До сих пор концепцию процесса можно было охарактеризовать двумя параметрами.
- Владение ресурсами (resource ownership). Процесс включает виртуальное адресное пространство, в котором содержится образ процесса, и время от времени может владеть такими ресурсами, как основная память, каналы и устройства ввода-вывода, или файлы, или же получать контроль над ними. Операционная система выполняет защитные функции, предотвращая нежелательные взаимодействия процессов на почве владения ресурсами.
- Планирование/выполнение (scheduling/execution). Выполнение процесса осуществляется путем выполнения кода одной или нескольких программ; при этом выполнение процесса может чередоваться с выполнением других процессов. Таким образом, процесс имеет такие параметры, как состояние (выполняющийся процесс, готовый к выполнению процесс и т.д.) и текущий приоритет, в соответствии с которым операционная система осуществляет его планирование и диспетчеризацию.
В большинстве операционных систем эти две характеристики являются сущностью процесса. Однако, немного подумав, читатель может убедиться, что они являются независимыми, и что операционная система может рассматривать их отдельно друг от друга.В некоторых операционных системах (в особенности в недавно разработанных) так и происходит. Чтобы различать две приведенные выше характеристики, единицу диспетчеризации обычно называют потоком (thread) или облегченным процессом (lightweight process), а единицу владения ресурсами — процессом (process) или заданием (task).
Увы, последовательность в использовании терминологии не выдерживается даже в такой степени. В операционной системе OS/390, предназначенной для мейнфреймов IBM, концепции адресного пространства и задания примерно соответствуют концепциям процесса и потока, описанным в этом разделе. Кроме того, термин упрощенный процесс (lightweight process) используется в трех значениях: (1) он эквивалентен термину поток (thread), (2) обозначает поток особого вида, известный как поток на уровне ядра (kernel-level thread) или (3) (в операционной системе Solaris) элемент, отображающий потоки на уровне пользователя в потоки на уровне ядра.
Многопоточность
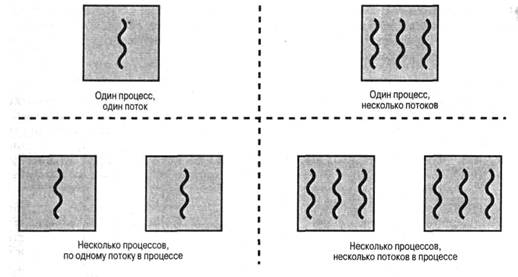
Многопоточностью (multithreading) называется способность операционной системы поддерживать в рамках одного процесса выполнение нескольких потоков. Традиционный подход, при котором каждый процесс представляет собой единый поток выполнения, называется однопоточным подходом. Две левые части рис. 4.1 иллюстрируют однопоточные подходы. MS DOS является примером операционной системы, способной поддерживать не более одного однопоточного пользовательского процесса. Другие операционные системы, такие, как разнообразные разновидности UNIX, поддерживают процессы множества пользователей, но в каждом из этих процессов может содержаться только один поток. В правой половине рис. 4.1 представлены многопоточные подходы. Примером системы, в которой один процесс может расщепляться на несколько потоков, является среда выполнения Java. В этом разделе нас будет интересовать использование нескольких процессов, каждый из которых поддерживает выполнение нескольких потоков. Подобный подход принят в таких операционных системах, как OS/2, Windows 2000 (W2K), Linux, Solaris, Mach, и ряде других. В этом разделе приведено общее описание многопоточного режима, а в последующих разделах будут подробно рассмотрены подходы, использующиеся в операционных системах W2K, Solaris и Linux.
Выполнение машинных команд
Рис. 4.1. Потоки и процессы [ANDE97]
В многопоточной среде процесс определяется как структурная единица распределения ресурсов, а также структурная единица защиты. С процессами связаны следующие элементы.
- Виртуальное адресное пространство, в котором содержится образ процесса.
- Защищенный доступ к процессорам, другим процессам (при обмене информацией между ними), файлам и ресурсам ввода-вывода (устройствам и каналам).
В рамках процесса могут находиться один или несколько потоков, каждый из которых обладает следующими характеристиками.
- Состояние выполнения потока (выполняющийся, готовый к выполнению и т.д.).
- Сохраненный контекст не выполняющегося потока; один из способов рассмотрения потока — считать его независимым счетчиком команд, работающим в рамках процесса.
- Стек выполнения
- Статическая память, выделяемая потоку для локальных переменных.
- Доступ к памяти и ресурсам процесса, которому этот поток принадлежит; этот доступ разделяется всеми потоками данного процесса.
На рис. 4.2 продемонстрировано различие между потоками и процессами с точки зрения управления последними. В однопоточной модели процесса в его представление входит управляющий блок этого процесса и пользовательское адресное пространство, а также стеки ядра и пользователя, с помощью которых осуществляются вызовы процедур и возвраты из них при выполнении процесса. Когда выполнение процесса прерывается, содержимое регистров процессора сохраняется в памяти. В многопоточной среде с каждым процессом тоже связаны управляющий блок и адресное пространство, но теперь для каждого потока создаются свои отдельные стеки, а также свой управляющий блок, в котором содержатся значения регистров, приоритет и другая информация о состоянии потока.
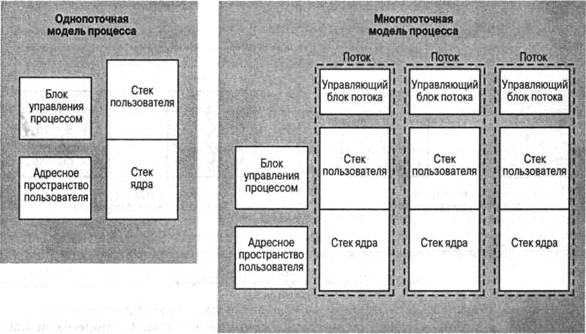
Рис. 4.2. Однопоточная и многопоточная модели процесса
Таким образом, все потоки процесса разделяют между собой состояние и ресурсы этого процесса. Они находятся в одном и том же адресном пространстве и имеют доступ к одним и тем же данным. Если один поток изменяет в памяти какие-то данные, то другие потоки во время своего доступа к этим данным имеют возможность отследить эти изменения. Если один поток открывает файл с правом чтения, другие потоки данного процесса тоже могут читать из этого файла.
Перечислим основные преимущества использования потоков с точки зрения производительности:
- Создание нового потока в уже существующем процессе занимает намного меньше времени, чем создание совершенно нового процесса. Исследования, проведенные разработчиками операционной системы Mach, показали, что скорость создания процессов по сравнению с такой же скоростью в UNIX-совместимых приложениях, в которых не используются потоки, возрастает в 10 раз [TEVA87].
- Поток можно завершить намного быстрее, чем процесс.
- Переключение потоков в рамках одного и того же процесса происходит намного быстрее.
- При использовании потоков повышается эффективность обмена информацией между двумя выполняющимися программами. В большинстве операционных систем обмен между независимыми процессами происходит с участием ядра, в функции которого входит обеспечение защиты и механизма, необходимого для осуществления обмена. Однако благодаря тому, что различные потоки одного и того же процесса используют одну и ту же область памяти и одни и те же файлы, они могут обмениваться информацией без участия ядра.
Итак, если приложение или функцию нужно реализовать в виде набора взаимосвязанных модулей, намного эффективнее реализовать ее в виде набора потоков, чем в виде набора отдельных процессов.
Примером приложения, в котором можно удачно применить потоки, является файловый сервер. При получении каждого нового файлового запроса программа управления файлами может порождать новый поток. Из-за того, что серверу приходится обрабатывать очень большое количество запросов, за короткий промежуток времени будут создаваться и удаляться множество потоков. Если такая серверная программа работает на многопроцессорной машине, то на разных процессорах в рамках одного процесса могут одновременно выполняться несколько потоков. Кроме того, из-за того, что процессы или потоки файлового сервера должны совместно использовать данные из файлов, а следовательно, координировать свои действия, рациональнее использовать потоки и общую область памяти, а не процессы и обмен сообщениями.
Потоковая конструкция процесса полезна и на однопроцессорных машинах. Она помогает упростить структуру программы, выполняющей несколько логически различных функций.
В [LETW88] приводится четыре следующих примера использования потоков в однопользовательской многозадачной системе.
Работа в приоритетном и фоновом режимах. В качестве примера можно привести программу электронных таблиц, в которой один из потоков может отвечать за отображение меню и считывать ввод пользователя, а другой — выполнять команды пользователя и обновлять таблицу. Такая схема часто увеличивает воспринимаемую пользователем скорость работы приложения, позволяя пользователю начать ввод следующей команды еще до завершения выполнения предыдущей.
Асинхронная обработка. Элементы асинхронности в программе можно реализовать в виде потоков. Например, в качестве меры предосторожности на случай отключения электричества можно сделать так, чтобы текстовый редактор каждую минуту сбрасывал на диск содержимое буфера оперативного запоминающего устройства. Можно создать поток, единственной задачей которого будет создание резервной копии и который будет планировать свою работу непосредственно с помощью операционной системы. Это позволит обойтись без помещения в основную программу замысловатого кода, обеспечивающего проверку соблюдения временного графика или координацию ввода и вывода.
Скорость выполнения. Многопоточный процесс может производить вычисления с одной порцией данных, одновременно считывая с устройства ввода-вывода следующую порцию. В многопроцессорной системе несколько потоков одного и того же процесса могут выполняться одновременно.
Модульная структура программы. Программы, осуществляющие разнообразные действия или выполняющие множество вводов из различных источников и выводов в разные места назначения, легче разрабатывать и реализовывать с помощью потоков.
Планирование и диспетчеризация осуществляются на основе потоков; таким образом, большая часть информации о состоянии процесса, имеющей отношение к его выполнению, поддерживается в структурах данных на уровне потоков. Однако есть несколько действий, которые затрагивают все потоки процесса и которые операционная система должна поддерживать именно на этом уровне. Если процесс приостанавливается, то при этом предполагается, что его адресное пространство будет выгружено из основной памяти. Поскольку все потоки процесса используют одно и то же адресное пространство, все они должны одновременно перейти в состояние приостановленных. Соответственно прекращение процесса приводит к прекращению всех составляющих его потоков.
Функциональность потоков
Потоки, подобно процессам, характеризуются состояниями выполнения; кроме того, они могут быть синхронизированы друг с другом. Рассмотрим по очереди эти два аспекта.
Состояния потоков
Основными состояниями потоков, как и процессов, являются: состояние выполнения потока, состояние готовности и состояние блокировки. Вообще говоря, состояние приостановки нет смысла связывать с потоками, потому что такие состояния логичнее рассматривать на уровне процессов. В частности, если процесс приостанавливается, обязательно приостанавливаются все его потоки, потому что все они совместно используют адресное пространство этого процесса.
С изменением состояния потоков связаны такие четыре основных действия [ANDE97].
- Порождение. Обычно во время создания нового процесса вместе с ним создается поток этого процесса. Далее, в рамках одного и того же процесса один поток может породить другой поток, определив его указатель команд и аргументы. Новый поток создается со своим собственным контекстом регистров и стековым пространством, после чего он помещается в очередь готовых к выполнению потоков.
- Блокирование. Если потоку нужно подождать, пока не наступит некоторое событие, он блокируется (при этом сохраняется содержимое его пользовательских регистров, счетчика команд, а также указатели стеков). После этого процессор может перейти к выполнению другого готового потока.
- Разблокирование. Когда наступает событие, ожидание которого блокировало поток, последний переходит в состояние готовности.
- Завершение. После завершения потока его контекст регистров и стеки удаляются.
Важно понять, должно ли блокирование потока обязательно приводить к блокированию всего процесса. Другими словами, могут ли выполняться какие-нибудь готовые к выполнению потоки процесса, если один из его потоков блокирован? Ясно, что если блокировка одного из потоков будет приводить к блокировке всего процесса, то это существенно уменьшит гибкость и эффективность потоков.
Мы еще вернемся к обсуждению этого вопроса при сравнении потоков на пользовательском уровне и потоков на уровне ядра, а пока что рассмотрим выигрыш в производительности при использовании потоков, которые не блокируют весь процесс. На рис. 4.3 (из [KLEI96]) показана программа, выполняющая два вызова удаленных процедур (remote procedure call — RPC) на двух разных узлах, чтобы получить результат после их совместного выполнения. В однопоточной программе результаты получаются последовательно, поэтому программа должна ожидать, пока от каждого сервера по очереди будет получен ответ. Переписав программу так, чтобы для каждого вызова удаленной процедуры она использовала отдельный поток, можно получить существенный выигрыш в скорости. Заметим, что если такая программа работает на однопроцессорной машине, то запросы будут генерироваться последовательно; результаты тоже будут получены последовательно, однако программа будет ожидать двух ответов одновременно.
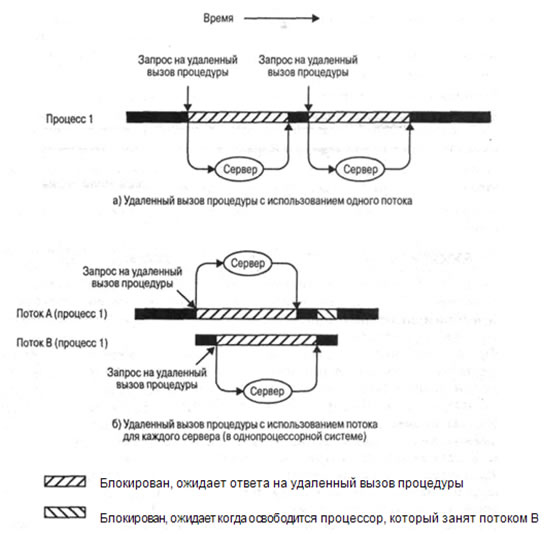
Рис. 4.3. Удаленный вызов процедуры (RPC), в котором используются потоки
В однопроцессорных системах многозадачность позволяет чередовать различные потоки нескольких процессов. В примере, показанном на рис. 4.4, чередуются три потока, принадлежащие двум процессам. Передача управления от одного процесса другому происходит либо тогда, когда блокируется выполняющийся поток, либо когда заканчивается интервал времени, отведенный для его выполнения.
В этом примере поток С начинает выполняться, после того как оканчивается интервал времени, отведенный потоку А, несмотря на то что поток В находится в состоянии готовности. Выбор между потоками В и С — это вопрос планирования; данная тема исследуется в четвертой части книги.
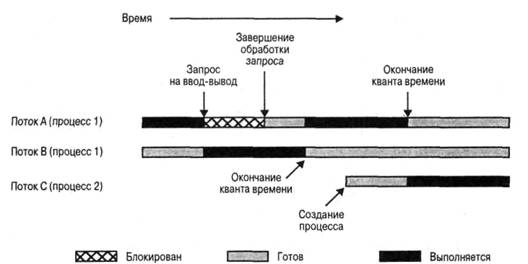
Рис. 4.4. Пример многопоточности в однопроцессорной системе
Синхронизация потоков
Все потоки процесса используют одно и то же адресное пространство, как и другие ресурсы, например открытые файлы. Любое изменение какого-нибудь ресурса одним из потоков процесса оказывает влияние на другие потоки этого же процесса. Поэтому действия различных потоков необходимо синхронизировать, чтобы они не мешали друг другу или чтобы не повредили структуры данных. Например, если каждый из двух потоков будет пытаться добавить свой элемент в двунаправленный список, может быть потерян один из элементов (или нарушена целостность списка).
Пример: Adobe PageMaker
Рассмотрим использование потоков на примере приложения Adobe PageMaker, работающего под управлением операционной системы Linux. Программа PageMaker является настольным издательским средством, предназначенным для создания и форматирования документов. Для оптимизации скорости отклика этого приложения была выбрана потоковая структура, показанная на рис. 4.5 [KRON90]. Три потока активны всегда — поток, отвечающий за обработку событий, поток, обновляющий экран, и служебный поток.
Операции, на которые требуется много времени (печать, импорт данных и заливка), выполняются в служебном потоке программы PageMaker, чтобы не блокировать этими операциями возможность обработки поступающих сообщений. В этом же потоке происходит большая часть инициализации программы, что позволяет избежать простоя, который мог бы возникнуть при создании нового документа или открытии уже существующего. Отдельный поток служит для обработки сообщений о новых событиях.
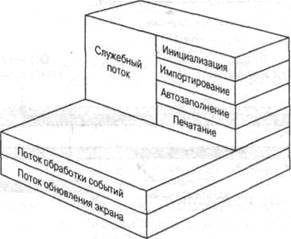
Рис. 4.5. Потоковая структура программы Adobe PageMaker
Синхронизация служебного потока и потока обработки событий является непростой задачей. Пользователь может продолжать набирать текст или работать с мышью, активизируя тем самым поток обработки событий, в то время как служебный поток будет все еще занят. При возникновении подобного конфликта PageMaker фильтрует сообщения и воспринимает только основные из них, такие, как запрос на изменение размера окна.
О завершении выполнения задания свидетельствует сообщение, поступающее из служебного потока. Пока это сообщение не будет получено, возможности пользователя в программе PageMaker ограничены. Об этом свидетельствует отключение пунктов меню и специальный вид курсора. Пользователь может активизировать окна других приложений; когда курсор перемещается в другое окно, он приобретает вид, соответствующий приложению этого окна.
Для обновления экрана используется отдельный поток, что вызвано следующими причинами.
- В программе PageMaker количество объектов на странице не ограничено, и поэтому обработка запроса на обновление экрана может оказаться весьма длительной.
- Использование отдельного потока позволяет пользователю в любой момент остановить вывод изображения на экран. При такой методике, например, может немедленно выполняться команда изменения масштаба. Если бы программа должна была сначала закончить вывод страницы в старом масштабе, а затем полностью вывести ее в новом масштабе, это резко увеличило бы время ее отклика.
Возможна также динамическая прокрутка, т.е. обновление экрана при перетаскивании пользователем ползунка прокрутки. Поток обработки событий отслеживает положение ползунка и перерисовывает размещенные вдоль полей линейки (которые перерисовываются очень быстро, позволяя пользователю сориентироваться в текущем положении документа). В это время поток обновления экрана постоянно пытается перерисовать смещающуюся страницу, отслеживая изменение ее положения.
Реализация динамического обновления экрана без использования потоков привела бы к перегрузке приложения, так как ему приходилось бы согласовывать свои действия в разных частях кода с помощью обмена сообщениями. Многопоточность позволяет более естественно реализовать код, в котором предполагается параллельное выполнение различных действий.
Потоки на пользовательском уровне и на уровне ядра
Обычно выделяют две общие категории потоков: потоки на уровне пользователя (user-level threads — ULT) и потоки на уровне ядра (kernel-level threads — KLT). Потоки второго типа в литературе иногда называются потоками, поддерживаемыми ядром, или облегченными процессами.
Потоки на уровне пользователя
В программе, полностью состоящей из ULT-потоков, все действия по управлению потоками выполняются самим приложением; ядро, по сути, и не подозревает о существовании потоков. На рис. 4.6,а проиллюстрирован подход, при котором используются только потоки на уровне пользователя. Чтобы приложение было многопоточным, его следует создавать с применением специальной библиотеки, представляющей собой пакет программ для работы с потоками на уровне ядра. Такая библиотека для работы с потоками содержит код, с помощью которого можно создавать и удалять потоки, производить обмен сообщениями и данными между потоками, планировать их выполнение, а также сохранять и восстанавливать их контекст.
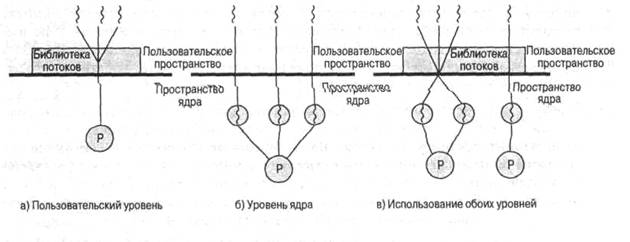
Рис. 4.6. Потоки на пользовательском уровне и на уровне ядра
По умолчанию приложение в начале своей работы состоит из одного потока и его выполнение начинается как выполнение этого потока. Такое приложение вместе с составляющим его потоком размещается в едином процессе, который управляется ядром. Выполняющееся приложение в любой момент времени может породить новый поток, который будет выполняться в пределах того же процесса. Новый поток создается с помощью вызова специальной подпрограммы из библиотеки, предназначенной для работы с потоками. Управление к этой подпрограмме переходит в результате вызова процедуры. Библиотека потоков создает структуру данных для нового потока, а потом передает управление одному из готовых к выполнению потоков данного процесса, руководствуясь некоторым алгоритмом планирования. Когда управление переходит к библиотечной подпрограмме, контекст текущего потока сохраняется, а когда управление возвращается к потоку, его контекст восстанавливается. Этот контекст в основном состоит из содержимого пользовательских регистров, счетчика команд и указателей стека.
Все описанные в предыдущих абзацах события происходят в пользовательском пространстве в рамках одного процесса. Ядро не подозревает об этой деятельности. Оно продолжает осуществлять планирование процесса как единого целого и приписывать ему единое состояние выполнения (состояние готовности, состояние выполняющегося процесса, состояние блокировки и т.д.). Приведенные ниже примеры должны прояснить взаимосвязь между планированием потоков и планированием процессов. Предположим, что выполняется поток 2, входящий в процесс В (см. рис. 4.7). Состояния этого процесса и составляющих его потоков на пользовательском уровне показаны на рис. 4.7,а. Впоследствии может произойти одно из следующих событий.
- Приложение, в котором выполняется поток 2, может произвести системный вызов, например запрос ввода-вывода, который блокирует процесс В. В результате этого вызова управление перейдет к ядру. Ядро вызывает процедуру ввода-вывода, переводит процесс В в состояние блокировки и передает управление другому процессу. Тем временем поток 2 процесса В все еще находится в состоянии выполнения в соответствии со структурой данных, поддерживаемой библиотекой потоков. Важно отметить, что поток 2 не выполняется в том смысле, что он работает с процессором; однако библиотека потоков воспринимает его как выполняющийся. Соответствующие диаграммы состояний показаны на рис. 4.7,6.
- В результате прерывания по таймеру управление может перейти к ядру; ядро определяет, что интервал времени, отведенный выполняющемуся в данный момент процессу В, истек. Ядро переводит процесс В в состояние готовности и передает управление другому процессу. В это время, согласно структуре данных, которая поддерживается библиотекой потоков, поток 2 процесса В по-прежнему будет находиться в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,в.
- Поток 2 достигает точки выполнения, когда ему требуется, чтобы поток 1 процесса В выполнил некоторое действие. Он переходит в заблокированное состояние, а поток 1 — из состояния готовности в состояние выполнения. Сам процесс остается в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,г.
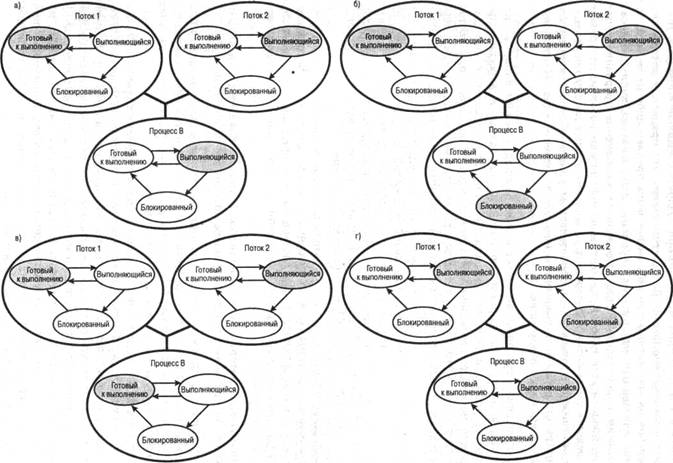
Рис. 4.7. Примеры взаимосвязей между состояниями потоков пользовательского уровня и состояниями процесса
В случаях 1 и 2 (см. рис. 4.7,6 и в) при возврате управления процессу В возобновляется выполнение потока 2. Заметим также, что процесс, в котором выполняется код из библиотеки потоков, может быть прерван либо из-за того, что закончится отведенный ему интервал времени, либо из-за наличия процесса с более высоким приоритетом. Когда возобновится выполнение прерванного процесса, оно продолжится работой процедуры из библиотеки потоков, которая завершит переключение потоков и передаст управление новому потоку процесса.
Использование потоков на пользовательском уровне обладает некоторыми преимуществами перед использованием потоков на уровне ядра. К этим преимуществам относятся следующие:
- Переключение потоков не включает в себя переход в режим ядра, так как структуры данных по управлению потоками находятся в адресном пространстве одного и того же процесса. Поэтому для управления потоками процессу не нужно переключаться в режим ядра. Благодаря этому обстоятельству удается избежать накладных расходов, связанных с двумя переключениями режимов (пользовательского режима в режим ядра и обратно).
- Планирование производится в зависимости от специфики приложения. Для одних приложений может лучше подойти простой алгоритм планирования по круговому алгоритму, а для других — алгоритм планирования, основанный на использовании приоритета. Алгоритм планирования может подбираться для конкретного приложения, причем это не повлияет на алгоритм планирования, заложенный в операционной системе.
- Использование потоков на пользовательском уровне применимо для любой операционной системы. Для их поддержки в ядро системы не потребуется вносить никаких изменений. Библиотека потоков представляет собой набор утилит, работающих на уровне приложения и совместно используемых всеми приложениями.
Использование потоков на пользовательском уровне обладает двумя явными недостатками по сравнению с использованием потоков на уровне ядра.
- В типичной операционной системе многие системные вызовы являются блокирующими. Когда в потоке, работающем на пользовательском уровне, выполняется системный вызов, блокируется не только данный поток, но и все потоки того процесса, к которому он относится.
- В стратегии с наличием потоков только на пользовательском уровне приложение не может воспользоваться преимуществами многопроцессорной системы, так как ядро закрепляет за каждым процессом только один процессор. Поэтому несколько потоков одного и того же процесса не могут выполняться одновременно. В сущности, у нас получается многозадачность на уровне приложения в рамках одного процесса. Несмотря на то, что даже такая многозадачность может привести к значительному увеличению скорости работы приложения, имеются приложения, которые работали бы гораздо лучше, если бы различные части их кода могли выполняться одновременно.
Эти две проблемы разрешимы. Например, их можно преодолеть, если писать приложение не в виде нескольких потоков, а в виде нескольких процессов. Однако при таком подходе основные преимущества потоков сводятся на нет: каждое переключение становится не переключением потоков, а переключением процессов, что приведет к значительно большим накладным затратам.
Другим методом преодоления проблемы блокирования является использование преобразования блокирующего системного вызова в неблокирующий. Например, вместо непосредственного вызова системной процедуры ввода-вывода поток вызывает подпрограмму-оболочку, которая производит ввод-вывод на уровне приложения. В этой программе содержится код, который проверяет, занято ли устройство ввода-вывода. Если оно занято, поток передает управление другому потоку (что происходит с помощью библиотеки потоков). Когда наш поток вновь получает управление, он повторно осуществляет проверку занятости устройства ввода-вывода.
Потоки на уровне ядра
В программе, работа которой полностью основана на потоках, работающих на уровне ядра, все действия по управлению потоками выполняются ядром. В области приложений отсутствует код, предназначенный для управления потоками. Вместо него используется интерфейс прикладного программирования (application programming interface — API) средств ядра, управляющих потоками. Примерами такого подхода являются операционные системы OS/2, Linux и W2K.
На рис. 4.6,6" проиллюстрирована стратегия использования потоков на уровне ядра. Любое приложение при этом можно запрограммировать как многопоточное; все потоки приложения поддерживаются в рамках единого процесса. Ядро поддерживает информацию контекста процесса как единого целого, а также контекстов каждого отдельного потока процесса. Планирование выполняется ядром исходя из состояния потоков. С помощью такого подхода удается избавиться от двух упомянутых ранее основных недостатков потоков пользовательского уровня. Во-первых, ядро может одновременно осуществлять планирование работы нескольких потоков одного и того же процесса на нескольких процессорах. Во-вторых, при блокировке одного из потоков процесса ядро может выбрать для выполнения другой поток этого же процесса. Еще одним преимуществом такого подхода является то, что сами процедуры ядра могут быть многопоточными.
Основным недостатком подхода с использованием потоков на уровне ядра по сравнению с использованием потоков на пользовательском уровне является то, что для передачи управления от одного потока другому в рамках одного и того же процесса приходится переключаться в режим ядра. Результаты исследований, проведенных на однопроцессорной машине VAX под управлением UNIX-подобной операционной системы, представленные в табл. 4.1, иллюстрируют различие между этими двумя подходами. Сравнивалось время выполнения таких двух задач, как (1) нулевое ветвление (Null Fork) — время, затраченное на создание, планирование и выполнение процесса/потока, состоящего только из нулевой процедуры (измеряются только накладные расходы, связанные с ветвлением процесса/потока), и (2) ожидание сигнала (Signal-Wait) — время, затраченное на передачу сигнала от одного процесса/потока другому процессу/потоку, находящемуся в состоянии ожидания (накладные расходы на синхронизацию двух процессов/потоков). Чтобы было легче сравнивать полученные значения, заметим, что вызов процедуры на машине VAX, используемой в этом исследовании, длится 7 us, а системное прерывание — 17 us. Мы видим, что различие во времени выполнения потоков на уровне ядра и потоков на пользовательском уровне более чем на порядок превосходит по величине различие во времени выполнения потоков на уровне ядра и процессов.
Таблица 4.1. Время задержек потоков (ка) [ANDE92]

Таким образом, создается впечатление, что как применение многопоточности на уровне ядра дает выигрыш по сравнению с процессами, так и многопоточность на пользовательском уровне дает выигрыш по сравнению с многопоточностью на пользовательском уровне. Однако на деле возможность этого дополнительного выигрыша зависит от характера приложений. Если для большинства переключений потоков приложения необходим доступ к ядру, то схема с потоками на пользовательском уровне может работать не намного лучше, чем схема с потоками на уровне ядра.
Комбинированные подходы
В некоторых операционных системах применяется комбинирование потоков обоих видов (рис. 4.6,в). Ярким примером такого подхода может служить операционная система Solaris. В комбинированных системах создание потоков выполняется в пользовательском пространстве, там же, где и код планирования и синхронизации потоков в приложениях. Несколько потоков на пользовательском уровне, входящих в состав приложения, отображаются в такое же или меньшее число потоков на уровне ядра. Программист может изменять число потоков на уровне ядра, подбирая его таким, которое позволяет достичь наилучших результатов.
При комбинированном подходе несколько потоков одного и того же приложения могут выполняться одновременно на нескольких процессорах, а блокирующие системные вызовы не приводят к блокировке всего процесса. При надлежащей реализации такой подход будет сочетать в себе преимущества подходов, в которых применяются только потоки на пользовательском уровне или только потоки на уровне ядра, сводя недостатки каждого из этих подходов к минимуму.
Другие схемы
Как уже упоминалось, понятия единицы распределения ресурсов и планирования традиционно отождествляются с понятием процесса. В такой концепции поддерживается однозначное соответствие между потоками и процессами. В последнее время наблюдается интерес к использованию нескольких потоков в одном процессе, когда выполняется соотношение многие-к-одному. Однако возможны и другие комбинации, а именно соответствие нескольких потоков нескольким процессам и соответствие одного потока нескольким процессам. Примеры применения каждой из упомянутых комбинаций приводятся в табл. 4.2.
Таблица 4.2. Соотношение между потоками и процессами

Соответствие нескольких потоков нескольким процессам
Идея реализации соответствия нескольких процессов нескольким потокам была исследована в экспериментальной операционной системе TRIX [SIEB83, WARD80]. В данной операционной системе используются понятия домена и потока. Домен — это статический объект, состоящий из адресного пространства и портов, через которые можно отправлять и получать сообщения. Поток — это единая выполняемая ветвь, обладающая стеком выполнения и характеризующаяся состоянием процессора, а также информацией по планированию.
Как и в других указанных ранее многопоточных подходах, в рамках одного домена могут выполняться несколько потоков. При этом удается получить уже описанное повышение эффективности работы. Кроме того, имеется возможность осуществлять деятельность одного и того же пользователя или приложения в нескольких доменах. В этом случае имеется поток, который может переходить из одного домена в другой.
По-видимому, использование одного и того же потока в разных доменах продиктовано желанием предоставить программисту средства структурирования. Например, рассмотрим программу, в которой используется подпрограмма ввода-вывода. В многозадачной среде, в которой пользователю позволено создавать процессы, основная программа может сгенерировать новый процесс для управления вводом-выводом, а затем продолжить свою работу. Однако если для дальнейшего выполнения основной программы необходимы результаты операции ввода-вывода, то она должна ждать, пока не закончится работа подпрограммы ввода-вывода. Подобное приложение можно осуществить такими способами.
- Реализовать всю программу в виде единого процесса. Такой прямолинейный подход является вполне обоснованным. Недостатки этого подхода связаны с управлением памятью. Эффективно организованный как единое целое процесс может занимать в памяти много места, в то время как для подпрограммы ввода-вывода требуется относительно небольшое адресное пространство. Из-за того что подпрограмма ввода-вывода выполняется в адресном пространстве более объемной программы, во время выполнения ввода-вывода весь процесс должен оставаться в основной памяти, либо операция ввода-вывода будет выполняться с применением свопинга. То же происходит и в случае, когда и основная программа, и подпрограмма ввода-вывода реализованы в виде двух потоков в одном адресном пространстве.
- Основная программа и подпрограмма ввода-вывода реализуются в виде двух отдельных процессов. Это приводит к накладным затратам, возникающим в результате создания подчиненного процесса. Если ввод-вывод производится достаточно часто, то необходимо будет либо оставить такой подчиненный процесс активным на все время работы основного процесса, что связано с затратами на управление ресурсами, либо часто создавать и завершать процесс с подпрограммой, что приведет к снижению эффективности.
- Реализовать действия основной программы и подпрограммы ввода-вывода как единый поток. Однако для основной программы следует создать свое адресное пространство (свой домен), а для подпрограммы ввода-вывода — свое. Таким образом, поток в ходе выполнения программы будет переходить из одного адресного пространства к другому. Операционная система может управлять этими двумя адресными пространствами независимо, не затрачивая никаких дополнительных ресурсов на создание процесса. Более того, адресное пространство, используемое подпрограммой ввода-вывода, может использоваться совместно с другими простыми подпрограммами ввода-вывода.
Опыт разработчиков операционной системы TRIX свидетельствует о том, что третий вариант заслуживает внимания и для некоторых приложений может оказаться самым эффективным.
Соответствие одного потока нескольким процессам
В области распределенных операционных систем (разрабатываемых для управления распределенными компьютерными системами) представляет интерес концепция потока как основного элемента, способного переходить из одного адресного пространства в другое. Заслуживают упоминания операционная система Clouds и, в особенности, ее ядро, известное под названием Ra [DASG92]. В качестве другого примера можно привести систему Emerald [STEE95].
В операционной системе Clouds поток является единицей активности с точки зрения пользователя. Процесс имеет вид виртуального адресного пространства с относящимся к нему управляющим блоком. После создания поток начинает выполнение в рамках процесса. Потоки могут переходить из одного адресного пространства в другое и даже выходить за рамки машины (т.е. переходить из одного компьютера в другой). При переходе потока в другое место он должен нести с собой определенную информацию — такую, как управляющий терминал, глобальные параметры и сведения по его планированию (например, приоритет).
Подход, применяющийся в операционной системе Clouds, является эффективным способом изоляции пользователя и программиста от деталей распределенной среды. Деятельность пользователя может ограничиваться одним потоком, а перемещение этого потока из одной машины в другую может быть обусловлено функционированием операционной системы, руководствующейся такими обстоятельствами, как необходимость доступа к удаленным ресурсам или выравнивание загрузки машин.
