Доступ к базам данных.
Выше мы обсуждали, зачем Web-программисту требуется обеспечить доступ к базам данных. Далее необходимо выяснить, к каким типам баз данных и какими средствами этот доступ можно обеспечить.
Самыми простыми базами данных изо всех возможных являются плоские текстовые файлы. Для доступа к ним можно использовать средства DHTML либо файловые операции, включенные в состав серверных языков сценариев. Для взаимодействия с популярными настольными базами данных, такими как хорошо известная вам СУБД Microsoft Access, используются свои технологии. Поскольку самыми популярными настольными операционными системами по-прежнему остаются представители семейства Microsoft Windows, средства доступа к настольным СУБД будут рассмотрены в теме, посвященной серверному языку сценариев Active Server Pages (ASP). Самыми же продвинутыми средствами доступа располагают серверы баз данных, такие как MS SQL или MySQL, особенностям которого и посвящена данная тема.
СУБД MySQL.
MySQL является, возможно, самым ярким программным проектом после выхода Linux. Сейчас она серьезный конкурент большим СУБД в области разработки баз данных малого и среднего масштаба. Особыми целями проектирования MySQL были скорость, надежность и простота использования. Чтобы достичь такой производительности, ее разработчик - шведская фирма ТсХ приняла решение сделать многопоточным внутренний механизм MySQL. Многопоточное приложение одновременно выполняет несколько задач - так, как если бы одновременно выполнялось несколько экземпляров приложения.
Сделав MySQL многопоточной, ТсХ дала пользователям много выгод. Каждое входящее соединение обрабатывается отдельным потоком, при этом еще один всегда выполняющийся поток управляет соединениями, поэтому клиентам не приходится ждать завершения выполнения запросов других клиентов. Одновременно может выполняться любое количество запросов. Пока какой-либо поток записывает данные в таблицу, все другие запросы, требующие доступа к этой таблице, просто ждут, пока она освободится. Клиент может выполнять все допустимые операции, не обращая внимания на другие одновременные соединения. Управляющий поток предотвращает одновременную запись какими-либо двумя потоками в одну и ту же таблицу. Такая архитектура более сложна, чем однопоточная. Однако выигрыш в скорости благодаря одновременному выполнению нескольких запросов значительно превосходит потери скорости, вызванные увеличением сложности.
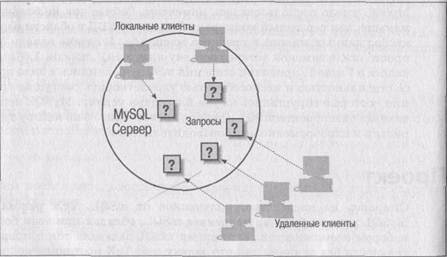
Рис. 3.1. Клиент-серверная архитектура MySQL
Другое преимущество многопоточной обработки присуще всем многопоточным приложениям. Несмотря на то, что потоки совместно используют память процесса, они выполняются раздельно. Благодаря этому разделению выполнение потоков на многопроцессорных машинах может быть распределено по нескольким ЦП. На рис. 3-1 показана эта многопоточная природа сервера MySQL.
Помимо выигрыша в производительности, полученного благодаря многопоточности, MySQL поддерживает большое подмножество языка запросов SQL. MySQL поддерживает более десятка типов данных, а также функции SQL. Ваше приложение может получить доступ к этим функциям через команды ANSI SQL. MySQL фактически расширяет ANSI SQL несколькими новыми возможностями. В их числе новые функции (ENCRYPT, WEEKDAY, IF и другие), возможность инкрементирования полей (AUTO_INCREMENT и LAST_INSERT ID), а также возможность различать верхний и нижний регистры.
ТсХ намеренно опустила некоторые возможности SQL, встречающиеся в больших базах данных. Наиболее заметно отсутствие транзакций и встроенных процедур. ТсХ решила, что реализация этих возможностей нанесет слишком сильный удар по производительности. Однако ТсХ продолжает работу в этом направлении, но так, чтобы от потери производительности страдали только те пользователи, которым такие возможности действительно необходимы.
С 1996 года ТсХ использует MySQL в среде, где имеется более 40 баз данных, содержащих 10 000 таблиц. Из этих 10 000 более 500 таблиц имеют, в свою очередь, более 7 миллионов записей - около 100 Гбайт данных.
Система безопасности MySQL
Вам не только нужно иметь надежный доступ к своим данным, но и быть уверенным, что у других нет никакого доступа к ним. MySQL использует собственный сервер баз данных для обеспечения безопасности. При первоначальной установке MySQL создается база данных под названием «mysql». В этой базе есть пять таблиц: db, host, user, tables_priv, и columns_priv. Более новые версии MySQL создают также базу данных с названием func, но она не имеет отношения к безопасности. MySQL использует эти таблицы для определения того, кому что позволено делать. Таблица user содержит данные по безопасности, относящиеся к серверу в целом. Таблица host содержит права доступа к серверу для удаленных компьютеров. И наконец, db, tables_priv и соlumns_priv управляют доступом к отдельным базам данных, таблицам и колонкам.
Мы кратко рассмотрим все таблицы, поддерживающие безопасность в MySQL, а затем рассмотрим технологию их использования при обеспечении защиты ядром MySQL.
Таблица user.Таблица user имеет вид, показанный в Таблице 3.1:
Таблица 3.1. Таблица user
| Поле
| Тип
| Null
| Ключ
| Значение по умолчанию
|
| Host
| char(60)
|
| PRI
|
|
| User
| char(16)
|
| PRI
|
|
| Password
| char(16)
|
|
|
|
| Select_priv
| enum('N','Y')
|
|
| N
|
| Insert_priv
| enum('N','Y')
|
|
| N
|
| Update_priv
| enum('N','Y')
|
|
| N
|
| Delete_priv
| enum('N','Y')
|
|
| N
|
| Create_priv
| enum('N','Y')
|
|
| N
|
| Drop_priv
| enum('N','Y')
|
|
| N
|
| Reload_priv
| enum('N','Y')
|
|
| N
|
| Shutdown_priv
| enum('N','Y')
|
|
| N
|
| Process_priv
| enum('N','Y')
|
|
| N
|
| File_priv
| enum('N','Y')
|
|
| N
|
| Grant_priv
| enum('N','Y')
|
|
| N
|
| References_priv
| enum('N','Y')
|
|
| N
|
| Index_priv
| enum('N','Y')
|
|
| N
|
| Alter_priv
| enum('N','Y')
|
|
| N
|
В колонках Host и User можно использовать символ «%», заменяющий произвольную последовательность символов. Например, имя узла «chem%lab» включает в себя «chembiolab», «chemtestlab» и т. д. Специальное имя пользователя «nobody» действует как одиночный «%», то есть охватывает всех пользователей, не упомянутых где-либо в другом месте. Ниже разъясняется смысл различных прав доступа:
Select_priv - Возможность выполнять команды SELECT.
Insert_priv - Возможность выполнять команды INSERT.
Update_priv - Возможность выполнять команды UPDATE.
Delete_priv - Возможность выполнять команды DELETE.
Create_priv - Возможность выполнять команды CREATE или создавать базы данных.
Drop_priv - Возможность выполнять команды DROP для удаления баз данных.
Reload_priv - Возможность обновлять информацию о доступе с помощью mysqladmin reload.
Shutdown_priv - Возможность останавливать сервер через mysqladmin shutdown.
Process_priv - Возможность управлять процессами сервера.
File_priv - Возможность читать и записывать файлы с помощью команд типа SELECT INTO OUTFILE и LOAD DATA INFILE.
Grant_priv - Возможность давать привилегии другим пользователям.
Index_priv - Возможность создавать и уничтожать индексы.
Alter_priv - Возможность выполнять команду ALTER TABLE.
В MySQL есть специальная функция, позволяющая скрыть пароли от любопытных глаз. Функция password() зашифровывает пароль. Ниже показано, как использовать функцию password() в процессе добавления пользователей в систему.
INSERT INTO user (Host, User, Password, Select_priv, Insert_priv, Update_priv, Delete_priv)
VALUES ('%', 'bob', password('mypass'), 'Y', 'Y', 'Y', 'Y')
INSERT INTO user (Host, User, Password, Select_priv)
VALUES ('athens.imaginary.com', 'jane', '', 'Y')
INSERT INTO user(Host, User, Password)
VALUES ('%', 'nobody', '')
INSERT INTO user (Host, User, Password, Select_priv, Insert_priv, Update_priv, Delete_priv)
VALUES ('athens.imaginary.com', 'nobody', password('thispass'), 'Y', 'Y', 'Y', 'Y')
мена пользователей MySQL обычно не связаны с именами пользователей операционной системы. По умолчанию клиентские средства MySQL используют при регистрации имена пользователей операционной системы, однако, обязательного соответствия не требуется. В большинстве клиентских приложений MySQL можно с помощью параметра -u подключиться к MySQL, используя любое имя. Ваше имя пользователя операционной системы не появится в таблице user, если не будет специально включено в нее с присвоением прав.
Первый созданный нами пользователь, «bob», может подключаться к базе данных с любого компьютера и выполнять команды SELECT, INSERT, UPDATE и DELETE. Второй пользователь, «jane», может подключаться с «athens.imaginary.com», не имеет пароля и может выполнять только SELECT. Третий пользователь - «nobody» - с любой машины. Этот пользователь вообще ничего не может делать. Последний пользователь - «nobody» - с машины «athens.imaginary.com», он может выполнять SELECT, INSERT, UPDATE и DELETE, как и пользователь «bob».
Как MySQL производит сопоставление? Некоторое имя может соответствовать на деле нескольким записям. Например, «nobody @athens.imaginary.com» соответствует и «nobody@%», и «nobody@athens.imaginary.com». Прежде чем осуществлять поиск в таблице user, MySQL сортирует данные следующим образом:
1. Сначала ищется соответствие для узлов, не содержащих масок «%», при этом пустое поле Host трактуется как «%».
2. Для одного и того же узла сначала проверяется соответствие имен, не содержащих масок. Пустое поле User трактуется как содержащее «%».
3. Первое найденное соответствие считается окончательным.
В предыдущем примере пользователь сначала будет сравниваться с «nobody» из «athens.imaginary.com», поскольку «athens.imaginary.com» в порядке сортировки стоит выше «%». Поскольку имена компьютеров сортируются раньше имен пользователей, значения привилегий для компьютера, с которого вы подключаетесь, имеют приоритет перед любыми конкретными правами, которые у вас могут быть. Если таблица user содержит записи:
| Host
| User
|
| %
| jane
|
| athens.imaginary.com
|
|
и jane подключается с «athens.imaginary.com», то MySQL будет использовать привилегии, данные «athens.imaginary.com».
Таблица db.В таблице user не упоминаются конкретные базы данных и таблицы. Таблица user управляет сервером в целом. Однако на сервере обычно находится несколько баз данных, которые служат различным целям и, соответственно, обслуживают разные группы пользователей. Права доступа к отдельным базам данных хранятся в таблице db:
Таблица 3.2. Таблица db
| Поле
| Тип
| Null
| Ключ
| Значение по умолчанию
|
| Host
| char(60)
|
| PRI
|
|
| Db
| char(32)
|
| PRI
|
|
| User
| char(16)
|
| PRI
|
|
| Select_priv
| enum('N','Y')
|
|
| N
|
| Insert_priv
| enum('N','Y')
|
|
| N
|
| Update_priv
| enum('N','Y')
|
|
| N
|
| Delete_priv
| enum('N','Y')
|
|
| N
|
| Create_priv
| enum('N','Y')
|
|
| N
|
| Drop_priv
| enum('N','Y')
|
|
| N
|
| References_priv
| enum('N','Y')
|
|
| N
|
| Index_priv
| enum('N','Y')
|
|
| N
|
| Alter_priv
| enum('N','Y')
|
|
| N
|
Эта таблица во многом похожа на таблицу user. Основное отличие в том, что вместо колонки Password имеется колонка Db. Таблица управляет правами пользователей в отношении определенных баз данных. Поскольку привилегии, указанные в таблице user, относятся ко всему серверу в целом, права, присвоенные пользователю в таблице user, перекрывают права, присвоенные тому же пользователю в таблице. Например, если пользователю в таблице user разрешают доступ типа INSERT, это право действует в отношении всех баз данных, вне зависимости от того, что указано в таблице db.
Наиболее эффективно создание в таблице user записей для всех пользователей, в которых не даны никакие права. В этом случае пользователь может лишь подключиться к серверу, не выполняя никаких действий. Исключение делается только для пользователя, назначенного администратором сервера. Все остальные должны получить права доступа через таблицу db. Каждый пользователь должен присутствовать в таблице user, иначе он не сможет подключаться к базам данных.
Те же правила, которые действуют в отношении колонок User и Host в таблице user, действуют и в таблице db, но с некоторой особенностью. Пустое поле Host вынуждает MySQL найти запись, соответствующую имени узла пользователя, в таблице host. Если такой записи не найдено, MySQL отказывает в доступе. Если соответствие найдено, MySQL определяет права как пересечение прав, определяемых таблицами host и db. Иными словами, в обеих записях разрешение должно иметь значение «Y», иначе в доступе отказывается.
Таблица host.Таблица host служит особой цели. Ее структура показана в таблице 3.3:
Таблица 3.3. Таблица Host
| Поле
| Тип
| Null
| Ключ
| Значение по умолчанию
|
| Host
| char(60)
|
| PRI
|
|
| Db
| char(32)
|
| PRI
|
|
| Select_priv
| enum('N','Y')
|
|
| N
|
| Insert_priv
| enum('N','Y')
|
|
| N
|
| Update_priv
| enum('N','Y')
|
|
| N
|
| Delete_priv
| enum('N','Y')
|
|
| N
|
| Create_priv
| enum('N','Y')
|
|
| N
|
| Drop_priv
| enum('N','Y')
|
|
| N
|
| Grant_priv
| enum('N','Y')
|
|
| N
|
| References_priv
| enum('N','Y')
|
|
| N
|
| Index_priv
| enum('N','Y')
|
|
| N
|
| Alter_priv
| enum('N','Y')
|
|
| N
|
Таблица host позволяет задать основные разрешения на межкомпьютерном уровне. При проверке прав доступа MySQL ищет в таблице db соответствие имени пользователя и его машине. Если он находит запись, соответствующую имени пользователя, поле host которой пусто, MySQL обращается к таблице host и использует пересечение обоих прав для определения окончательного права доступа. Если у вас есть группа серверов, которые вы считаете менее защищенными, то вы можете запретить для них все права записи. Если «bob» заходит с одной из таких машин, и его запись в таблице db содержит пустое поле host, ему будет запрещена операция записи, даже если она разрешена ему согласно таблице db.
Таблицы tables_priv и columns_priv.Эти две таблицы, по сути, уточняют данные, имеющиеся в таблице db. Именно, право на всякую операцию сначала проверяется по таблице db, затем по таблице tables_priv , затем по таблице columns_priv. Операция разрешается, если одна из них дает разрешение. С помощью этих таблиц можно сузить область действия разрешений до уровня таблиц и колонок. Управлять этими таблицами можно через команды SQL GRANT и REVOKE.
Последовательность контроля доступа.Соединим элементы системы защиты MySQL вместе и покажем, как можно ими пользоваться в реальных ситуациях. MySQL осуществляет контроль доступа в два этапа. Первый этап - подключение. Необходимо подключиться к серверу, прежде чем пытаться что-либо сделать.
При подключении проводятся две проверки. Сначала MySQL проверяет, есть ли в таблице user запись, соответствующая имени пользователя и машины, с которой он подключается. Поиск соответствия основывается на правилах, которые мы обсудили раньше. Если соответствие не найдено, в доступе отказывается. В случае, когда соответствующая запись найдена и имеет непустое поле Password , необходимо ввести правильный пароль. Неправильный пароль приводит к отклонению запроса на подключение.
Если соединение установлено, MySQL переходит к этапу верификации запроса. При этом сделанные вами запросы сопоставляются с вашими правами. Эти права MySQL проверяет по таблицам user, db, host, tables_pnv и columns_priv. Как только найдено соответствие в таблице user с положительным разрешением, команда немедленно выполняется. В противном случае MySQL продолжает поиск в следующих таблицах в указанном порядке:
1. db
2. tables_priv
3. columns_priv
Если таблица db содержит разрешение, дальнейшая проверка прекращается и выполняется команда. Если нет, то MySQL ищет соответствие в таблице tables_priv . Если это команда SELECT, объединяющая две таблицы, то пользователь должен иметь разрешения для обеих этих таблиц. Если хотя бы одна из записей отказывает в доступе или отсутствует, MySQL точно таким же способом проверяет все колонки в таблице columns_priv.
Изменение прав доступа.MySQL загружает таблицы доступа при запуске сервера. Преимуществом такого подхода по сравнению с динамическим обращением к таблицам является скорость. Отрицательная сторона состоит в том, что изменения, производимые в таблицах доступа MySQL, не сразу начинают действовать. Для того чтобы сервер увидел эти изменения, необходимо выполнить команду mysqladmin reload. Если таблицы изменяются с помощью SQL-команд GRANT или REVOKE, явно перегружать таблицы не требуется.
Утилиты MySQL
ТсХ распространяет MySQL с большим набором вспомогательных утилит, однако набор утилит, предлагаемых сторонними разработчиками, еще богаче.
Утилиты командной строки (Command Line Tools):
Isamchk - Производит проверку файлов, содержащих данные базы. Эти файлы называются ISAM-файлами (ISAM — метод индексированного последовательного доступа). Эта утилита может устранить большую часть повреждений ISAM-файлов.
Isamlog - Читает создаваемые MySQL журналы, относящиеся к ISAM-файлам. Эти журналы можно использовать для воссоздания таблиц или воспроизведения изменений, внесенных в таблицы в течение некоторого промежутка времени.
mysql - Создает прямое подключение к серверу баз данных и позволяет вводить запросы непосредственно из приглашения MySQL.
mysqlaccess - Модифицирует таблицы прав доступа MySQL и отображает их в удобном для чтения виде. Использование этой утилиты - хороший способ изучения структуры таблиц доступа MySQL.
Mysqladmin - Осуществляет административные функции. С помощью этой утилиты можно добавлять и удалять целые базы данных, а также завершать работу сервера.
Mysqlbug - Составляет для ТсХ отчет о возникшей в MySQL неполадке. Отчет будет также послан в почтовый список рассылки MySQL, и армия добровольцев MySQL будет исследовать проблему.
Mysqldump - Записывает все содержимое таблицы, включая ее структуру, в файл в виде SQL-команд, которыми можно воссоздать таблицу. Выходные данные этой утилиты можно использовать для воссоздания таблицы в другой базе или на другом сервере. Синтаксис ее применения: mysqldump -u user -p dbname --tab=path, где path - путь для сохранения файлов.
Mysqlimport - Считывает данные из файла и вводит их в таблицу базы данных. Это должен быть файл с разделителями, где разделитель может быть любого обычного вида, например, запятая или кавычки.
Mysqlshow - Выводит на экран структуру баз данных, имеющихся на сервере, и таблицы, из которых они состоят.
Утилиты сторонних разработчиков.Ни один поставщик или разработчик не может самостоятельно предоставить все необходимые для программного продукта средства поддержки. За самым свежим списком обратитесь на домашнюю страницу MySQL: http://www.mysql.com/Contrib.
Утилиты преобразования баз данных:
access_to_mysql - Преобразует базы данных Microsoft Access в таблицы MySQL. Включается в Access в виде функции, позволяющей сохранять таблицы в формате, позволяющем экспортировать их в MySQL.
dbf2mysql - Конвертирует файлы dBASE (DBF) в таблицы MySQL. Хотя dBASE утратил популярность, формат DBF установился как наиболее распространенный для передачи данных между различными приложениями баз данных. Все главные настольные приложения баз данных могут читать и писать DBF-файлы. Это приложение полезно для экспорта/импорта данных в коммерческие настольные базы данных.
Exportsql/Importsql - Конвертирует базы данных Microsoft Access в MySQL и обратно. Эти утилиты являются функциями Access, которые можно использовать для экспорта таблиц Access в формате, пригодном для чтения MySQL. С их помощью можно также преобразовывать SQL-выход MySQL в вид, пригодный для чтения Access.
Интерфейсы CGI:
PHP - Создает HTML-страницы с использованием специальных тегов, распознаваемых анализатором РНР. РНР имеет интерфейсы к большинству основных баз данных, включая MySQL и mSQL.
Mysql-webadmin - Осуществляет веб-администрирование баз данных MySQL. Используя это средство, можно просматривать таблицы и изменять их содержимое с помощью HTML-форм.
Mysqladm - Осуществляет веб-администрирование баз данных MySQL. Эта CGI-программа позволяет просматривать таблицы через WWW, добавлять таблицы и изменять их содержимое.
www-sql - Создает HTML-страницы из таблиц баз данных MySQL. Эта программа осуществляет разбор HTML-страниц в поисках специальных тегов и использует извлеченные данные для выполнения команд SQL на сервере MySQL.
Клиентские приложения:
Mysqlwinadmn - Позволяет администрировать MySQL из Windows. С помощью этого средства можно выполнять функции mysqladmin из графического интерфейса.
Xmysql - Обеспечивает полный доступ к таблицам баз данных MySQL для клиента X Window System. Поддерживает групповые вставки и удаления.
Xmysqladmin - Позволяет осуществлять администрирование MySQL из X Window System. Это инструмент для графического интерфейса, позволяющий создавать и удалять базы данных и управлять таблицами. С его помощью можно также проверять, запущен ли сервер, перегружать таблицы доступа и управлять потоками.
Интерфейсы программирования:
MyODBC - Реализует ODBC API к MySQL в Windows.
mm.mysql.jdbc - Реализует стандартный API JDBC (Java Database Connectivity -доступ к базам данных из Java).
TwzJdbcForMysql - Реализация JDBC API для Java.
Язык SQL.
Для чтения и записи в базах данных MySQL используется структурированный язык запросов (SQL). Используя SQL, можно осуществлять поиск, вводить новые данные или удалять данные. SQL является просто основополагающим инструментом, необходимым для взаимодействия с MySQL. Даже если для доступа к базе данных вы пользуетесь каким-то приложением или графическим интерфейсом пользователя, где-то в глубине это приложение генерирует SQL-команды.
SQL является разновидностью «естественного языка». Иными словами, команда SQL должна читаться, по крайней мере на первый взгляд, как предложение английского языка. У такого подхода есть как преимущества, так и недостатки, но факт заключается в том, что этот язык очень непохож на традиционные языки программирования, такие как С, Java или Perl. Здесь мы рассмотрим язык SQL, как он реализован в MySQL.
Основы SQL.SQL «структурирован» в том отношении, что он следует определенному набору правил. Компьютерной программе легко разобрать на части сформулированный запрос SQL. Действительно, в книге издательства O'Reilly «lex & уасс», написанной Дж. Ливайном, Т. Мэйсоном и Д. Брауном (John Levine, Tony Mason, Doug Brown), реализована грамматика SQL для демонстрации процесса создания программы, интерпретирующей язык! Запрос (query) - это полностью заданная команда, посылаемая серверу баз данных, который выполняет запрошенное действие. Ниже приведен пример SQL-запроса:
SELECT name FROM people WHERE name LIKE Stac%'
Как можно видеть, это предложение выглядит почти как фраза на ломаном английском языке: «Выбрать имена из список люди, где имена похожи на Stac». SQL в очень незначительной мере использует форматирование и специальные символы, обычно ассоциируемые с компьютерными языками. Сравните, к примеру, «$++;($*++/$!);$&$",,;$!» в Perl и «SELECT value FROM table» в SQL.
История SQL.В IBM изобрели SQL в начале 1970-х, вскоре после введения д-ром Е. Ф. Коддом (Е. F. Codd) понятия реляционной базы данных. С самого начала SQL был легким в изучении, но мощным языком. Он напоминает естественный язык, такой как английский, и поэтому не утомляет тех, кто не является техническим специалистом.
SQL действительно был настолько популярен среди пользователей, для которых предназначался, что в 1980-х компания Oracle выпустила первую в мире общедоступную коммерческую SQL-систему. Oracle SQL был хитом сезона и породил вокруг SQL целую индустрию. Sybase, Informix, Microsoft и ряд других компаний вышли на рынок с собственными разработками реляционных систем управления базами данных (РСУБД), основанных на SQL.
В то время когда Oracle и ее конкуренты вышли на сцену, SQL был новинкой, и для него не существовало стандартов. Лишь в 1989 году комиссия по стандартам ANSI выпустила первый общедоступный стандарт SQL. Сегодня его называют SQL89. К несчастью, этот новый стандарт не слишком углублялся в определение технической структуры языка. Поэтому, хотя различные коммерческие реализации языка SQL сближались, различия в синтаксисе делали задачу перехода с одной реализации языка на другую нетривиальной. Только в 1992 году стандарт ANSI SQL вступил в свои права.
Стандарт 1992 года обозначают как SQL92 или SQL2. Стандарт SQL2 включил в себя максимально возможное количество расширений, добавленных в коммерческих реализациях языка. Большинство инструментов, работающих с различными базами данных, основывается на SQL2 как на способе взаимодействия с реляционными базами данных. Однако, из-за очень большой широты стандарта SQL2, реляционные базы, реализующие полный стандарт, очень сложные и ресурсоемкие.
SQL2 - не последнее слово в стандартах SQL. В связи с ростом популярности объектно-ориентированных СУБД (ООСУБД) и объектно-реляционных СУБД (ОРСУБД) возрастает давление с целью принятия объектно-ориентированного доступа к базам данных в качестве стандарта SQL. Ответом на эту проблему должен послужить SQL3. Он не является пока официальным стандартом, но в настоящее время вполне определился и может стать официальным стандартом.
С появлением MySQL проявился новый подход к разработке серверов баз данных. Вместо создания очередной гигантской РСУБД с риском не предложить ничего нового в сравнении с «большими парнями», были предложены небольшие и быстрые реализации наиболее часто используемых функций SQL.
Архитектура SQL.SQL больше напоминает естественный человеческий, а не компьютерный язык. SQL добивается этого сходства благодаря четкой императивной структуре. Во многом походя на предложение английского языка, отдельные команды SQL, называемые запросами, могут быть разбиты на части речи. Рассмотрим примеры:
| CREATE
| TABLE
| people (name CHAR(10))
|
| глагол
| дополнение
| расширенное определение
|
| INSERT
| INTO people
| VALUES('me')
|
|
| глагол
| косвенное дополнение
| прямое дополнение
|
|
| SELECT
| name
| FROM people
| WHERE name LIKE '%e'
|
| глагол
| прямое дополнение
| косвенное дополнение
| придаточное предложение
|
Большинство реализаций SQL, включая MySQL, нечувствительны к регистру: неважно, в каком регистре вы вводите ключевые слова SQL, если орфография верна. Например, CREATE из верхнего примера можно записать и так:
cREatE ТАblЕ people (name cHaR(10))
Нечувствительность к регистру относится только к ключевым словам SQL. В MySQL имена баз данных, таблиц и колонок к регистру чувствительны. Но это характерно не для всех СУБД. Поэтому, если вы пишете приложение, которое должно работать с любыми СУБД, не следует использовать имена, различающиеся одним только регистром.
Первый элемент SQL-запроса - всегда глагол. Глагол выражает действие, которое должно выполнить ядро базы данных. Хотя остальная часть команды зависит от глагола, она всегда следует общему формату: указывается имя объекта, над которым осуществляется действие, а затем описываются используемые при действии данные. Например, в запросе CREATE TABLE people (char(10)) используется глагол CREATE, за которым следует дополнение (объект) TABLE. Оставшаяся часть запроса описывает таблицу, которую нужно создать.
SQL-запрос исходит от клиента - приложения, с помощью которого пользователь взаимодействует с базой данных. Клиент составляет запрос, основываясь на действиях пользователя, и посылает его серверу SQL. После этого сервер должен обработать запрос и выполнить указанные действия. Сделав свою работу, сервер возвращает клиенту одно или несколько значений.
Поскольку основная задача SQL - сообщить серверу баз данных о том, какие действия необходимо выполнить, он не обладает гибкостью языка общего назначения. Большинство функций SQL связано с вводом и выводом из базы: добавление, изменение, удаление и чтение данных. SQL предоставляет и другие возможности, но всегда с оглядкой на то, как они могут использоваться для манипулирования данными в базе.
Создание и удаление таблиц.Успешно установив MySQL, вы можете приступить к созданию своей первой таблицы. Таблица, структурированное вместилище данных, является основным понятием реляционных баз. Прежде чем начать вводить данные в таблицу, вы должны определить ее структуру. Рассмотрим следующую раскладку:
| people
|
| name
| char(10) not null
|
| address
| text(100)
|
| id
| int
|
Таблица содержит не только имена колонок, но и тип каждого поля, а также возможные дополнительные сведения о полях. Тип данных поля определяет, какого рода данные могут в нем содержаться. Типы данных SQL сходны с типами данных в других языках программирования. Полный стандарт SQL допускает большое разнообразие типов данных. MySQL реализует большую их часть.
Общий синтаксис для создания таблиц следующий:
CREATE TABLE table_name (column_name1 type [modifiers]
[, column_name2 type [modifiers]] )
Какие идентификаторы - имена таблиц и колонок - являются допустимыми, зависит от конкретной СУБД. В MySQL длина идентификатора может быть до 64 символов, допустим символ «$», и первым символом может быть цифра. Более важно, однако, что MySQL допускает использование любых символов из установленного в системе локального набора. Для хорошей переносимости SQL избегайте имен, начинающихся не с допустимой буквы.
Колонка - это отдельная единица данных в таблице. В таблице может содержаться произвольное число колонок, но использование больших таблиц бывает неэффективным. Создав правильно нормализованные таблицы, можно объединять их («join») для осуществления поиска в данных, размещенных в нескольких таблицах. Механику объединения таблиц мы обсудим позднее.
Как и бывает в жизни, разрушить легче, чем создать. Следующая команда удаляет таблицу:
DROP TABLE table_name
MySQL уничтожит все данные удаленной таблицы. Если у вас не осталось резервной копии, нет абсолютно никакого способа отменить действие данной операции. Поэтому всегда храните резервные копии и будьте очень внимательны при удалении таблиц. В один «прекрасный» день это вам пригодится.
В MySQL можно одной командой удалить несколько таблиц, разделяя их имена запятыми. Например, DROP TABLE people, animals, plants удалит эти три таблицы. Можно также использовать модификатор IF EXISTS для подавления ошибки в случае отсутствия удаляемой таблицы. Этот модификатор полезен в больших сценариях, предназначенных для создания базы данных и всех ее таблиц. Прежде чем создавать таблицу, выполните команду DROP TABLE table_name IF EXISTS.
Типы данных в SQL.Каждая колонка таблицы имеет тип. Типы данных SQL сходны с типами данных традиционных языков программирования. В то время как во многих языках определен самый минимум типов, необходимых для работы, в SQL для удобства пользователей определены дополнительные типы, такие как MONEY и DATE. Данные типа MONEY можно было бы хранить и как один из основных числовых типов данных, однако использование типа, специально учитывающего особенности денежных расчетов, повышает легкость использования SQL.
Таблица 3.4.Наиболее употребительные типы данных, поддерживаемые MySQL
| Тип данных
| Описание
|
| INT
| Целое число, может быть со знаком или без знака.
|
| REAL
| Число с плавающей запятой. Этот тип допускает больший диапазон значений, чем INT, но не обладает его точностью.
|
| CHAR(length)
| Символьная величина фиксированной длины. Поля типа CHAR не могут содержать строки длины большей, чем указанное значение. Поля меньшей длины дополняются пробелами.
|
| TEXT(length)
| Символьная величина переменной длины. TEXT - лишь один из нескольких типов данных переменного размера.
|
| DATE
| Стандартное значение даты.
|
| TIME
| Стандартное значение времени. Этот тип используется для хранения времени дня безотносительно какой-либо даты. При использовании вместе с датой позволяет хранить конкретную дату и время. Есть дополнительный тип DATETIME для совместного хранения даты и времени в одном поле.
|
MySQL поддерживает атрибут UNSIGNED для всех числовых типов. Этот модификатор позволяет вводить в колонку только положительные (беззнаковые) числа. Беззнаковые поля имеют верхний предел значений вдвое больший, чем у соответствующих знаковых типов. Беззнаковый TINYINT - однобайтовый числовой тип MySQL - имеет диапазон от 0 до 255, а не от -127 до 127, как у своего знакового аналога.
MySQL имеет больше типов, чем перечислено выше. Однако на практике в основном используются перечисленные типы. Размер данных, которые вы собираетесь хранить, играет гораздо большую роль при разработке таблиц MySQL.
Числовые типы данных.Прежде чем создавать таблицу, вы должны хорошо представить себе, какого рода данные вы будете в ней хранить. Помимо очевидного решения о том, будут это числовые или символьные данные, следует выяснить примерный размер хранимых данных. Если это числовое поле, то каким окажется максимальное значение? Может ли оно измениться в будущем? Если минимальное значение всегда положительно, следует рассмотреть использование беззнакового типа. Всегда следует выбирать самый маленький числовой тип, способный хранить самое большое мыслимое значение. Если бы требовалось хранить в поле численность населения штата, следовало бы выбрать беззнаковый INT. В штате не может быть отрицательной численности населения, а чтобы беззнаковое поле типа INT не могло вместить число, представляющее его население, численность населения штата должна примерно равняться численности населения всей Земли.
Символьные типы.С символьными типами работать немного труднее. Вы должны подумать не только о максимальной и минимальной длине строки, но также о среднем размере, частоте отклонения от него и необходимости в индексировании. В данном контексте мы называем индексом поле или группу полей, в которых вы собираетесь осуществлять поиск — в основном, в предложении WHERE. Индексирование, однако, значительно сложнее, чем такое упрощенное определение, и мы займемся им далее. Здесь важно лишь отметить, что индексирование по символьным полям происходит значительно быстрее, если они имеют фиксированную длину. Если длина строк не слишком колеблется или, что еще лучше, постоянна, то, вероятно, лучше выбрать для поля тип CHAR. Хороший кандидат на тип CHAR - код страны. Стандартом ISO определены двух символьные коды для всех стран. CHAR(2) будет правильным выбором для данного поля.
Чтобы подходить для типа CHAR, поле необязательно должно быть фиксированной длины, но длина не должна сильно колебаться. Телефонные номера, к примеру, можно смело хранить в поле CHAR(13), хотя длина номеров различна в разных странах. Просто различие не столь велико, поэтому нет смысла делать поле для номера телефона переменным по длине. В отношении поля типа CHAR важно помнить, что, вне зависимости от реальной длины хранимой строки, в поле будет ровно столько символов, сколько указано в его размере - не больше и не меньше. Разность в длине между размером сохраняемого текста и размером поля заполняется пробелами. Не стоит беспокоиться по поводу нескольких лишних символов при хранении телефонных номеров, но не хотелось бы тратить много места в некоторых других случаях. Для этого существуют текстовые поля переменной длины.
Хороший пример поля, для которого требуется тип данных с переменной длиной, дает URL Интернет. По большей части адреса Web занимают сравнительно немного места - http://www.ora.com, http://www.hughes.com.au, http://www.mysql.com - и не представляют проблемы. Иногда, однако, можно наткнуться на адреса подобного вида:
http://www.winespectator.com/Wine/Spectator/notes\5527293926834323221480431354?XvlI=&Xr5=&Xvl =&type-region-search-code=&Xa14=flora+springs&Xv4=.
Если создать поле типа CHAR длины, достаточной для хранения этого URL, то почти для каждого другого хранимого URL будет напрасно тратиться весьма значительное пространство. Поля переменной длины позволяют задать такую длину, что оказывается возможным хранение необычно длинных значений, и в то же время не расходуется напрасно место при хранении обычных коротких величин.
Поля переменной длины.Преимуществом текстовых полей переменной длины является то, что они используют ровно столько места, сколько необходимо для хранения отдельной величины. Например, поле типа VARCHAR(255) , в котором хранится строка «hello, world», занимает только двенадцать байтов (по одному байту на каждый символ плюс еще один байт для хранения длины). В отличие от стандарта ANSI, в MySQL поля типа VARCHAR не дополняются пробелами. Перед записью из строки удаляются лишние пробелы.
Сохранить строки, длина которых больше, чем заданный размер поля, нельзя. В поле VARCHAR(4) можно сохранить строку не длиннее 4 символов. Если вы попытаетесь сохранить строку «happy birthday», MySQL сократит ее до «happ». Недостатком подхода MySQL к хранению полей переменной длины является то, что не существует способа сохранить необычную строку, длина которой превосходит заданное вами значение. В таблице 3.5 показан размер пространства, необходимого для хранения 144-символьного URL, продемонстрированного выше, и обычного, 30-символьного URL.
Таблица 3.5.Пространство памяти, необходимое для различных символьных типов MySQL
| Тип данных
| Пространство для хранения строки из 144 символов
| Пространство для хранения строки из 30 символов
| Максимальная длина строки
|
| СНАR(150)
|
|
|
|
| VARCHAR(150)
|
|
|
|
| TINYTEXT(150)
|
|
|
|
| ТЕХТ(150)
|
|
|
|
| MEDIUMTEXT(150)
|
|
|
|
| LONGTEXT(150)
|
|
|
|
Если через годы работы со своей базой данных вы обнаружите, что мир изменился, и поле, уютно чувствовавшее себя в типе VARCHAR(25), должно теперь вмещать строки длиной 30 символов, не все потеряно. В MySQL есть команда ALTER TABLE , позволяющая переопределить размер поля без потери данных.
ALTER TABLE mytable MODIFY mycolumn LONGTEXT
Двоичные типы данных.В MySQL есть целый ряд двоичных типов данных, соответствующих своим символьным аналогам. Двоичными типами, поддерживаемыми MySQL, являются CHAR BINARY, VARCHAR BINARY, TINYBLOB, BLOB, MEDIUMBLOB и LONGBLOB. Практическое отличие между символьными типами и их двоичными аналогами основано на принципе кодировки. Двоичные данные просто являются куском данных, которые MySQL не пытается интерпретировать. Напротив, символьные данные предполагаются представляющими текстовые данные из используемых человеком алфавитов. Поэтому они кодируются и сортируются, основываясь на правилах, соответствующих рассматриваемому набору символов. Двоичные же данные MySQL сортирует в порядке ASCII без учета регистра.
Перечисления и множества.MySQL предоставляет еще два особых типа данных. Тип ENUM позволяет при создании таблицы указать список возможных значений некоторого поля. Например, если бы у вас была колонка с именем «фрукт», в которую вы разрешили бы помещать только значения «яблоко», «апельсин», «киви» и «банан», ей следовало бы присвоить тип ENUM:
CREATE TABLE meal(meal_id INT NOT NULL PRIMARY KEY,
фрукт ENUM('яблоко', 'апельсин', 'киви', 'банан'))
При записи значения в эту колонку оно должно быть одним из перечисленных фруктов. Поскольку MySQL заранее знает, какие значения допустимы для этой колонки, она может абстрагировать их каким-либо числовым типом. Иными словами, вместо того, чтобы хранить в колонке «яблоко» в виде строки, MySQL заменяет его однобайтовым числом, а «яблоко» вы видите, когда обращаетесь к таблице или выводите из нее результаты.
Тип MySQL SET позволяет одновременно хранить в поле несколько значений.
Другие типы данных.Любые мыслимые данные можно хранить с помощью числовых или символьных типов. В принципе, даже числа можно хранить в символьном виде. Однако то, что это можно сделать, не означает, что это нужно делать. Рассмотрим, к примеру, как хранить в базе данных денежные суммы. Можно делать это, используя INT или REAL. Хотя интуитивно REAL может показаться более подходящим - в конце концов, в денежных суммах нужны десятичные знаки, - на самом деле более правильно использовать INT. В полях, содержащих значения с плавающей запятой, таких как REAL, часто невозможно найти число с точным десятичным значением. Например, если вы вводите число 0.43, которое должно представлять сумму $0.43, MySQL может записать его как 0.42999998. Это небольшое отличие может вызвать проблемы при совершении большого числа математических операций.
MySQL предоставляет специальные типы данных для таких денежных сумм. Одним из них является тип MONEY, другим - DATE.
Индексы.Хотя MySQL обеспечивает более высокую производительность, чем любые большие серверы баз данных, некоторые задачи все же требуют осторожности при проектировании базы данных. Например, если таблица содержит миллионы строк, поиск нужной строки в ней наверняка потребует длительного времени. В большинстве баз данных поиск облегчается благодаря средству, называемому индексом.
Индексы способствуют хранению данных в базе таким образом, который позволяет осуществлять быстрый поиск. К несчастью, ради скорости поиска приходится жертвовать дисковым пространством и скоростью изменения данных. Наиболее эффективно создавать индексы для тех колонок, в которых вы чаще всего собираетесь осуществлять поиск. MySQL поддерживает следующий синтаксис для создания индексов:
CREATE INDEX index_name ON tablename (column1, column2, columnN)
MySQL позволяет также создавать индекс одновременно с созданием таблицы, используя следующий синтаксис:
CREATE TABLE materials (id INT NOT NULL,
name CHAR(50) NOT NULL,
resistance INT,
melting_pt REAL,
INDEX index1 (id, name),
UNIQUE INDEX index2 (name))
В этом примере для таблицы создается два индекса. Первый индекс index1 состоит из полей id и name. Второй индекс включает в себя только поле name и указывает, что значения поля name должны быть уникальными. Если вы попытаетесь вставить в поле name значение, которое уже есть в этом поле в какой-либо строке, операция не будет осуществлена. Все поля, указанные в уникальном индексе, должны быть объявлены как NOT NULL .
Хотя мы создали отдельный индекс для поля name, отдельно для поля id мы не создавали индекса. Если такой индекс нам понадобится, создавать его не нужно - он уже есть. Когда индекс содержит более одной колонки (например, name, rank, и serial_number), MySQL читает колонки в порядке слева направо. Благодаря используемой MySQL структуре индекса всякое подмножество колонок с левого края автоматически становится индексом внутри «главного» индекса. Например, когда вы создаете индекс name, rank, serial_number, создаются также «свободные» индексы name и name вместе с rank. Однако индексы rank или name и serial_number не создаются, если не потребовать этого явно.
MySQL поддерживает также семантику ANSI SQL для особого индекса, называемого первичным ключом. В MySQL первичный ключ - это уникальный индекс с именем PRIMARY. Назначив при создании таблицы колонку первичным ключом, вы делаете ее уникальным индексом, который будет поддерживать объединения таблиц. В следующем примере создается таблица cities с первичным ключом id.
CREATE TABLE cities (id INT NOT NULL PRIMARY KEY,
name VARCHAR(100),
pop MEDIUMINT,
founded DATE)
Прежде чем создавать таблицу, нужно решить, какие поля будут ключами (и будут ли вообще ключи). Как уже говорилось, любые поля, которые будут участвовать в объединении таблиц, являются хорошими кандидатами на роль первичного ключа.
Последовательности и автоинкрементирование.Лучше всего, когда первичный ключ не имеет в таблице никакого иного значения, кроме значения первичного ключа. Для достижения этого лучшим способом является создание числового первичного ключа, значение которого увеличивается при добавлении в таблицу новой строки. Если вернуться к примеру с таблицей cities, то первый введенный вами город должен иметь id, равный 1, второй - 2, третий - 3, и т. д. Чтобы успешно управлять такой последовательностью первичных ключей, нужно иметь какое-то средство, гарантирующее, что в данный конкретный момент только один клиент может прочесть число и увеличить его на единицу. В базе данных с транзакциями можно создать таблицу, скажем, с именем sequence, содержащую число, представляющее очередной id. Когда необходимо добавить новую строку в таблицу, вы читаете число из этой таблицы и вставляете число на единицу большее. Чтобы эта схема работала, нужно быть уверенным, что никто другой не сможет произвести чтение из таблицы, пока вы не ввели новое число. В противном случае два клиента могут прочесть одно и то же значение и попытаться использовать его в качестве значения первичного ключа в одной и той же таблице.
MySQL не поддерживает транзакции, поэтому описанный механизм нельзя использовать для генерации уникальных чисел. Использовать для этих целей команду MySQL LOCK TABLE обременительно. Тем не менее СУБД предоставляет свой вариант понятия последовательности, позволяющий генерировать уникальные идентификаторы, не беспокоясь о транзакциях.
Последовательности.При создании таблицы в MySQL можно одну из колонок специфицировать как AUTO_INCREMENT. В этом случае, при добавлении новой строки, имеющей значение NULL или 0 в данной колонке, автоматически будет происходить замена на значение на единицу больше, чем наибольшее текущее значение в колонке. Колонка с модификатором AUTO_INCREMENT должна быть индексирована. Ниже приведен пример использования поля типа AUTO_INCREMENT:
CREATE TABLE cities (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
pop MEDIUMINT,
founded DATE)
Когда вы первый раз добавляете строку, поле id получает значение 1, если в команде INSERT для него используется значение NULL или 0. Например, следующая команда использует возможность AUTO_INCREMENT:
INSERT INTO cities (id, name, pop)
VALUES (NULL, 'Houston', 3000000)
Если вы выполните эту команду, когда в таблице нет строк, поле id получит значение 1, а не NULL. В случае, когда в таблице уже есть строки, полю будет присвоено значение на 1 большее, чем наибольшее значение id в данный момент.
Другим способом реализации последовательностей является использование значения, возвращаемого функцией LAST_INSERT_ID:
UPDATE table SET id=LAST_INSERT_ID (id+1);
Управление данными.Первое, что вы делаете, создав таблицу, это добавляете в нее данные. Если данные уже есть, может возникнуть необходимость изменить или удалить их.
Добавление данных.Добавление данных в таблицу является одной из наиболее простых операций SQL. Несколько примеров этого вы уже видели. MySQL поддерживает стандартный синтаксис INSERT:
INSERT INTO table_name (column1, column2, ..., columnN)
VALUES (value1, value2, ..., valueN)
Данные для числовых полей вводятся, как они есть. Для всех других полей вводимые данные заключаются в одиночные кавычки. Например, для ввода данных в таблицу адресов можно выполнить следующую команду:
INSERT INTO addresses (name, address, city, state, phone, age)
VALUES('Irving Forbush', '123 Mockingbird Lane', 'Corbin', 'KY', '(800) 555-1234', 26)
Кроме того, управляющий символ - по умолчанию '\' - позволяет вводить в литералы одиночные кавычки и сам символ '\':
# Ввести данные в каталог Stacie's Directory, который находится
# в c:\Personal\Stacie
INSERT INTO files (description, location)
VALUES ('Stacie\'s Directory', 'C:\\Personal\\Stacie')
MySQL позволяет опустить названия колонок, если значения задаются для всех колонок и в том порядке, в котором они были указаны при создании таблицы командой CREATE. Однако если вы хотите использовать значения по умолчанию, нужно задать имена тех колонок, в которые вы вводите значения, отличные от установленных по умолчанию. Если для колонки не установлено значение по умолчанию, и она определена как NOT NULL, необходимо включить эту колонку в команду INSERT со значением, отличным от NULL. MySQL позволяет указать значение по умолчанию при создании таблицы в команде CREATE.
Новые версии MySQL поддерживают INSERT для одновременной вставки нескольких строк:
INSERT INTO foods VALUES (NULL, 'Oranges', 133, 0, 2, 39),
(NULL, 'Bananas', 122, 0, 4, 29),
(NULL, 'Liver', 232, 3, 15. 10)
Хотя поддерживаемый MySQL нестандартный синтаксис удобно использовать для быстрого выполнения задач администрирования, не следует без крайней нужды пользоваться им при написании приложений. Как правило, следует придерживаться стандарта ANSI SQL2 настолько близко, насколько MySQL это позволяет. Благодаря этому вы получаете возможность перейти в будущем на какую-нибудь другую базу данных. Переносимость особенно важна для тех, у кого потребности среднего масштаба, поскольку такие пользователи предполагают когда-нибудь перейти на полномасштабную базу данных.
MySQL поддерживает синтаксис SQL2, позволяющий вводить в таблицу результаты запроса:
INSERT INTO foods (name, fat)
SELECT food_name, fat_grams FROM recipes
Обратите внимание, что число колонок в INSERT соответствует числу колонок в SELECT. Кроме того, типы данных колонок в INSERT должны совпадать с типами данных в соответствующих колонках SELECT. И, наконец, предложение SELECT внутри команды INSERT не должно содержать модификатора ORDER BY и не может производить выборку из той же таблицы, в которую вставляются данные командой INSERT.
Изменение данных.Если ваша база не является базой данных «только для чтения», вам, вероятно, понадобится периодически изменять данные. Стандартная команда SQL для изменения данных выглядит так:
UPDATE table_name
SET column1=value1, column2=value2, ..., columnN=valueN
[WHERE clause]
MySQL позволяет вычислять присваиваемое значение. Можно даже вычислять значение, используя значение другой колонки:
UPDATE years
SET end_year = begin_year+5
В этой команде значение колонки end_year устанавливается равным значению колонки begin_year плюс 5 для каждой строки таблицы.
Предложение WHERE.Возможно, вы уже обратили внимание на предложение WHERE. В SQL предложение WHERE позволяет отобрать строки таблицы с заданным значением в указанной колонке, например:
UPDATE bands
SET lead_singer = 'Ian Anderson'
WHERE band_name = 'Jethro Tull'
Эта команда - UPDATE - указывает, что нужно изменить значение в колонке lead_singer для тех строк, в которых band_name совпадает с «Jethro Tull». Если рассматриваемая колонка не является уникальным индексом, предложение WHERE может соответствовать нескольким строкам. Многие команды SQL используют предложение WHERE, чтобы отобрать строки, над которыми нужно совершить операции. Поскольку по колонкам, участвующим в предложении WHERE, осуществляется поиск, следует иметь индексы по тем их комбинациям, которые обычно используются.
Удаление.Для удаления данных вы просто указываете таблицу, из которой нужно удалить строки, и в предложении WHERE задавая строки, которые хотите удалить:
DELETE FROM table_name [WHERE clause]
Как и в других командах, допускающих использование предложения WHERE, его использование является необязательным. Если предложение WHERE опущено, то из таблицы будут удалены все записи!
Запросы.Самая часто используемая команда SQL - та, которая позволяет просматривать данные в базе: SELECT. Ввод и изменение данных производятся лишь от случая к случаю, и большинство баз данных в основном занято тем, что предоставляет данные для чтения. Общий вид команды SELECT следующий:
SELECT column1, column2, ..., columnN
FROM table1, table2, ..., tableN
[WHERE clause]
Этот синтаксис чаще всего используется для извлечения данных из базы, поддерживающей SQL. Cуществуют разные варианты для выполнения сложных и мощных запросов.
В первой части команды SELECT перечисляются колонки, которые вы хотите извлечь. Можно задать «*», чтобы указать, что вы хотите извлечь все колонки. В предложении FROM указываются таблицы, в которых находятся эти колонки. Предложение WHERE указывает, какие именно строки должны использоваться, и позволяет определить, каким образом должны объединяться две таблицы.
Объединения.Объединения вносят «реляционность» в реляционные базы данных. Именно объединение позволяет сопоставить строке одной таблицы строку другой. Основным видом объединения является то, что иногда называют внутренним объединением. Объединение таблиц заключается в приравнивании колонок двух таблиц:
SELECT book, title, author. name
FROM author, book
WHERE book.author = author.id
Рассмотрим базу данных, в которой таблица book имеет вид, как в таблице 3.6.
Таблица 3.6.Таблица книг
| ID
| Title
| Author
| Pages
|
|
| The Green Mile
|
|
|
|
| Guards, Guards!
|
|
|
|
| Imzadi
|
|
|
|
| Gold
|
|
|
|
| Howling Mad
|
|
|
А таблица авторов author имеет вид таблицы 3.7.
Таблица 3.7.Таблица авторов
| ID
| Name
| Citizen
|
|
| Isaac Asimov
| US
|
|
| Terry Pratchet
| UK
|
|
| Peter David
| US
|
|
| Stephen King
| US
|
|
| Neil Gaiman
| UK
|
В результате внутреннего объединения создается таблица, в которой объединяются поля обеих таблиц для строк, удовлетворяющих запросу в обеих таблицах. В нашем примере запрос указывает, что поле author в таблице book должно совпадать с полем id таблицы author. Результат выполнения этого запроса представлен в таблице 3.8.
Таблица 3.8.Результаты запроса с внутренним объединением
| Book Title
| Author Name
|
| The Green Mile
| Stephen King
|
| Guards, Guards!
| Terry Pratchet
|
| Imzadi
| Peter David
|
| Gold
| Isaac Asimov
|
| Howling Mad
| Peter David
|
В этих результатах нет автора с именем Neil Gaiman, поскольку его author.id не найден в таблице book.author. Внутреннее объединение содержит только те строки, которые точно соответствуют запросу. Ниже мы обсудим понятие внешнего объединения, которое оказывается полезным в случае, когда в базу данных внесен писатель, у которого нет в этой базе книг.
Псевдонимы.Полные имена, содержащие имена таблиц и колонок, зачастую весьма громоздки. Кроме того, при использовании функций SQL, о которых мы будем говорить ниже, может оказаться затруднительным ссылаться на одну и ту же функцию более одного раза в пределах одной команды. Псевдонимы, которые обычно короче и более выразительны, могут использоваться вместо длинных имен внутри одной команды SQL, например:
# Псевдоним колонки
SELECT long_field_names_are_annoying AS myfield
FROM table_name
WHERE myfield = 'Joe'
# Псевдоним таблицы в MySQL
SELECT people.names, tests.score
FROM tests really_long_people_table_name AS people
Группировка и упорядочение.По умолчанию порядок, в котором появляются результаты выборки, не определен. К счастью, SQL предоставляет некоторые средства наведения порядка в этой случайной последовательности. Первое средство - упорядочение. Вы можете потребовать от базы данных, чтобы выводимые результаты были упорядочены по некоторой колонке. Например, если вы укажете, что запрос должен упорядочить результаты по полю last_name, то результаты будут выведены в алфавитном порядке по значению поля last_name. Упорядочение осуществляется с помощью предложения ORDER BY:
SELECT last_name, first_name, age
FROM people
ORDER BY last_name, first_name
В данном случае упорядочение производится по двум колонкам. Можно проводить упорядочение по любому числу колонок, но все они должны быть указаны в предложении SELECT. Если бы в предыдущем примере мы не выбрали поле last_name, то не смогли бы упорядочить по нему.
Группировка - это средство ANSI SQL, реализованное в MySQL. Как и предполагает название, группировка позволяет объединять в одну строки с аналогичными значениями с целью их совместной обработки. Обычно это делается для применения к результатам агрегатных функций. О функциях мы поговорим несколько позднее.
Рассмотрим пример:
mysql> SELECT name, rank, salary FROM people\g
| name
| rank
| salary
|
| Jack Smith
| Private
|
|
| Jane Walker
| General
|
|
| June Sanders
| Private
|
|
| John Barker
| Sergeant
|
|
| Jim Castle
| Sergeant
|
|
5 rows in set (0.01 sec)
После группировки по званию (rank) выдача изменяется:
mysql> SELECT rank FROM people GROUP BY rank\g
| rank
|
| General
|
| Private
|
| Sergeant
|
3 rows in set (0.01 sec)
После применения группировки можно, наконец, найти среднюю зарплату (salary) для каждого звания. О функциях, используемых в этом примере, мы поговорим позднее.
mysql> SELECT rank, AVG(salary) AS income FROM people GROUP BY rank\g
| rank
| income
|
| General
|
|
| Private
|
|
| Sergeant
|
|
3 rows in set (0 04 sec)
Упорядочение и группировка в сочетании с использованием функций SQL позволяет производить большой объем обработки данных на сервере до их извлечения. Но этой мощью
