ПРИЛОЖЕНИЕ А. ХАРАКТЕРИСТИКИ ПРОИЗВОДИТЕЛЬНОСТИ ДВУХУРОВНЕВОЙ ПАМЯТИ
В данной главе упоминался кэш, который выступает в роли промежуточного буфера между процессором и основной памятью, что обеспечивает двухуровневую структуру памяти. Производительность работы памяти с такой архитектурой выше, чем у одноуровневой памяти. Это повышение производительности достигается за счет свойства, известного как локализация, которое и рассматривается в данном приложении.
Механизм кэширования основной памяти является составной частью компьютерной архитектуры. Он встроен в аппаратное обеспечение и обычно невидим операционной системе. В силу этого кэширование не рассматривается в данной книге. Однако есть еще два примера использования двухуровневой памяти, в которых также используется локализация и которые, по крайней мере частично, управляются операционной системой: виртуальная память и дисковый кэш (см. табл. 1.2). Эти темы являются предметом рассмотрения глав 8, "Виртуальная память", и 11, "Управление вводом-выводом и дисковое планирование", соответственно. Данное приложение поможет читателю познакомиться с некоторыми характеристиками производительности двухуровневой памяти, которые являются общими для всех трех подходов.
Таблица 1.2. Характеристики двухуровневой памяти

Локализация
Основой для повышения производительности двухуровневой памяти является принцип локализации, о котором шла речь в разделе 1.5. Основной постулат состоит в том, что последовательные обращения к памяти имеют тенденцию собираться в группы (кластеры). По истечении длительного периода времени один кластер сменяется другим, но на протяжении сравнительно небольших промежутков времени процессор преимущественно работает с адресами, входящими в один и тот же кластер памяти.
Принцип локализации подтверждается на практике. Рассмотрим следующую цепочку рассуждений.
Команды программы выполняются последовательно, за исключением тех случаев, когда встречаются команды ветвления или вызова (процедуры, функции и т.д.). Поэтому в большинстве случаев команды из памяти извлекаются последовательно, одна за другой в порядке их размещения.
- Длинная, не нарушаемая прерываниями последовательность вызовов процедур, за которой идут соответствующие команды возврата, встречается довольно редко. Другими словами, глубина вложенного вызова процедур остается небольшой. Поэтому в течение короткого промежутка времени обращения, скорее всего, происходят к командам, которые находятся в небольшом числе процедур.
- Большинство итерационных конструкций состоят из сравнительно небольшого числа многократно повторяющихся команд. Во время выполнения этих итераций вычисления сосредоточены на небольшом локализованном участке программы.
- Во многих программах значительная часть вычислений приходится на операции с такими структурами данных, как массивы и последовательности записей. В большинстве случаев данные, к которым происходит обращение, расположены близко друг к другу.
Приведенные рассуждения подтверждаются многими исследованиями. Для проверки утверждения 1 проводился разносторонний анализ поведения программ, составленных на языках высокого уровня. Результаты измерений частоты появления различных команд при выполнении программы, проведенные разными исследователями, представлены в табл. 1.3. Одно из самых ранних исследований поведения языка программирования проводилось Кнутом [KNUT71], рассматривавшим различные программы на языке FORTRAN, написанные студентами при выполнении практических заданий. Таненбаум [TANE78] опубликовал результаты измерений, проведенные более чем на 300 процедурах, которые использовались при разработке операционных систем и были написаны на языке, поддерживающем структурное программирование. Паттерсон и Секвин [РАТТ82] провели анализ ряда измерений, выполненных над компиляторами, текстовыми редакторами, системами автоматизированного проектирования, программами сортировки данных и сравнения содержимого файлов (языки программирования С и Pascal). Хак [HUCK83] проанализировал четыре программы, являющиеся типичными примерами программ для проведения научных вычислений. Среди них были, в частности, программы для выполнения быстрого Фурье-преобразования и для решения системы дифференциальных уравнений. Полученные результаты хорошо согласуются с утверждением, что ветвления и команды вызовов представляют собой лишь небольшую часть всех команд, выполняющихся во время работы программы. Таким образом, проведенные исследования подтверждают справедливость приведенного выше утверждения 1.
Исследование |
[HUCK83] |
[KNUT71] |
[РАТТ82] |
[TANE78] |
Язык |
Pascal |
FORTRAN |
Pascal |
С |
SAL |
Изучаемый материал |
Научное ПО |
Студен-ческие работы |
Систем-ное ПО |
Систем-ное ПО |
Систем-ное ПО |
Присвоение |
74 |
67 |
45 |
38 |
42 |
Цикл |
4 |
3 |
5 |
3 |
4 |
Вызов |
1 |
3 |
15 |
12 |
12 |
IF |
20 |
11 |
29 |
43 |
36 |
GOTO |
2 |
9 |
- |
3 |
- |
Другие |
- |
7 |
6 |
1 |
6 |
Что касается утверждения 2, то его справедливость подтверждается исследованиями, результаты которых изложены в [РАТТ85]. Это проиллюстрировано на рис. 1.20, где показано поведение программы в разрезе используемых в ней вызовов процедур и возврата из них. Каждый вызов представлен отрезком линии, идущим на одно деление вниз, а каждый возврат — отрезком, идущим на одно деление вверх. Весь график заключен в коридор шириной 5 делений. Этот коридор является подвижным, но сдвигается лишь в результате 6 последовательных команд вызова или возврата. Из графика видно, что программа во время своей работы может оставаться в стационарном коридоре на протяжении достаточно длительного периода времени. Изучение программ, написанных на С или Pascal, показало, что при расширении коридора до 8 делений он сдвигается меньше, чем при 1% вызовов или возвратов [TAMI83].
Принцип локализации обращений подтверждается и более поздними исследованиями. Например, на рис. 1.21 показаны результаты исследований, при которых измерялась частота доступа к Web-страницам отдельно взятого узла.
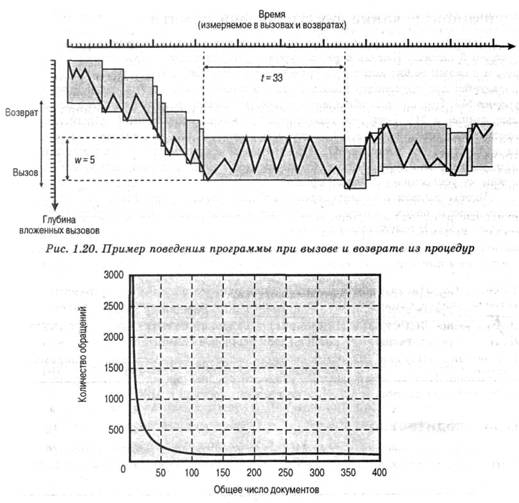
Рис. 1.21. Локализация при обращении к Web-страницам [BAEN97]
В литературе различают пространственную и временную локализации. Пространственная локализация означает преимущественное обращение к некоторому количеству сгруппированных ячеек памяти. Это свойство отражает тенденцию процессора исполнять команды последовательно. Пространственная локализация свидетельствует также о склонности программы обращаться к данным, которые находятся в последовательных ячейках, как, например, при обработке данных, собранных в таблицу. Временная локализация отражает тенденцию процессора обращаться к ячейкам памяти, к которым недавно уже производился доступ. Например, при выполнении цикла итераций процессор многократно повторяет исполнение одного и того же набора команд.
Функционирование двухуровневой памяти
Принцип локализации может быть использован для разработки схемы двухуровневой памяти. Память верхнего уровня (Ml) имеет меньшую емкость, она быстрее, и каждый ее бит дороже по сравнению с памятью нижнего уровня (М2). Ml используется для временного хранения определенной части содержимого более емкого уровня М2. При каждом обращении к памяти сначала делается попытка найти нужные данные в Ml. Если она завершается успехом, происходит быстрый доступ. В противном случае, из М2 в Ml копируется нужный блок ячеек памяти, а затем снова осуществляется доступ к Ml. В соответствии с принципами локализации к ячейкам памяти вновь перенесенного блока произойдет еще ряд обращений, что приведет к общему ускорению работы программы.
Чтобы выразить среднее время доступа, нужно учитывать не только скорость работы обоих уровней памяти, но и вероятность обнаружения требуемых данных в Ml. В результате получим
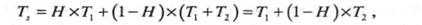 (1.1)
(1.1)
где
Та — среднее (системное) время доступа,
Т1! — время доступа к Ml (например, кэшу, дисковому кэшу),
Т2 — время доступа к М2 (например, основной памяти, диску),
Н — результативность поиска (доля ссылок на данные в Ml).
На рис. 1.15 показано среднее время доступа как функция результативности поиска. При высокой результативности среднее время доступа намного ближе ко времени доступа к Ml, чем ко времени доступа к М2.
Производительность
Рассмотрим некоторые параметры, характеризующие механизм двухуровневой памяти. Сначала рассмотрим стоимость, которая выражается следующим образом:
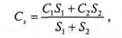 (1.2)
(1.2)
где
Cs — средняя стоимость одного бита двухуровневой памяти,
C1 — средняя стоимость одного бита памяти верхнего уровня Ml,
С2 — средняя стоимость одного бита памяти нижнего уровня М2,
S1 — емкость Ml,
S2 — емкость М2.
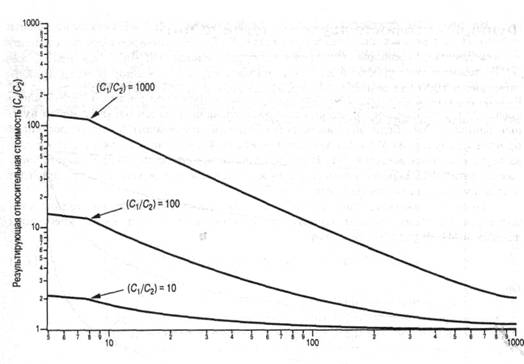
Желательно добиться соотношения Cs ~С2. При условии С, » С для этого требуется, чтобы выполнялось условие S1 = S2. Получающаяся зависимость представлена на рис. 1.221
Относительная емкость двух уровней (S2/S1)
Рис. 1.22. Зависимость средней стоимости двухуровневой памяти от относительной емкости уровней
Теперь рассмотрим время доступа. Для высокой производительности двухуровневой памяти необходимо, чтобы Ts ? T, Поскольку обычно T1 < T2, нужно, чтобы результативность поиска была близка к 1.
Таким образом, мы хотим, чтобы уровень Ml обладал малой емкостью (что позволило бы снизить стоимость), но был достаточно большим для того, чтобы повысить результативность поиска и, как следствие, производительность. Можно ли так подобрать размер Ml, чтобы в определенной степени он удовлетворял обоим требованиям? Этот вопрос можно разбить на несколько подвопросов.
1Обратите внимание, что для обеих осей выбрана логарифмическая шкала. Обзор основных сведений по логарифмическим шкалам приведен в сборнике документов для повторения математики, который находится на узле Computer Science Student Support (WilliamStallings.com/StudentSupport.html).
Какая результативность поиска удовлетворяет требованиям производительности?
Какая емкость Ml даст гарантию достижения требуемой результативности поиска?
Будет ли эта емкость иметь приемлемую стоимость?
Чтобы ответить на эти вопросы, рассмотрим, величину T1/T2, которая называется эффективностью доступа. Она является мерой того, насколько среднее время доступа Т, отличается от времени доступа T1 к Ml. Из уравнения (1.1) находим
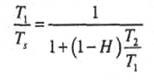 (1.8)
(1.8)
На рис. 1.23 представлен график зависимости TJTS от результативности поиска Н при разных значениях параметра 7"2/7| . Обычно время доступа к кэшу в пять-десять раз меньше, чем время доступа к основной памяти (т.е. отношение Т2/Тх лежит в пределах от 5 до 10), а время доступа к основной памяти приблизительно в 1000 раз меньше, чем время доступа к диску (Т2/Тх -1000). Таким образом, чтобы удовлетворить требованиям эффективности, величина результативности поиска должна находится в пределах от 0.8 до 0.9.
Результативность поиска Н
Рис. 1.23. Эффективность доступа в зависимости от результативности поиска
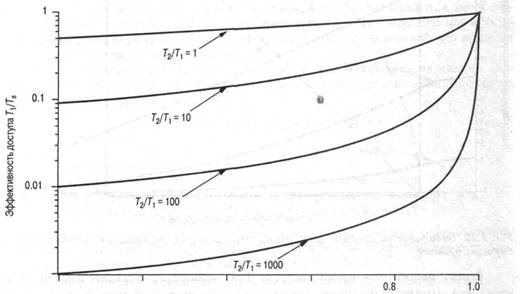
Теперь вопрос об относительной емкости памяти можно сформулировать более точно. Можно ли при условии S, = S2 добиться, чтобы результативность поиска достигала значения 0.8 или превышала его? Это зависит от нескольких факторов, в число которых входит вид используемого программного обеспечения и детали устройства двухуровневой памяти. Основное влияние, конечно, оказывает степень локализации. На рис. 1.24 показано, какое влияние оказывает локализация на результативность поиска. Очевидно, что если емкость уровня Ml равна емкости уровня М2, то результативность поиска будет 1.0, поскольку все содержимое М2 находится в Ml. Теперь предположим, что нет никакой локализации, т.е. все обращения происходят в случайном порядке. В этом случае результативность поиска линейно зависит от относительного размера памяти. Например, если объем Ml равен половине объема М2, то в любой момент времени на уровне Ml находится ровно половина всех данных уровня М2, и результативность поиска равна 0.5. Однако на практике проявляется эффект локализации обращений. На графике показано влияние локализации средней и сильной степени.
Относительный размер памяти S^/S2
Рис. 1.24. Результативность поиска в зависимости от относительного размера памяти
Таким образом, сильная локализация позволяет достичь высокой результативности поиска даже при сравнительно небольших объемах памяти верхнего уровня. Например, многочисленные исследования подтверждают, что при сравнительно небольшом размере кэша результативность поиска превышает 0.75, причем этот показатель не зависит от размера основной памяти (см., например, [AGAR89], [PRZY88], [STRE83] и [SMIT82]). В то время как типичный размер основной памяти в наши дни составляет многие мегабайты, вполне достаточным является кэш, емкость которого лежит в пределах от 1 до 128 Кбайт. При рассмотрении виртуальной памяти и дискового кэша можно сослаться на другие исследования, подтверждающие справедливость такого же утверждения, а именно — благодаря локализации относительно малый размер Ml обеспечивает высокую результативность поиска.
Теперь можно перейти к последнему из перечисленных ранее вопросов: удовлетворяет ли относительный размер двух уровней памяти требованиям стоимости? Ответ очевиден: да. Если для повышения производительности достаточно добавить верхний уровень сравнительно небольшой емкости, то средняя стоимость обоих уровней в расчете на один бит будет лишь немного превосходить стоимость бита более дешевой памяти второго уровня.
ПРИЛОЖЕНИЕ Б. УПРАВЛЕНИЕ ПРОЦЕДУРАМИ
Общепринятым методом осуществления управления вызовами процедур и возвратами из них является использование стека. В данном приложении приводится краткое описание свойств стека и его использования при работе процедур.
Реализация стека
Стек — это упорядоченный набор элементов, причем при обращении к нему можно получить доступ лишь к одному из элементов. Этот элемент называется вершиной стека. Число элементов стека (его длина) является переменным. Добавления или удаления можно делать только на вершине стека, поэтому его называют магазинным списком, или списком, организованным по принципу "последним вошел — первым вышел" (last-in-first-out — LIFO).
Для реализации стека необходим набор ячеек памяти, в которые будут заноситься его элементы. Типичный подход проиллюстрирован на рис. 1.25. В основной (или виртуальной) памяти для стека резервируется блок смежных ячеек. Большую часть времени он частично заполнен элементами стека. Для обеспечения нормальной работы нужно помнить следующие адреса, которые хранятся в регистрах процессора.
Указатель стека. Содержит адрес вершины стека. Если в стек добавляется новый элемент (PUSH) или из него удаляется элемент (POP), указатель соответственно увеличивается или уменьшается на единицу. После этого он вновь содержит адрес вершины стека.
База стека. Содержит адрес нижней ячейки зарезервированного блока. При добавлении элемента в пустой стек эта ячейка используется первой. При попытке извлечь элемент из пустого стека генерируется сигнал ошибки.
Предел стека. Содержит адрес второго конца, т.е. вершины зарезервированного блока. При попытке добавить новый элемент в заполненный стек генерируется сигнал ошибки.
Традиционно сложилось так, что у большинства современных машин основой стека является ячейка с максимальным адресом, а его пределом — ячейка с минимальным адресом. Таким образом, стек является обращенным, и при его возрастании заполняются ячейки с убывающими адресами.
Вызов процедуры и возврат из нее
Общепринятым методом управления вызовами процедур и возвратами из них является использование стека. При обработке вызова процессор помещает в стек адрес возврата. При возврате из процедуры процессор использует адрес с вершины стека. На рис. 1.26 и 1.27 показано использование стека при работе с вложенными процедурами.
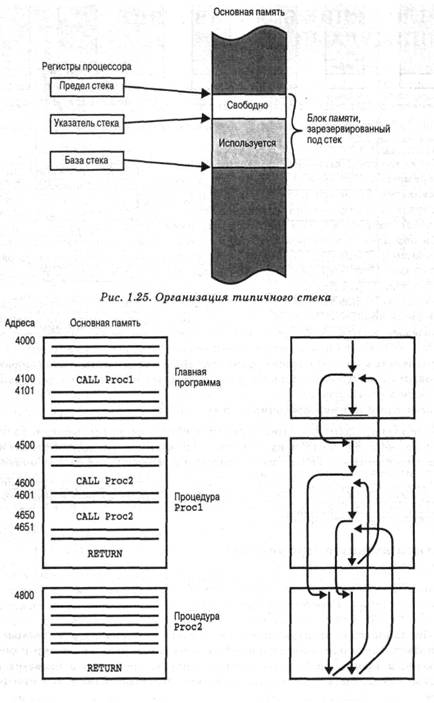
а) Вызовы и возвраты б) Последовательность исполнения
Рис. 1.26. Вложенные процедуры
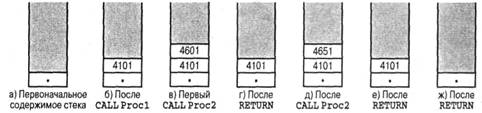
Рис. 1.27. Использование стека при обработке вложенных процедур, показанных на рис. 1.26
Часто вместе с вызовом процедуры бывает необходимо передать ей некоторые параметры. Это можно сделать при помощи регистров; другой возможностью является хранение параметров в памяти сразу после команды вызова. В этом случае возврат должен осуществляться к ячейке памяти, расположенной сразу после параметров. Оба этих подхода имеют свои недостатки. При использовании передачи параметров в регистрах необходимо согласование вызывающей и вызываемой процедур, гарантирующее одинаковое распределение параметров по регистрам. При сохранении параметров в памяти усложняется передача переменного числа параметров.
Большую гибкость при передаче параметров обеспечивает стек. При обработке вызова процессор заносит в стек не только адрес возврата, но и параметры, передаваемые вызываемой процедуре, которая легко может получить доступ к ним. При возврате из процедуры возвращаемые значения также можно занести в стек, располагая их под адресом возврата. Набор всех параметров (включая адрес возврата), который сохраняется при обращении к процедуре, называется кадром стека (stack frame).
Рассмотрим пример программы, в которой используются процедуры Р и Q. В процедуре Р объявлены локальные переменные xl и х2, а в Q — локальные переменные j/1 и у2. Процедура Q может быть вызвана из Р. Схема работы стека при выполнении такой программы показана на рис. 1.28. На этом рисунке точка возврата из каждой процедуры является первой ячейкой соответствующего стекового кадра. Следующим сохраняется указатель на начало предыдущего кадра. Это необходимо на случай, если количество или размер заносимых в стек параметров являются переменными.
Реентерабельные процедуры
Реентерабельная (повторно вводимая) процедура является весьма полезной концепцией, особенно успешно применяемой в многопользовательских и многозадачных системах. Реентерабельной называется процедура, последовательность команд которой может одновременно использоваться несколькими пользователями. Это свойство процедуры имеет два основных аспекта: программный код не должен быть самомодифицирующимся, а локальные данные каждого пользователя должны храниться отдельно друг от друга. Исполнение реентерабельной процедуры может быть приостановлено с помощью прерывания, а после возврата из него — корректно продолжиться. В многопользовательских и многозадачных системах реентерабельность позволяет более эффективно использовать основную память: в ней хранится только одна копия программного кода процедуры, даже если к ней обращаются несколько разных приложений.
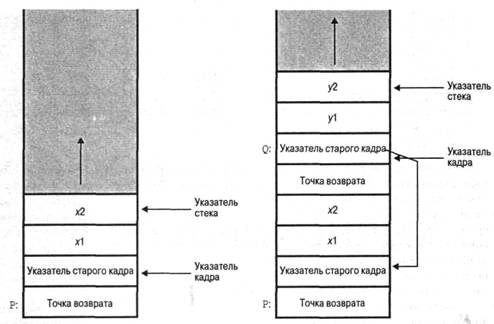
а) Активная процедура Р б) Вызов Q из Р
Рис. 1.28. Увеличение стекового кадра при вызове процедур Р и Q
Таким образом, в реентерабельной процедуре должна быть неизменная часть (команды, из которых состоит процедура) и переменная часть (указатель на вызывающую программу, а также локальная область памяти, в которой хранятся локальные переменные, используемые данной программой). При каждом запуске процедуры, который называется ее активацией, исполняется код неизменной части, но при этом должна быть создана отдельная копия локальных переменных и параметров. Переменную часть, связанную с каждой активацией, называют записью активации.
Реентерабельные процедуры удобнее всего реализовывать с помощью стека: при вызове процедуры соответствующая запись активации заносится в стек. Таким образом, запись активации становится частью стекового кадра, создаваемого при вызове процедуры.
