Детальное описание алгоритма Шелла может быть получено, например, в [7]; здесь же отметим только, что общая идея метода состоит в сравнении на начальных стадиях сортировки пар значений, располагаемых достаточно далеко друг от друга в упорядочиваемом наборе данных. Такая модификация метода сортировки позволяет быстро переставлять далекие неупорядоченные пары значений (сортировка таких пар обычно требует большого количества перестановок, если используется сравнение только соседних элементов).
Для алгоритма Шелла может быть предложен параллельный аналог метода, если топология коммуникационный сети имеет структуру -мерного гиперкуба (т.е. количество процессоров равно ). Выполнение сортировки в таком случае может быть разделено на два последовательных этапа. На первом этапе ( итераций) осуществляется взаимодействие процессоров, являющихся соседними в структуре гиперкуба (но эти процессоры могут оказаться далекими при линейной нумерации; для установления соответствия двух систем нумерации процессоров может быть использован, как и ранее, код Грея). Второй этап состоит в реализации обычных итераций параллельного алгоритма чет-нечетной перестановки. Итерации данного этапа выполняются до прекращения фактического изменения сортируемого набора и, тем самым, общее количество таких итераций может быть различным - от 2 до . Трудоемкость параллельного варианта алгоритма Шелла определяется выражением:
,
где вторая и третья части соотношения фиксируют вычислительную сложность первого и второго этапов сортировки соответственно. Как можно заметить, эффективность данного параллельного способа сортировки оказывается лучше показателей обычного алгоритма чет-нечетной перестановки при .
..Быстрая сортировка
При кратком изложении алгоритм быстрой сортировки (полное описание метода содержится, например, в [23]) основывается на последовательном разделении сортируемого набора данных на блоки меньшего размера таким образом, что между значениями разных блоков обеспечивается отношение упорядоченности (для любой пары блоков существует блок, все значения которого будут меньше значений другого блока). На первой итерации метода осуществляется деление исходного набора данных на первые две части – для организации такого деления выбирается некоторый ведущий элемент и все значения набора, меньшие ведущего элемента, переносятся в первый формируемый блок, все остальные значения образуют второй блок набора. На второй итерации сортировки описанные правила применяются последовательно для обоих сформированных блоков и т.д. После выполнения итераций исходный массив данных оказывается упорядоченным.
Эффективность быстрой сортировки в значительной степени определяется успешностью выбора ведущих элементов при формировании блоков. В худшем случае трудоемкость метода имеет тот же порядок сложности, что и пузырьковая сортировка (т.е. ). При оптимальном выборе ведущих элементов, когда разделение каждого блока происходит на равные по размеру части, трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов сортировки ( ). В среднем случае количество операций, выполняемых алгоритмом быстрой сортировки, определяется выражением [7]:
.
Параллельное обобщение алгоритма быстрой сортировки наиболее простым способом может быть получено для вычислительной системы с топологией в виде -мерного гиперкуба (т.е. ). Пусть, как и ранее, исходный набор данных распределен между процессорами блоками одинакового размера ; результирующее расположение блоков должно соответствовать нумерации процессоров гиперкуба. Возможный способ выполнения первой итерации параллельного метода при таких условиях может состоять в следующем:
- выбрать каким-либо образом ведущий элемент и разослать его по всем процессорам системы;
- разделить на каждом процессоре имеющийся блок данных на две части с использованием полученного ведущего элемента;
- образовать пары процессоров, для которых битовое представление номеров отличается только в позиции , и осуществить взаимообмен данными между этими процессорами; в результате таких пересылок данных на процессорах, для которых в битовом представлении номера бит позиции равен 0, должны оказаться части блоков со значениями, меньшими ведущего элемента; процессоры с номерами, в которых бит равен 1, должны собрать, соответственно, все значения данных, превышающие значение ведущего элемента.
В результате выполнения такой итерации сортировки исходный набор оказывается разделенным на две части, одна из которых (со значениями меньшими, чем значение ведущего элемента) располагается на процессорах, в битовом представлении номеров которых бит равен 0. Таких процессоров всего и, таким образом, исходный -мерный гиперкуб также оказывается разделенным на два гиперкуба размерности . К этим подгиперкубам, в свою очередь, может быть параллельно применена описанная выше процедура. После -кратного повторения подобных итераций для завершения сортировки достаточно упорядочить блоки данных, получившиеся на каждом отдельном процессоре вычислительной системы. Для пояснения на рис. 4.11 представлен пример упорядочивания данных при , (т.е. блок каждого процессора содержит 4 элемента). На этом рисунке процессоры изображены в виде прямоугольников, внутри которых показано содержимое упорядочиваемых блоков данных; значения блоков приводятся в начале и при завершении каждой итерации сортировки. Взаимодействующие пары процессоров соединены двунаправленными стрелками. Для разделения данных выбирались наилучшие значения ведущих элементов: на первой итерации для всех процессоров использовалось значение 0, на второй итерации для пары процессоров 0, 1 ведущий элемент равен 4, для пары процессоров 2, 3 это значение было принято равным –5.
Эффективность параллельного метода быстрой сортировки, как и в последовательном варианте, во многом зависит от успешности выбора значений ведущих элементов. Определение общего правила для выбора этих значений не представляется возможным; сложность такого выбора может быть снижена, если выполнить упорядочение локальных блоков процессоров перед началом сортировки и обеспечить однородное распределение сортируемых данных между процессорами вычислительной системы.
Длительность выполняемых операций передачи данных определяется операцией рассылки ведущего элемента на каждой итерации сортировки - общее количество межпроцессорных обменов для этой операции на -мерном гиперкубе может быть ограничено оценкой
,
и взаимообменом частей блоков между соседними парами процессоров – общее количество таких передач совпадает с количеством итераций сортировки, т.е. равно , объем передаваемых данных не превышает удвоенного объема процессорного блока, т.е. ограничен величиной .
Вычислительная трудоемкость метода обуславливается сложностью локальной сортировки процессорных блоков, временем выбора ведущих элементов и сложностью разделения блоков, что в целом может быть выражено при помощи соотношения:
(при построении данной оценки предполагалось, что для выбора значения ведущего элемента при упорядоченности процессорных блоков данных достаточно одной операции).
Рис. 4.11. Пример упорядочивания данных параллельным методом быстрой сортировки (без результатов локальной сортировки блоков)
Математические модели в виде графов широко используются при моделировании разнообразных явлений, процессов и систем. Как результат, многие теоретические и реальные прикладные задачи могут быть решены при помощи тех или иных процедур анализа графовых моделей. Среди множества этих процедур может быть выделен некоторый определенный набор типовых алгоритмов обработки графов. Рассмотрению вопросов теории графов, алгоритмов моделирования, анализа и решения задач на графах посвящено достаточно много различных изданий, в качестве возможного руководства по данной тематике может быть рекомендована работа [8].
Пусть, как и ранее во 2 разделе пособия, есть граф
,
для которого набор вершин , , задается множеством , а список дуг графа
, ,
определяется множеством . В общем случае дугам графа могут приписываться некоторые числовые характеристики , (взвешенный граф).
Для описания графов известны различные способы задания. При малом количестве дуг в графе (т.е. ) целесообразно использовать для определения графов списки, перечисляющие имеющиеся в графах дуги. Представление достаточно плотных графов, для которых почти все вершины соединены между собой дугами (т.е. ), может быть эффективно обеспечено при помощи матрицы инцидентности
, ,
ненулевые значения элементов которой соответствуют дугам графа
Использование матрицы инцидентности позволяет использовать также при реализации вычислительных процедур для графов матричные алгоритмы обработки данных.
Далее в пособии обсуждаются параллельные способы решения двух типовых задач на графах – нахождение минимально охватывающих деревьев и поиск кратчайших путей. Для представления графов используется способ задания при помощи матриц инцидентности.
..Нахождение минимально охватывающего дерева
Охватывающим деревом (или остовом) неориентированного графа называется подграф графа , который является деревом и содержит все вершины из . Определив вес подграфа для взвешенного графа как сумму весов входящих в подграф дуг, тогда под минимально охватывающим деревом (МОД) будем понимать охватывающее дерево минимального веса. Содержательная интерпретация задачи нахождения МОД может состоять, например, в практическом примере построения локальной сети персональных компьютеров с прокладыванием наименьшего количества соединительных линий связи.
Дадим краткое описание алгоритма решения поставленной задачи, известного под названием метода Прима (Prim) [8]. Алгоритм начинает работу с произвольной вершины графа, выбираемого в качестве корня дерева, и в ходе последовательно выполняемых итераций расширяет конструируемое дерево до МОД. Пусть есть множество вершин, уже включенных алгоритмом в МОД, а величины , , характеризуют дуги минимальной длины от вершин, еще не включенных в дерево, до множества , т.е.
(если для какой либо вершины не существует ни одной дуги в , значение устанавливается в ). В начале работы алгоритма выбирается корневая вершина МОД и полагается
, .
Действия, выполняемые на каждой итерации алгоритма Прима, состоят в следующем:
- определяются значения величин для всех вершин, еще не включенные в состав МОД;
- выбирается вершина графа , имеющая дугу минимального веса до множества
;
- включение выбранной вершины в .
После выполнения итераций метода МОД будет сформировано; вес этого дерева может быть получен при помощи выражения
.
Трудоемкость нахождения МОД характеризуется квадратичной зависимостью от числа вершин графа
.
Оценим возможности для параллельного выполнения рассмотренного алгоритма нахождения минимально охватывающего дерева. Итерации метода должны выполняться последовательно и, тем самым, не могут быть распараллелены. С другой стороны, выполняемые на каждой итерации алгоритма действия являются независимыми и могут реализовываться одновременно. Так, например, определение величин может осуществляться для каждой вершины графа в отдельности, нахождение дуги минимального веса может быть реализовано по каскадной схеме и т.д.
Распределение данных между процессорами вычислительной системы должно обеспечивать независимость перечисленных операций алгоритма Прима. В частности, это может быть обеспечено, если каждая вершина графа располагается на процессоре вместе со всей связанной с вершиной информацией. Соблюдение данного принципа приводит к тому, что при равномерной загрузке каждый процессор , , будет содержать набор вершин
, , ,
соответствующий этому набору блок из величин , , и вертикальную полосу матрицы инцидентности графа из соседних столбцов, а также общую часть набора и формируемого в процессе вычислений множества вершин .
С учетом такого разделения данных итерация параллельного варианта алгоритма Прима состоит в следующем:
- определяются значения величин для всех вершин, еще не включенные в состав МОД; данные вычисления выполняются независимо на каждом процессоре в отдельности; трудоемкость такой операции ограничивается сверху величиной (на первой итерации алгоритма необходим перебор всех вершин, что требует вычислений порядка );
- выбирается вершина графа , имеющая дугу минимального веса до множества ; для выбора такой вершины необходимо осуществить поиск минимума в наборах величин , имеющихся на каждом из процессоров (количество параллельных операций ), и выполнить сборку полученных значений (длительность такой операции передачи данных на гиперкубе, например, пропорциональна величине );
- рассылка номера выбранной вершины для включения в охватывающее дерево всем процессорам (для гиперкуба сложность этой операции также определяется величиной ).
Получение МОД обеспечивается при выполнении итераций алгоритма Прима; как результат, общая трудоемкость метода определяется соотношением
.
С учетом данной оценки показатели эффективности параллельного алгоритма имеют вид:
, .
Анализ выражений показывает, что достижение асимптотически ненулевого значения показателя становится возможным при количестве процессоров, пропорциональном величине .
..Поиск кратчайших путей
Задача поиска кратчайших путей на графе состоит в нахождении путей минимального веса от некоторой заданной вершины до всех имеющихся вершин графа. Постановка подобной проблемы имеет важное практическое значение в различных приложениях, когда веса дуг означают время, стоимость, расстояние, затраты и т.п.
Возможный способ решения поставленной задачи, известный как алгоритм Дейкстры [8], практически совпадает с методом Прима. Различие состоит лишь в интерпретации и в правиле оценки вспомогательных величин , . В алгоритме Дейкстры эти величины означают суммарный вес пути от начальной вершины до всех остальных вершин графа. Как результат, после выбора очередной вершины графа для включения в множество выбранных вершин , значения величин , , пересчитываются в соответствии с новым правилом:
.
С учетом измененного правила пересчета величин , , схема параллельного выполнения алгоритма Дейкстры может быть сформирована по аналогии с параллельным вариантом метода Прима. Конкретизация такой схемы и определение показателей эффективности метода для разных топологий вычислительной системы могут рассматриваться как темы самостоятельных заданий. Для сравнения в табл. 4.2 приводятся оценки числа процессоров, при которых достигается асимптотически ненулевые значения эффективности, для топологий кольца, решетки и гиперкуба.
Таблица 4.2. Показатели эффективности алгоритмов Прима и Дейкстры для разных топологий
Основой для построения моделей функционирования программ, реализующих параллельные методы решения задач, является понятие процесса как конструктивной единицы построения параллельной программы. Описание программы в виде набора процессов, выполняемых параллельно на разных процессорах или на одном процессоре в режиме разделения времени, позволяет сконцентрироваться на рассмотрении проблем организации взаимодействия процессов, определить моменты и способы обеспечения синхронизации и взаимоисключения процессов, изучить условия возникновения или доказать отсутствие тупиков в ходе выполнения программ (ситуаций, в которых все или часть процессов не могут быть продолжены при любых вариантах продолжения вычислений).
..Концепция процесса
Понятие процесса является одним из основополагающих в теории и практике параллельного программирования. В [6,13] приводится ряд известных по литературе определений процесса. Разброс в трактовке данного понятия является достаточно широким, но в целом большинство определений сводится к пониманию процесса как "некоторой последовательности команд, претендующей наравне с другими процессами программы на использование процессора для своего выполнения".
Конкретизация понятия процесса зависит от целей исследования параллельных программ. Для анализа проблем организации взаимодействия процессов процесс можно рассматривать как последовательность команд
(для простоты изложения материала будем предполагать, что процесс описывается единственной командной последовательностью). Динамика развития процесса определяется моментами времен начала выполнения команд
,
где , , есть время начала выполнения команды . Последовательность представляет временную траекторию развития процесса. Предполагая, что команды процесса исполняются строго последовательно, в ходе своей реализации не могут быть приостановлены (т.е. являются неделимыми) и имеют одинаковую длительность выполнения, равную 1 (в тех или иных временных единицах), получим, что моменты времени траектории процесса должны удовлетворять соотношениям
.
Рис. 5.1. Диаграмма переходов процесса из состояния в состояние
Равенство достигается, если для выполнения процесса выделен процессор и после завершения очередной команды процесса сразу же начинается выполнение следующей команды. В этом случае говорят, что процесс является активным и находится в состоянии выполнения. Соотношение означает, что после выполнения очередной команды процесс приостановлен и ожидает возможности для своего продолжения. Данная приостановка может быть вызвана необходимостью разделения использования единственного процессора между одновременно исполняемыми процессами. В этом случае приостановленный процесс находится в состоянии ожидания момента предоставления процессора для своего выполнения. Кроме того, приостановка процесса может быть вызвана и временной неготовностью процесса к дальнейшему выполнению (например, процесс может быть продолжен только после завершения операции ввода-вывода). В подобных ситуациях говорят, что процесс является блокированным и находится в состоянии блокировки.
В ходе своего выполнения состояние процесса может многократно изменяться; возможные варианты смены состояний показаны на диаграмме переходов рис. 5.1.
..Понятие ресурса
Понятие ресурса обычно используется для обозначения любых объектов вычислительной системы, которые могут быть использованы процессом для своего выполнения. В качестве ресурса может рассматриваться процесс, память, программы, данные и т.п. По характеру использования могут различаться следующие категории ресурсов:
- выделяемые (монопольно используемые, неперераспределяемые) ресурсы характеризуются тем, что выделяются процессам в момент их возникновения и освобождаются только в момент завершения процессов; в качестве такого ресурса может рассматриваться, например, устройство чтения на магнитных лентах;
- повторно распределяемые ресурсы отличаются возможностью динамического запрашивания, выделения и освобождения в ходе выполнения процессов (таковым ресурсом является, например, оперативная память);
- разделяемые ресурсы, особенность которых состоит в том, что они постоянно остаются в общем использовании и выделяются процессам для использования в режиме разделения времени (как, например, процессор, разделяемые файлы и т.п.);
- многократно используемые (реентерабельные) ресурсы выделяются возможностью одновременного использования несколькими процессами (что может быть обеспечено, например, при неизменяемости ресурса при его использовании; в качестве примеров таких ресурсов могут рассматриваться реентерабельные программы, файлы, используемые только для чтения и т.д.).
Следует отметить, что тип ресурса определяется не только его конкретными характеристиками, но и зависит от применяемого способа использования. Так, например, оперативная память может рассматриваться как повторно распределяемый, так и разделяемый ресурс; использование программ может быть организовано в виде ресурса любого рассмотренного типа.
Понятие процесса может быть использовано в качестве основного конструктивного элемента для построения параллельных программ в виде совокупности взаимодействующих процессов. Такая агрегация программы позволяет получить более компактные (поддающиеся анализу) вычислительные схемы реализуемых методов, скрыть при выборе способов распараллеливания несущественные детали программной реализации, обеспечивает концентрацию усилий на решение основных проблем параллельного функционирования программ.
Рис. 5.2. Варианты взаиморасположения траекторий одновременно исполняемых процессов (отрезки линий изображают фрагменты командных последовательностей процессов)
Существование нескольких одновременно выполняемых процессов приводит к появлению дополнительных соотношений, которые должны выполняться для величин временных траекторий процессов. Возможные типовые варианты таких соотношений на примере двух процессов и состоят в следующем (см. рис. 5.2):
- выполнение процессов осуществляется строго последовательно, т.е. процесс начинает свое выполнение только после полного завершения процесса (однопрограммный режим работы ЭВМ – см. рис. 5.2а),
- выполнение процессов может осуществляться одновременно, но в каждый момент времени могут исполняться команды только какого либо одного процесса (режим разделения времени или многопрограммный режим работы ЭВМ – см. рис. 5.2б),
- параллельное выполнение процессов, когда одновременно могут выполняться команды нескольких процессов (данный режим исполнения процессов осуществим только при наличии в вычислительной системе нескольких процессоров - см. рис. 5.2в).
Приведенные варианты взаиморасположения траекторий процессов определяются не требованиями необходимых функциональных взаимодействий процессов, а являются лишь следствием технической реализации одновременной работы нескольких процессов. С другой стороны, возможность чередования по времени командных последовательностей разных процессов следует учитывать при реализации процессов. Рассмотрим для примера два процесса с идентичным программным кодом.
Процесс 1 Процесс 2
N = N + 1 N = N + 1
печать N печать N
Пусть начальное значение переменной N равно 1. Тогда при последовательном исполнении процесс 1 напечатает значение 2, процесс 2 – значение 3. Однако возможна и другая последовательность исполнения процессов в режиме разделения времени (с учетом того, что сложение N = N +1 выполняется при помощи нескольких машинных команд)
(в скобках для каждой команды указывается значение переменной N).
Как следует из приведенного примера, результат одновременного выполнения нескольких процессов, если не предпринимать специальных мер, может зависеть от порядка исполнения команд.
Выполним анализ возможных командных последовательностей, которые могут получаться для программ, образованных в виде набора процессов. Рассмотрим для простоты два процесса
, .
Командная последовательность программы образуется чередованием команд отдельных процессов и, тем самым, имеет вид:
, .
Фиксация способа образования последовательности из команд отдельных процессов может быть обеспечена при помощи характеристического вектора
,
в котором следует положить , если команда получена из процесса (иначе ). Порядок следования команд процессов в должен соответствовать порядку расположения этих команд в исходных процессах
,
где есть команда процесса , соответствующая команде в .
С учетом введенных обозначений, под программой, образованной из процессов и , можно понимать множество всех возможных командных последовательностей
.
Данный подход позволяет рассматривать программу так же, как некоторый обобщенный (агрегированный) процесс, получаемый путем параллельного объединения составляющих процессов
.
Выделенные особенности одновременного выполнения нескольких процессов могут быть сформулированы в виде ряда принципиальных положений, которые должны учитываться при разработке параллельных программ:
- моменты выполнения командных последовательностей разных процессов могут чередоваться по времени;
- между моментами исполнения команд разных процессов могут выполняться различные временные соотношения (отношения следования); характер этих соотношений зависит от количества и быстродействия процессоров и загрузки вычислительной системы и, тем самым, не может быть определен заранее;
- временные соотношения между моментами исполнения команд могут различаться при разных запусках программ на выполнение, т.е. одной и той же программе при одних и тех же исходных данных могут соответствовать разные командные последовательности вследствие разных вариантов чередования моментов работы разных процессов;
- доказательство правильности получаемых результатов должно проводиться для любых возможных временных соотношений для элементов временных траекторий процессов;
- для исключения зависимости результатов выполнения программы от порядка чередования команд разных процессов необходим анализ ситуаций взаимовлияния процессов и разработка методов для их исключения.
Перечисленные моменты свидетельствуют о существенном повышении сложности параллельного программирования по сравнению с разработкой "традиционных" последовательных программ.
..Взаимодействие и взаимоисключение процессов
Одной из причин зависимости результатов выполнения программ от порядка чередования команд может быть разделение одних и тех же данных между одновременно исполняемыми процессами (например, как это осуществляется в выше рассмотренном примере).
Данная ситуация может рассматриваться как проявление общей проблемы использования разделяемых ресурсов (общих данных, файлов, устройств и т.п.). Для организации разделения ресурсов между несколькими процессами необходимо иметь возможность:
- определения доступности запрашиваемых ресурсов (ресурс свободен и может быть выделен для использования, ресурс уже занят одним из процессов программы и не может использоваться дополнительно каким-либо другим процессом);
- выделения свободного ресурса одному из процессов, запросивших ресурс для использования;
- приостановки (блокировки) процессов, выдавших запросы на ресурсы, занятые другими процессами.
Главным требованием к механизмам разделения ресурсов является гарантированное обеспечение использования каждого разделяемого ресурса только одним процессом от момента выделения ресурса этому процессу до момента освобождения ресурса. Данное требование в литературе обычно именуется взаимоисключением процессов; командные последовательности процессов, в ходе которых процесс использует ресурс, называется критической секцией процесса. С использованием последнего понятия условие взаимоисключения процессов может быть сформулировано как требование нахождения в критических секциях по использованию одного и того же разделяемого ресурса не более чем одного процесса.
Рассмотрим несколько вариантов программного решения проблемы взаимоисключения (для записи программ используется язык программирования C++). В каждом из вариантов будет предлагаться некоторый частный способ взаимоисключения процессов с целью демонстрации всех возможных ситуаций при использовании общих разделяемых ресурсов. Последовательное усовершенствование механизма взаимоисключения при рассмотрении вариантов приведет к изложению алгоритма Деккера, обеспечивающего взаимоисключение для двух параллельных процессов. Обсуждение способов взаимоисключения завершается рассмотрением концепции семафоров Дейкстра, которые могут быть использованы для общего решение проблемы взаимоисключения любого количества взаимодействующих процессов.

 -мерного гиперкуба (т.е. количество процессоров равно
-мерного гиперкуба (т.е. количество процессоров равно  ). Выполнение сортировки в таком случае может быть разделено на два последовательных этапа. На первом этапе (
). Выполнение сортировки в таком случае может быть разделено на два последовательных этапа. На первом этапе (  таких итераций может быть различным - от 2 до
таких итераций может быть различным - от 2 до  . Трудоемкость параллельного варианта алгоритма Шелла определяется выражением:
. Трудоемкость параллельного варианта алгоритма Шелла определяется выражением: ,
, .
. итераций исходный массив данных оказывается упорядоченным.
итераций исходный массив данных оказывается упорядоченным. ). При оптимальном выборе ведущих элементов, когда разделение каждого блока происходит на равные по размеру части, трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов сортировки (
). При оптимальном выборе ведущих элементов, когда разделение каждого блока происходит на равные по размеру части, трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов сортировки (  ). В среднем случае количество операций, выполняемых алгоритмом быстрой сортировки, определяется выражением [7]:
). В среднем случае количество операций, выполняемых алгоритмом быстрой сортировки, определяется выражением [7]: .
. ; результирующее расположение блоков должно соответствовать нумерации процессоров гиперкуба. Возможный способ выполнения первой итерации параллельного метода при таких условиях может состоять в следующем:
; результирующее расположение блоков должно соответствовать нумерации процессоров гиперкуба. Возможный способ выполнения первой итерации параллельного метода при таких условиях может состоять в следующем: и, таким образом, исходный
и, таким образом, исходный  . К этим подгиперкубам, в свою очередь, может быть параллельно применена описанная выше процедура. После
. К этим подгиперкубам, в свою очередь, может быть параллельно применена описанная выше процедура. После  ,
,  (т.е. блок каждого процессора содержит 4 элемента). На этом рисунке процессоры изображены в виде прямоугольников, внутри которых показано содержимое упорядочиваемых блоков данных; значения блоков приводятся в начале и при завершении каждой итерации сортировки. Взаимодействующие пары процессоров соединены двунаправленными стрелками. Для разделения данных выбирались наилучшие значения ведущих элементов: на первой итерации для всех процессоров использовалось значение 0, на второй итерации для пары процессоров 0, 1 ведущий элемент равен 4, для пары процессоров 2, 3 это значение было принято равным –5.
(т.е. блок каждого процессора содержит 4 элемента). На этом рисунке процессоры изображены в виде прямоугольников, внутри которых показано содержимое упорядочиваемых блоков данных; значения блоков приводятся в начале и при завершении каждой итерации сортировки. Взаимодействующие пары процессоров соединены двунаправленными стрелками. Для разделения данных выбирались наилучшие значения ведущих элементов: на первой итерации для всех процессоров использовалось значение 0, на второй итерации для пары процессоров 0, 1 ведущий элемент равен 4, для пары процессоров 2, 3 это значение было принято равным –5. ,
,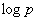 , объем передаваемых данных не превышает удвоенного объема процессорного блока, т.е. ограничен величиной
, объем передаваемых данных не превышает удвоенного объема процессорного блока, т.е. ограничен величиной  .
.

 есть граф
есть граф ,
, ,
,  , задается множеством
, задается множеством  , а список дуг графа
, а список дуг графа ,
,  ,
, . В общем случае дугам графа могут приписываться некоторые числовые характеристики
. В общем случае дугам графа могут приписываться некоторые числовые характеристики  ,
,  ) целесообразно использовать для определения графов списки, перечисляющие имеющиеся в графах дуги. Представление достаточно плотных графов, для которых почти все вершины соединены между собой дугами (т.е.
) целесообразно использовать для определения графов списки, перечисляющие имеющиеся в графах дуги. Представление достаточно плотных графов, для которых почти все вершины соединены между собой дугами (т.е.  ), может быть эффективно обеспечено при помощи матрицы инцидентности
), может быть эффективно обеспечено при помощи матрицы инцидентности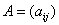 ,
, 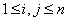 ,
,
 графа
графа  есть множество вершин, уже включенных алгоритмом в МОД, а величины
есть множество вершин, уже включенных алгоритмом в МОД, а величины  ,
, 
 не существует ни одной дуги в
не существует ни одной дуги в  ). В начале работы алгоритма выбирается корневая вершина МОД
). В начале работы алгоритма выбирается корневая вершина МОД  и полагается
и полагается ,
,  .
. графа
графа  ;
; итераций метода МОД будет сформировано; вес этого дерева может быть получен при помощи выражения
итераций метода МОД будет сформировано; вес этого дерева может быть получен при помощи выражения .
. ,
,  , будет содержать набор вершин
, будет содержать набор вершин ,
,  ,
,  ,
, величин
величин  и формируемого в процессе вычислений множества вершин
и формируемого в процессе вычислений множества вершин  (на первой итерации алгоритма необходим перебор всех вершин, что требует вычислений порядка
(на первой итерации алгоритма необходим перебор всех вершин, что требует вычислений порядка  );
); итераций алгоритма Прима; как результат, общая трудоемкость метода определяется соотношением
итераций алгоритма Прима; как результат, общая трудоемкость метода определяется соотношением .
. ,
,  .
.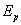 становится возможным при количестве процессоров, пропорциональном величине
становится возможным при количестве процессоров, пропорциональном величине  .
. .
.
 ,
, ,
,  , есть время начала выполнения команды
, есть время начала выполнения команды  представляет временную траекторию развития процесса. Предполагая, что команды процесса исполняются строго последовательно, в ходе своей реализации не могут быть приостановлены (т.е. являются неделимыми) и имеют одинаковую длительность выполнения, равную 1 (в тех или иных временных единицах), получим, что моменты времени траектории процесса должны удовлетворять соотношениям
представляет временную траекторию развития процесса. Предполагая, что команды процесса исполняются строго последовательно, в ходе своей реализации не могут быть приостановлены (т.е. являются неделимыми) и имеют одинаковую длительность выполнения, равную 1 (в тех или иных временных единицах), получим, что моменты времени траектории процесса должны удовлетворять соотношениям .
.
 достигается, если для выполнения процесса выделен процессор и после завершения очередной команды процесса сразу же начинается выполнение следующей команды. В этом случае говорят, что процесс является активным и находится в состоянии выполнения. Соотношение
достигается, если для выполнения процесса выделен процессор и после завершения очередной команды процесса сразу же начинается выполнение следующей команды. В этом случае говорят, что процесс является активным и находится в состоянии выполнения. Соотношение  означает, что после выполнения очередной команды процесс приостановлен и ожидает возможности для своего продолжения. Данная приостановка может быть вызвана необходимостью разделения использования единственного процессора между одновременно исполняемыми процессами. В этом случае приостановленный процесс находится в состоянии ожидания момента предоставления процессора для своего выполнения. Кроме того, приостановка процесса может быть вызвана и временной неготовностью процесса к дальнейшему выполнению (например, процесс может быть продолжен только после завершения операции ввода-вывода). В подобных ситуациях говорят, что процесс является блокированным и находится в состоянии блокировки.
означает, что после выполнения очередной команды процесс приостановлен и ожидает возможности для своего продолжения. Данная приостановка может быть вызвана необходимостью разделения использования единственного процессора между одновременно исполняемыми процессами. В этом случае приостановленный процесс находится в состоянии ожидания момента предоставления процессора для своего выполнения. Кроме того, приостановка процесса может быть вызвана и временной неготовностью процесса к дальнейшему выполнению (например, процесс может быть продолжен только после завершения операции ввода-вывода). В подобных ситуациях говорят, что процесс является блокированным и находится в состоянии блокировки.
 состоят в следующем (см. рис. 5.2):
состоят в следующем (см. рис. 5.2):
 .
. ,
,  .
. из команд отдельных процессов может быть обеспечена при помощи характеристического вектора
из команд отдельных процессов может быть обеспечена при помощи характеристического вектора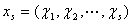 ,
, , если команда
, если команда  получена из процесса
получена из процесса  (иначе
(иначе  ). Порядок следования команд процессов в
). Порядок следования команд процессов в  ,
, есть команда процесса
есть команда процесса  , можно понимать множество всех возможных командных последовательностей
, можно понимать множество всех возможных командных последовательностей .
. .
.