаются в рамках единого процесса. Ядро поддерживает информацию контекста процесса как единого целого, а также контекстов каждого отдельного потока процесса. Планирование выполняется ядром исходя из состояния потоков. С помощью такого подхода удается избавиться от двух упомянутых ранее основных недостатков потоков пользовательского уровня. Во-первых, ядро может одновременно осуществлять планирование работы нескольких потоков одного и того же процесса на нескольких процессорах. Во-вторых, при блокировке одного из потоков процесса ядро может выбрать для выполнения другой поток этого же процесса. Еще одним преимуществом такого подхода является то, что сами процедуры ядра могут быть многопоточными.
Основным недостатком подхода с использованием потоков на уровне ядра по сравнению с использованием потоков на пользовательском уровне является то, что для передачи управления от одного потока другому в рамках одного и того же процесса приходится переключаться в режим ядра. Результаты исследований, проведенных на однопроцессорной машине VAX под управлением UNIX-подобной операционной системы, представленные в табл. 4.1, иллюстрируют различие между этими двумя подходами. Сравнивалось время выполнения таких двух задач, как (1) нулевое ветвление (Null Fork) — время, затраченное на создание, планирование и выполнение процесса/потока, состоящего только из нулевой процедуры (измеряются только накладные расходы, связанные с ветвлением процесса/потока), и (2) ожидание сигнала (Signal-Wait) — время, затраченное на передачу сигнала от одного процесса/потока другому процессу/потоку, находящемуся в состоянии ожидания (накладные расходы на синхронизацию двух процессов/потоков). Чтобы было легче сравнивать полученные значения, заметим, что вызов процедуры на машине VAX, используемой в этом исследовании, длится 7 us, а системное прерывание — 17 us. Мы видим, что различие во времени выполнения потоков на уровне ядра и потоков на пользовательском уровне более чем на порядок превосходит по величине различие во времени выполнения потоков на уровне ядра и процессов.
Таблица 4.1. Время задержек потоков (ка) [ANDE92]

Таким образом, создается впечатление, что как применение многопоточности на уровне ядра дает выигрыш по сравнению с процессами, так и многопоточность на пользовательском уровне дает выигрыш по сравнению с многопоточностью на пользовательском уровне. Однако на деле возможность этого дополнительного выигрыша зависит от характера приложений. Если для большинства переключений потоков приложения необходим доступ к ядру, то схема с потоками на пользовательском уровне может работать не намного лучше, чем схема с потоками на уровне ядра.
Комбинированные подходы
В некоторых операционных системах применяется комбинирование потоков обоих видов (рис. 4.6,в). Ярким примером такого подхода может служить операционная система Solaris. В комбинированных системах создание потоков выполняется в пользовательском пространстве, там же, где и код планирования и синхронизации потоков в приложениях. Несколько потоков на пользовательском уровне, входящих в состав приложения, отображаются в такое же или меньшее число потоков на уровне ядра. Программист может изменять число потоков на уровне ядра, подбирая его таким, которое позволяет достичь наилучших результатов.
При комбинированном подходе несколько потоков одного и того же приложения могут выполняться одновременно на нескольких процессорах, а блокирующие системные вызовы не приводят к блокировке всего процесса. При надлежащей реализации такой подход будет сочетать в себе преимущества подходов, в которых применяются только потоки на пользовательском уровне или только потоки на уровне ядра, сводя недостатки каждого из этих подходов к минимуму.
Другие схемы
Как уже упоминалось, понятия единицы распределения ресурсов и планирования традиционно отождествляются с понятием процесса. В такой концепции поддерживается однозначное соответствие между потоками и процессами. В последнее время наблюдается интерес к использованию нескольких потоков в одном процессе, когда выполняется соотношение многие-к-одному. Однако возможны и другие комбинации, а именно соответствие нескольких потоков нескольким процессам и соответствие одного потока нескольким процессам. Примеры применения каждой из упомянутых комбинаций приводятся в табл. 4.2.
Таблица 4.2. Соотношение между потоками и процессами

Соответствие нескольких потоков нескольким процессам
Идея реализации соответствия нескольких процессов нескольким потокам была исследована в экспериментальной операционной системе TRIX [SIEB83, WARD80]. В данной операционной системе используются понятия домена и потока. Домен — это статический объект, состоящий из адресного пространства и портов, через которые можно отправлять и получать сообщения. Поток — это единая выполняемая ветвь, обладающая стеком выполнения и характеризующаяся состоянием процессора, а также информацией по планированию.
Как и в других указанных ранее многопоточных подходах, в рамках одного домена могут выполняться несколько потоков. При этом удается получить уже описанное повышение эффективности работы. Кроме того, имеется возможность осуществлять деятельность одного и того же пользователя или приложения в нескольких доменах. В этом случае имеется поток, который может переходить из одного домена в другой.
По-видимому, использование одного и того же потока в разных доменах продиктовано желанием предоставить программисту средства структурирования. Например, рассмотрим программу, в которой используется подпрограмма ввода-вывода. В многозадачной среде, в которой пользователю позволено создавать процессы, основная программа может сгенерировать новый процесс для управления вводом-выводом, а затем продолжить свою работу. Однако если для дальнейшего выполнения основной программы необходимы результаты операции ввода-вывода, то она должна ждать, пока не закончится работа подпрограммы ввода-вывода. Подобное приложение можно осуществить такими способами.
- Реализовать всю программу в виде единого процесса. Такой прямолинейный подход является вполне обоснованным. Недостатки этого подхода связаны с управлением памятью. Эффективно организованный как единое целое процесс может занимать в памяти много места, в то время как для подпрограммы ввода-вывода требуется относительно небольшое адресное пространство. Из-за того что подпрограмма ввода-вывода выполняется в адресном пространстве более объемной программы, во время выполнения ввода-вывода весь процесс должен оставаться в основной памяти, либо операция ввода-вывода будет выполняться с применением свопинга. То же происходит и в случае, когда и основная программа, и подпрограмма ввода-вывода реализованы в виде двух потоков в одном адресном пространстве.
- Основная программа и подпрограмма ввода-вывода реализуются в виде двух отдельных процессов. Это приводит к накладным затратам, возникающим в результате создания подчиненного процесса. Если ввод-вывод производится достаточно часто, то необходимо будет либо оставить такой подчиненный процесс активным на все время работы основного процесса, что связано с затратами на управление ресурсами, либо часто создавать и завершать процесс с подпрограммой, что приведет к снижению эффективности.
- Реализовать действия основной программы и подпрограммы ввода-вывода как единый поток. Однако для основной программы следует создать свое адресное пространство (свой домен), а для подпрограммы ввода-вывода — свое. Таким образом, поток в ходе выполнения программы будет переходить из одного адресного пространства к другому. Операционная система может управлять этими двумя адресными пространствами независимо, не затрачивая никаких дополнительных ресурсов на создание процесса. Более того, адресное пространство, используемое подпрограммой ввода-вывода, может использоваться совместно с другими простыми подпрограммами ввода-вывода.
Опыт разработчиков операционной системы TRIX свидетельствует о том, что третий вариант заслуживает внимания и для некоторых приложений может оказаться самым эффективным.
Соответствие одного потока нескольким процессам
В области распределенных операционных систем (разрабатываемых для управления распределенными компьютерными системами) представляет интерес концепция потока как основного элемента, способного переходить из одного адресного пространства в другое (В последние годы активно исследуется тема перехода процессов и потоков из одного адресного пространства в другое (миграция). Эта тема рассматривается в главе 14, "Управление распределенными процессами".). Заслуживают упоминания операционная система Clouds и, в особенности, ее ядро, известное под названием Ra [DASG92]. В качестве другого примера можно привести систему Emerald [STEE95].
В операционной системе Clouds поток является единицей активности с точки зрения пользователя. Процесс имеет вид виртуального адресного пространства с относящимся к нему управляющим блоком. После создания поток начинает выполнение в рамках процесса. Потоки могут переходить из одного адресного пространства в другое и даже выходить за рамки машины (т.е. переходить из одного компьютера в другой). При переходе потока в другое место он должен нести с собой определенную информацию — такую, как управляющий терминал, глобальные параметры и сведения по его планированию (например, приоритет).
Подход, применяющийся в операционной системе Clouds, является эффективным способом изоляции пользователя и программиста от деталей распределенной среды. Деятельность пользователя может ограничиваться одним потоком, а перемещение этого потока из одной машины в другую может быть обусловлено функционированием операционной системы, руководствующейся такими обстоятельствами, как необходимость доступа к удаленным ресурсам или выравнивание загрузки машин.
