Идея введения структурного типа в любой язык программирования состоит в объединении разнотипных переменных в один объект.
В языке должны быть средства доступа к этим переменным внутри конкретного экземпляра структуры. Для того чтобы сослаться в команде на поле некоторой структуры, используется специальный оператор — символ "." (точка). Он используется в следующей синтаксической конструкции:
| адресное_выражение.имя_поля_структуры |
Здесь:
- адресное_выражение — идентификатор переменной некоторого структурного типа или выражение в скобках в соответствии с указанными ниже синтаксическими правилами (рис. 1);
- имя_поля_структуры — имя поля из шаблона структуры.
- Это, на самом деле, тоже адрес, а точнее, смещение поля от начала структуры.
Таким образом оператор "." (точка) вычисляет выражение
| (адресное_выражение) + (имя_поля_структуры) |
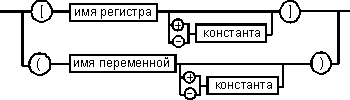
Рис. 5. Синтаксис адресного выражения в операторе обращения к полю структуры
Продемонстрируем на примере определенной нами структуры worker некоторые приемы работы со структурами.
К примеру, извлечь в ax значения поля с возрастом. Так как вряд ли возраст трудоспособного человека будет больше величины 99 лет, то после помещения содержимого этого символьного поля в регистр ax его будет удобно преобразовать в двоичное представление командой aad.
Будьте внимательны, так как из-за принципа хранения данных “младший байт по младшему адресу” старшая цифра возраста будет помещена в al, а младшая — в ah.
Для корректировки достаточно использовать команду xchg al,ah:
| mov ax,word ptr sotr1.age ;в al возраст sotr1 xchg ah,al |
а можно и так:
| lea bx,sotr1 mov ax,word ptr [bx].age xchg ah,al |
Давайте представим, что сотрудников не четверо, а намного больше, и к тому же их число и информация о них постоянно меняются. В этом случае теряется смысл явного определения переменных с типом worker для конкретных личностей.
Язык ассемблера разрешает определять не только отдельную переменную с типом структуры, но и массив структур.
К примеру, определим массив из 10 структур типа worker:
| mas_sotr worker 10 dup (<>) |
Дальнейшая работа с массивом структур производится так же, как и с одномерным массивом. Здесь возникает несколько вопросов:
Как быть с размером и как организовать индексацию элементов массива?
Аналогично другим идентификаторам, определенным в программе, транслятор назначает имени типа структуры и имени переменной с типом структуры атрибут типа. Значением этого атрибута является размер в байтах, занимаемый полями этой структуры. Извлечь это значение можно с помощью оператор type.
После того как стал известен размер экземпляра структуры, организовать индексацию в массиве структур не представляет особой сложности.
К примеру:
| worker struc...worker ends...mas_sotr worker 10 dup (<>)... mov bx,type worker ;bx=77 lea di,mas_sotr;извлечь и вывести на экран пол всех сотрудников: mov cx,10cycl: mov al,[di].sex...;вывод на экран содержимого поля sex структуры worker add di,bx ;к следующей структуре в массиве mas_sort loop cycl |
Как выполнить копирование поля из одной структуры в соответствующее поле другой структуры? Или как выполнить копирование всей структуры? Давайте выполним копирование поля nam третьего сотрудника в поле nam пятого сотрудника:
| worker struc...worker ends...mas_sotr worker 10 dup (<>)... mov bx,offset mas_sotr mov si,(type worker)*2 ;si=77*2 add si,bx mov di,(type worker)*4 ;si=77*4 add di,bx mov cx,30rep movsb |
Мне кажется, что ремесло программиста рано или поздно делает человека похожим на хорошую домохозяйку. Он, подобно ей, постоянно находится в поиске, где бы чего-нибудь сэкономить, урезать и из минимума продуктов сделать прекрасный обед. И если это удается, то и моральное удовлетворение получается ничуть не меньше, а может и больше, чем от прекрасного обеда у домохозяйки. Степень этого удовлетворения, как мне кажется, зависит от степени любви к своей профессии.
С другой стороны, успехи в разработке программного и аппаратного обеспечения несколько расслабляют программиста, и довольно часто наблюдается ситуация, похожая на известную пословицу про муху и слона, - для решения некоторой мелкой задачи привлекаются тяжеловесные средства, эффективность которых, в общем случае, значима только при реализации сравнительно больших проектов.
Наличие в языке следующих двух типов данных, наверное, объясняется стремлением “хозяйки” максимально эффективно использовать рабочую площадь стола (оперативной памяти) при приготовлении еды или для размещения продуктов (данных программы).
Лекция 9. Объединения (1 пара)
Представим ситуацию, когда мы используем некоторую область памяти для размещения некоторого объекта программы (переменной, массива или структуры). Вдруг после некоторого этапа работы у нас отпала надобность в использовании этих данных. Обычно память останется занятой до конца работы программы. Конечно, в принципе, ее можно было бы использовать для хранения других переменных, но при этом без принятия специальных мер нельзя изменить тип и имя. Неплохо было бы иметь возможность переопределить эту область памяти для объекта с другим типом и именем. Язык ассемблера предоставляет такую возможность в виде специального типа данных, называемого объединением.
Объединение — тип данных, позволяющий трактовать одну и ту же область памяти как имеющую разные типы и имена.
Описание объединений в программе напоминает описание структур, то есть сначала описывается шаблон, в котором с помощью директив описания данных перечисляются имена и типы полей:
| имя_объединения UNION <описание полей>имя_объединения ENDS |
Отличие объединений от структур состоит, в частности, в том, что при определении переменной типа объединения память выделяется в соответствии с размером максимального элемента.
Обращение к элементам объединения происходит по их именам, но при этом нужно, конечно, помнить о том, что все поля в объединении накладываются друг на друга.
Одновременная работа с элементами объединения исключена. В качестве элементов объединения можно использовать и структуры.
Листинг 7, который мы сейчас рассмотрим, примечателен тем, что кроме демонстрации использования собственно типа данных “объединение” в нем показывается возможность взаимного вложения структур и объединений.
Постарайтесь внимательно отнестись к анализу этой программы. Основная идея здесь в том, что указатель на память, формируемый программой, может быть представлен в виде:
- 16-битного смещения;
- 32-битного смещения;
- пары из 16-битного смещения и 16-битной сегментной составляющей адреса;
- в виде пары из 32-битного смещения и 16-битного селектора.
Какие из этих указателей можно применять в конкретной ситуации, зависит от режима адресации (use16 или use32) и режима работы микропроцессора.
Так вот, описанный в листинге 7 шаблон объединения позволяет нам облегчить формирование и использование указателей различных типов.
| Листинг 7 Пример использования объединенияmasmmodel smallstack 256.586Ppnt struc ;структура pnt, содержащая вложенное объединениеunion ;описание вложенного в структуру объединенияoffs_16 dw ?offs_32 dd ?ends ;конец описания объединенияsegm dw ?ends ;конец описания структуры.datapoint union ;определение объединения, содержащего вложенную структуруoff_16 dw ?off_32 dd ?point_16 pnt <>point_32 pnt <>point endstst db "Строка для тестирования"adr_data point <> ;определение экземпляра объединения.codemain: mov ax,@data mov ds,ax mov ax,seg tst;записать адрес сегмента строки tst в поле структуры adr_data mov adr_data.point_16.segm,ax;когда понадобится, можно извлечь значение из этого поля обратно, к примеру, в регистр bx: mov bx,adr_data.point_16.segm;формируем смещение в поле структуры adr_data mov ax,offset tst ;смещение строки в ax mov adr_data.point_16.offs_16,ax;аналогично, когда понадобится, можно извлечь значение из этого поля: mov bx,adr_data.point_16.offs_16exit: mov ax,4c00h int 21hend main |
Когда вы будете работать в защищенном режиме микропроцессора и использовать 32-разрядные адреса, то аналогичным способом можете заполнить и использовать описанное выше объединение.
Лекция 10. Записи (1 пара)
Наша “хозяйка-программист” становится все более экономной. Она уже хочет работать с продуктами на молекулярном уровне, без любых отходов и напрасных трат.
Подумаем, зачем тратить под некоторый программный индикатор со значением “включено-выключено” целых восемь разрядов, если вполне хватает одного? А если таких индикаторов несколько, то расход оперативной памяти может стать весьма ощутимым.
Когда мы знакомились с логическими командами, то говорили, что их можно применять для решения подобной проблемы. Но это не совсем эффективно, так как велика вероятность ошибок, особенно при составлении битовых масок.
TASM предоставляет нам специальный тип данных, использование которого помогает решить проблему работы с битами более эффективно. Речь идет о специальном типе данных — записях.
Запись — структурный тип данных, состоящий из фиксированного числа элементов длиной от одного до нескольких бит.
При описании записи для каждого элемента указывается его длина в битах и, что необязательно, некоторое значение.
Суммарный размер записи определяется суммой размеров ее полей и не может быть более 8, 16 или 32 бит.
Если суммарный размер записи меньше указанных значений, то все поля записи “прижимаются” к младшим разрядам.
Использование записей в программе, так же, как и структур, организуется в три этапа:
- Задание шаблона записи, то есть определение набора битовых полей, их длин и, при необходимости, инициализация полей.
- Определение экземпляра записи. Так же, как и для структур, этот этап подразумевает инициализацию конкретной переменной типом заранее определенной с помощью шаблона записи.
- Организация обращения к элементам записи.
Компилятор TASM, кроме стандартных средств обработки записей, поддерживает также и некоторые дополнительные возможности их обработки.
