Наследование является одной из главных особенностей объектно-ориентированного программирования. В С++ наследование поддерживается за счет того, что одному классу разрешается при своем объявлении включать в себя другой класс. Наследование позволяет построить иерархию классов от более общего к более частным. Этот процесс включает в себя определение базового класса, определяющего общие качества всех объектов, которые будут выведены затем из базового класса. Базовый класс представляет собой наиболее общее описание. Выведенные из базового класса классы обычно называют производными классами.
Общая форма записи наследования имеет следующий вид
class имя_нового_класса: спецификатор_доступа наследуемый_класс{
// тело нового класса
};
Использование спецификатора доступа факультативно.
Прежде всего, необходимо коснуться терминологии. Класс, который наследуется другим классом, называются базовым классом. Иногда его также называют родительским классом. Класс, выполняющий наследование, называется производным классом или потомком.
Спецификаторы доступа
В С++ члены класса классифицируются в соответствии с правами доступа на следующие три категории: публичные (public), частные (private) и защищённые (protected). Любая функция программы имеет доступ к публичным членам. Доступ к частному члену имеют только функции-члены класса или функции-друзья класса. Защищённые члены аналогичны частным членам. Разница между ними проявляется только при наследовании классов.
Частные члены базового класса не доступны внутри производного класса.
Например
class X {
int i;
int j;
public:
void get_ij();
void put_ij();
};
class Y: public X {
int k;
public:
int get_k();
void make_k();
};
Класс Y наследует и имеет доступ к публичным функциям get_ij() и put_ij() класса Х, но не имеет доступа к i и j, поскольку они являются частными членами Х.
Для того, чтобы оставить член частным и разрешить использовать его производным классам используется ключевое слово – protected.
Пример
class X {
protected:
int i;
int j;
public:
void get_ij();
void put_ij();
};
class Y: public X {
int k;
public:
int get_k();
void make_k();
};
Здесь класс Y имеет доступ к i и j, и в то же время они остаются недоступными для другой части программы.
Спецификатор доступа при наследовании базового класса
От того, с каким спецификатором доступа объявляется наследование базового класса, зависит статус доступа к членам производного класса. Общая форма наследования классов имеет следующий вид:
class имя_класса: доступ имя_класса { ... };
Здесь доступ определяет, каким способом наследуется базовый класс. Спецификатор доступ может принимать три значения – private, public, protected. В случае если спецификатор доступа опущен, то по умолчанию подразумевается на его месте спецификатор public. Если спецификатор доступ принимает значение public, то все публичные и защищённые члены базового класса становятся соответственно публичными и защищёнными членами производного класса. Если доступ private, то все публичные и защищённые члены базового класса становятся частными членами производного класса. Если спецификатор доступа protected, то все публичные и защищённые члены базового класса становятся защищёнными членами производного класса. Рассмотрим пример:
#include <iostream>
using namespace std;
class X {
protected:
int i;
int j;
public:
void get_ij(){
cout << "Enter two numbers ";
cin >> i >> j;
}
void put_ij(){ cout << i << " " << j << "\n";}
};
// В классе Y, i и j класса X становятся защищёнными членами
class Y: public X {
int k;
public:
int get_k(){ return k;}
void make_k(){ k=i*j;}
};
// Класс Z имеет доступ к i и j класса X, но не к
// k класса Y, поскольку он является частным
class Z: public Y {
public:
void f();
};
// i и j доступны отсюда
void Z::f()
{
i=2;
j=3;
}
int main()
{
Y var;
Z var2;
var.get_ij();
var.put_ij();
var.make_k();
cout << var.get_k();
cout << "\n";
var2.f();
var2.put_ij();
return 0;
}
Поскольку класс Y наследует класс X со спецификатором доступа public, то защищённые элементы класса X становятся защищёнными элементами класса Y. Это означает, что они могут далее наследоваться классом Z, и эта программа будет откомпилирована и выполнена корректно. Однако, если изменить статус X при объявлении Y на private, то класс Z не имеет доступа к i, j и функциям get_ij() и put_ij(), поскольку они стали частными членами Y.
28. Конструкторы и деструкторы производных классов
Как базовый класс, так и производный класс могут иметь конструкторы. Когда базовый класс имеет конструктор, этот конструктор исполняется перед конструктором производного класса.
Конструкторы вызываются в том же самом порядке, в каком классы следуют один за другим в иерархии классов. Поскольку базовый класс ничего не знает про свои производные классы, то его инициализация может быть отделена от инициализации производных классов и производится до их создания, так что конструктор базового класса вызывается перед вызовом конструктора производного класса.
В противоположность этому деструктор производного класса вызывается перед деструктором базового класса.
29. Множественное наследование. Передача параметров в конструктор базового класса
Когда базовый класс имеет конструктор с аргументами, производные классы должны передавать базовому классу необходимые аргументы. Для этого используется расширенная форма конструкторов производных классов.
Здесь под базовый1, базовый2, …, базовыйN обозначены имена базовых классов, наследуемые производным классом. Обратим вниманием, что с помощью двоеточия конструктор производного класса отделяется от списка конструкторов базового класса. Список аргументов, ассоциированный с базовыми классами, может состоять из констант, глобальных переменных или параметров конструктора производного класса.
30. Указатели и ссылки на производные типы
В общем случае указатель одного типа не может указывать на объект другого типа. Из этого правила есть исключение, которое относится только к производным классам. В С++ указатель на базовый класс может указывать на объект производного класса. Ссылки на базовый класс могут быть использованы для ссылок на объект производного типа.
31. Виртуальные функции
Виртуальная функция – это функция, объявленная с ключевым словом virtual в базовом классе и переопределенная в производных классах. Виртуальные функции являются особыми функциями, потому что при вызове объекта производного класса с помощью указателя или ссылки на него С++ определяет во время исполнения программы, какую функцию вызвать, основываясь на типе объекта. Для разных объектов вызываются разные версии одной и той же виртуальной функции. Класс, содержащий одну или более виртуальных функций, называется полиморфным классом.
Пример использования виртуальных функций
#include <iostream>
using namespace std;
class Base {
public:
virtual void who(){// определение виртуальной функции
cout << "Base\n";
}
};
class first_d: public Base {
public:
void who(){// определение who применительно к first_d
cout << "First derivation\n";
}
};
class second_d: public Base {
void who(){// определение who применительно к second_d
cout << "Second derivation\n";
}
};
int main()
{
Base base_obj;
Base *p;
first_d first_obj;
second_d second_obj;
p = &base_obj;
p->who();
p = &first_obj;
p->who();
p = &second_obj;
p->who();
return 0;
}
Наиболее распространённым способом вызова виртуальной функции служит использование параметра функции.
Пример
/* Здесь ссылка на базовый класс используется для доступа
к виртуальной функции */
#include <iostream>
using namespace std;
class Base {
public:
virtual void who(){// определение виртуальной функции
cout << "Base\n";
}
};
class first_d: public Base {
public:
void who(){// определение who применительно к first_d
cout << "First derivation\n";
}
};
class second_d: public Base {
void who(){// определение who применительно к second_d
cout << "Second derivation\n";
}
};
// использование в качестве параметра ссылки на базовый класс
void show_who(Base &r) {
r.who();
}
int main()
{
Base base_obj;
first_d first_obj;
second_d second_obj;
show_who(base_obj);
show_who(first_obj);
show_who(second_obj);
return 0;
}
Для чего нужны виртуальные функции?
Виртуальные функции в комбинации с производными типами позволяют С++ поддерживать полиморфизм времени исполнения. Этот полиморфизм важен для ООП, поскольку он позволяет переопределять функции базового класса в классах потомках с тем, чтобы иметь их версию применительно к данному конкретному классу. Таким образом, базовый класс определяет общий интерфейс, который имеют все производные от него классы, и вместе с тем полиморфизм позволяет производным классам иметь свои собственные реализации методов. Благодаря этому полиморфизм часто определяют фразой «один интерфейс – множество методов».
Успешное применение полиморфизма связано с пониманием того, что базовые и производные классы образуют иерархию, в которой переход от базового к производному классу отвечает переходу от большей к меньшей общности.
Пример
#include <iostream>
using namespace std;
class figure {
protected:
double x, y;
public:
void set_dim(double i, double j) {
x = i; y = j;
}
virtual void show_area() {
cout << "No area computation defined ";
cout << "for this class.\n";
}
};
class triangle: public figure {
public:
void show_area() {
cout << "Triangle with height ";
cout << x << " and base " << y;
cout << " has an area of ";
cout << x*0.5*y << ".\n";
}
};
class square: public figure {
public:
void show_area() {
cout << "Square with dimensions ";
cout << x << "x" << y;
cout << " has an area of ";
cout << x*y << ".\n";
}
};
int main()
{
figure *p;
triangle t;
square s;
p = &t;
p->set_dim(10.0, 5.0);
p->show_area();
p = &s;
p->set_dim(10.0, 5.0);
p->show_area();
return 0;
}
32. Чисто виртуальные функции и абстрактные типы
Когда виртуальная функция не переопределена в производном классе, то при вызове её в объекте производного класса вызывается версия из базового класса. Однако во многих случаях невозможно ввести содержательное определение виртуальной функции в базовом классе. Есть два способа действий в этой ситуации. Первый заключается в выводе какого-либо предупреждающего сообщения. Но этот способ не универсален, поскольку информация о том, что функция не переопределена, проявится на этапе выполнения. Необходим метод, гарантирующий, что производные классы действительно определят все необходимые функции. В качестве решения этой проблемы используются чисто виртуальные функции.
Чисто виртуальная функция является функцией, которая объявляется в базовом классе, но не имеет в нём определения. Поскольку она не имеет определения в базовом классе, то всякий производный класс обязан иметь свою собственную версию определения. Синтаксис:
virtual тип имя_функции(список_параметров) = 0;
Пример, следующая версия функции show_area() класса figure является чисто виртуальной функцией.
class figure {
protected:
double x, y;
public:
void set_dim(double i, double j=0) {
x = i;
y = j;
}
virtual void show_area() = 0;
};
При введении чисто виртуальной функции в производном классе обязательно необходимо определить свою собственную реализацию этой функции.
Пример, если попытаться откомпилировать эту версию программы, то будет выдана ошибка:
#include <iostream>
using namespace std;
class figure {
protected:
double x, y;
public:
void set_dim(double i, double j=0) {
x = i;
y = j;
}
virtual void show_area() = 0;
};
class triangle: public figure {
public:
void show_area() {
cout << "Triangle with height ";
cout << x << " and base " << y;
cout << " has an area of ";
cout << x*0.5*y << ".\n";
}
};
class square: public figure {
public:
void show_area() {
cout << "Square with dimensions ";
cout << x << "x" << y;
cout << " has an area of ";
cout << x*y << ".\n";
}
};
class circle: public figure {
// определение show_area() отсутствует и поэтому
// выдаётся ошибка
};
int main()
{
figure *p;
triangle t;
square s;
p = &t;
p->set_dim(10.0, 5.0);
p->show_area();
p = &s;
p->set_dim(10.0, 5.0);
p->show_area();
return 0;
}
Если какой-либо класс имеет хотя бы одну чисто виртуальную функцию, то такой класс называется абстрактным. Важной особенностью абстрактных классов является то, что не существует ни одного объекта данного класса. Абстрактный класс служит базовым для других классов. Даже если базовый класс является абстрактным, всё равно можно объявлять указатели или ссылки на него, с помощью которых затем поддерживается полиморфизм времени исполнения.
33. Раннее и позднее связывание
Раннее связывание означает, что объект и вызов функции связываются между собой на этапе компиляции. Это означает, что вся необходимая информация для того, чтобы определить, какая именно функция будет вызвана, известна на этапе компиляции программы. В качестве примеров можно указать стандартные вызовы функций, вызовы перегруженных функций и перегруженных операторов.
Позднее связывание означает, что объект связывается с вызовом функции только во время исполнения программы, а не раньше. Позднее связывание достигается в С++ с помощью использования виртуальных функций и производных классов. Его достоинством является высокая гибкость.
34. Классы потоков С++
С++ обеспечивает поддержку ввода-вывода в заголовочном файле iostream. Поскольку используются стандартные классы-шаблоны, необходима инструкция using namespace std. В файле iostream определены 2 иерархии классов, поддерживающие операции ввода-вывода. Класс нижнего уровня - streambuf. Этот класс обеспечивает базовые операции ввода-вывода. До тех пор пока не вводятся свои собственные классы ввода-вывода, непосредственно streambuf не используется. Вторая иерархия классов начинается с ios. Он обеспечивает поддержку форматированного ввода-вывода. От него порождены классы istream, ostream и iostream. Эти классы использованы для создания потоков, способных осуществлять ввод, вывод и ввод-вывод соответственно. От класса ios порождено много других классов, поддерживающих файлы на диске и форматирование в памяти.
Класс ios содержит много функций-членов и переменных, которые управляют фундаментальными операциями с потоками. Надо иметь ввиду, что если использовать систему ввода-вывода С++ обычным образом, то члены класса ios будут доступны для использования любым потоком.
35. Создание собственных операторов вставки и извлечения.
Создание операторов вставки
В С++ имеется лёгкий способ определения оператора вставки для создаваемых классов.
Обратим внимание на необходимость возвращать поток. Также является приемлимым и, более того, является общей практикой использовать в качестве параметра объект ссылку, а не сам объект. Во-первых, если объект является большим, то гораздо быстрее передать его адрес. Во-вторых, это предотвращает вызов деструктора объекта, когда функция возвращает результат.
В программе-примере перегруженная функция вставки не является членом класса three_d. Действительно, ни функция вставки, ни функция извлечения не могут быть членами класса. При перегрузке оператора вставки левым аргументом является поток, а правым аргументом – объект класса. Поэтому перегруженные операторы вставки не могут быть функциями-членами. Чтобы получить доступ к частным и защищённым членам класса оператор вставки должен быть другом класса. В качестве друга класса, для которого он определён, он имеет доступ к частным данным.
В заголовочном файле iostream определены флаги форматирования, которые можно всегда найти в справочниках. Эти значения используются для установки или сброса флагов, управляющих форматированием информации потоков.
Для установки флагов используется функция setf(), чей прототип имеет вид:
long setf(long flags);
Эта функция возвращает предыдущее значение флага, устанавливая его новое значение равным flags. При этом остальные флаги остаются неизменными.
Пример
stream.setf(ios::showpos);
Здесь stream является потоком, на который надо оказать воздействие.
Пример
#include <iostream>
using namespace std;
int main()
{
cout.setf(ios::showpos);
cout.setf(ios::scientific);
cout << 123 << " " << 123.23 << " ";
getchar();
return 0;
}
Данная программа выводит на экран
+123 +1.232300е+002
Для отключения флагов надо использовать функцию unsetf(). Она имеет следующий прототип:
long unsetf(long flags);
Функция возвращает значение предыдущей установки флага и сбрасывает флаги, определяемые параметром flags.
Иногда бывает полезным знать текущую установку флагов. Для этого служит функция flags(). Прототип:
long flags();
Кроме флага форматирования также можно установить ширину поля потока, символ для заполнения и число цифр после запятой. Для этого используются следующие функции:
int width(int len);
char fill(char ch);
int precision(int num);
Использование манипуляторов
Для использования манипуляторов с параметрами в программу необходимо включить файл iomanip.
Табл. 1
Манипулятор
Назначение
Ввод-вывод
dec
Ввод-вывод данных в десятичной форме
ввод и вывод
endl
Вывод символа новой строки с передачей в поток всех данных из буфера
вывод
ends
Вывод нулевого символа
вывод
flush
Передача в поток содержимого буфера
вывод
hex
Ввод-вывод данных в шестнадцатеричной системе
ввод и вывод
oct
Ввод-вывод данных в восьмеричной системе
ввод и вывод
resetiosflags(long f)
Сбрасывает флаги, указанные в f
ввод и вывод
setbase(int base)
Устанавливает базу счисления равной параметру base
вывод
setfill(int ch)
Устанавливает символ заполнения равным ch
вывод
setiosflags(long f)
Устанавливает флаги, указанные в f
ввод и вывод
setprecision(int p)
Устанавливает число цифр после запятой
вывод
setw(int w)
Устанавливает ширину поля равной w
вывод
ws
Пропускает начальный символ разделитель
ввод
Пример
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
cout << setiosflags(ios::fixed);
cout << setprecision(2) << 1000.243 << endl;
cout << setw(20) << "Hello there.";
getchar();
return 0;
}
Программа выдаст на консоль:
1000.24
Hello there.
37. Файловый ввод-вывод
38. Чтение и запись в текстовые файлы
Для выполнения файлового ввода-вывода в программу необходимо включить заголовочный файл fstream и дать команду using namespace std;.
Открытие и закрытие файлов
В С++ файл открывается путём состыковки его с потоком. Имеется три типа потоков: ввода, вывода и ввода-вывода. Для открытия потока ввода необходимо объявить его как объект класса ifstream. Для открытия потока вывода необходимо объявить его как объект класса оfstream. Потоки, которые выполняют как ввод, так и вывод, должны быть объявлены как объекты класса fstream. Например, следующий фрагмент программы создаёт один поток ввода, один поток вывода и один поток, способный выполнять как ввод, так и вывод:
ifstream in;
ofstream out;
fstream both;
После создания потока единственным способом ассоциировать его с файлом является использование функции open(). Эта функция является членом каждого из трёх классов потоков. Она имеет следующий прототип:
void open(const char *filename, int mode, int access=filebuf::openprot);
Здесь filename является именем файла и может включать указание пути. Величина mode определяет, каким способом открывается файл. Mode может принимать одно или более из следующих значений, (определённых в заголовочном файле fstream):
ios::app
ios::ate
ios::binary
ios::in
ios::nocreate
ios::noreplace
ios::out
ios::trunc
Можно комбинировать два и более из этих значений, используя побитовое ИЛИ.
ios::app указывает на то, что выводимые данные будут добавляться в конец файла. Это значение может быть использовано только для файлов, для которых возможен вывод. Использование ios::ate вызывает поиск конца файла в момент открытия файла.
ios::in задаёт возможность ввода из файла, ios::out указывает, что файл предназначен для вывода. Однако создание потока с использованием ifstream задаёт режим ввода, а создание потока с использованием оfstream задаёт режим вывода, и в этих случаях нет необходимости задавать указанные выше величины.
ios::nocreate задаёт такой режим, при котором функция open() может открыть только существующий файл. ios::noreplace не позволяет открыть файл функции open(), если файл уже существует, но не указаны атрибуты ios::ate или ios::app.
ios::trunc обусловливает уничтожение содержимого файла с заданным именем и усечение длины файла до нуля.
ios::binary обусловливает открытие файла для двоичных операций. Это означает, что не будет никаких преобразований символов.
Величина access определяет, каким образом осуществляется доступ к файлу. Обычно эти атрибуты оставляются по умолчанию, что соответствует нормальному файлу.
В следующем фрагменте открывается нормальный файл для вывода
ofstream out;
out.open(“test”, ios::out);
Тем не менее, практически никогда не бывает подобного вызова функции open(), поскольку второй параметр имеет значение по умолчанию. Поэтому предыдущая инструкция будет выглядеть следующим образом:
out.open(“test”);
Для того чтобы открыть поток одновременно для ввода и вывода, необходимо задать обе величины ios::out и ios::in для режима mode, как показано в следующем примере:
fstream mystream;
mystream.open(“test”, ios::in | ios::out);
Если функции open( ) не удаётся открыть поток, то поток останется равным NULL.
Хотя открытие файла с использованием функции open( ) является вполне допустимым, в большинстве случаев так не делается, потому что класс ifstream, ofstream и fstream содержат конструкторы, открывающие файл. Конструкторы имеют те же параметры и значения по умолчанию, что и функция open( ). Поэтому наиболее типичный способ открытия файла выглядит следующим образом:
ifstream mystream(“myfile”);
Можно использовать следующий код для того, чтобы убедится, что файл действительно открыт:
ifstream mystream(“myfile”);
if (!mystream) {
cout << “Cannot open file.\n”;
// обработка ошибки
}
Для того, чтобы закрыть файл, следует использовать функцию-член close( ). Например, чтобы закрыть файл, состыкованный с потоком mystream, используется следующая инструкция:
mystream.close();
Определение конца файла
Для определения момента достижения конца файла можно использовать функцию-член eof(), имеющую следующий прототип:
int eof();
При достижении конца файла она возвращает ненулевое число, в противном случае возвращает ноль.
Для того чтобы писать в текстовые файлы или читать из них, достаточно воспользоваться операциями << и >> для открытого потока. Например, следующая программа записывает целое число, число с плавающей точкой и строку в файл test:
#include <iostream>
#include <fstream>
using namespace std;
int main( )
{
ofstream out("test");
if(!out) {
cout << "Cannot open file.\n";
return 1;
}
out << 10 << " " << 123.23 << "\n";
out << "This is a short text file.\n";
out.close( );
return 0;
}
Следующая программа читает целое число, число с плавающей точкой, символ и строку из файла, созданного предыдущей программой.
#include <iostream>
#include <fstream>
using namespace std;
int main( )
{
char ch;
int i;
float f;
char str[80];
ifstream in(“test”);
if (!in) {
cout << “Cannot open file.\n”;
return 1;
}
in >> i;
in >> f;
in >> ch;
in >> str;
in.close();
return 0;
}
39. Двоичные файлы
Имеется несколько способов для записи двоичных данных в файл и чтения из файла. В первую очередь, можно записать байт с помощью функции-члена put() и прочитать байт, используя функцию-член get(). Функция get() имеет много форм, но наиболее употребительна показанная ниже версия, где приведена также функция put():
istream &get(char &ch);
ostream &put(char ch);
Функция get() читает единственный символ из ассоциированного потока и помещает его значение в ch. Она возвращает ссылку на поток. Функция put() пишет ch в поток и возвращает ссылку на этот поток.
Следующая программа выводит содержимое любого файла на экран.
Пример
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if (argc!=2) {
cout << "Bad command line!";
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if (!in) {
cout << "Cannot open file.\n";
return 1;
}
while (in) {
in.get(ch);
cout << ch;
}
system("pause");
in.close();
return 1;
}
Следующая программа использует функция put() для записи строки, содержащей не ASCII-символы.
Пример
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char *p="hello there\n\r\xfe\xff";
ofstream out("test", ios::out|ios::binary);
if(!out) {
cout << "Cannot open file.\n";
return 1;
}
while(*p) out.put(*p++);
out.close();
return 0;
}
Второй способ чтения и записи двоичных данных состоит в использовании функций read() и write(). Наиболее обычный способ использования этих функций соответствует прототипу:
istream &read(unsigned char *buf, int num);
ostream &write(const unsigned *buf, int num);
Функция read() читает num байт из ассоциированного потока и посылает их в буфер buf. Функция write() пишет num байт в ассоциированный поток из буфера buf.
Следующая программа пишет и потом читает массив целых чисел:
Пример
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
int n[5]={1, 2, 3, 4, 5};
register int i;
ofstream out("test", ios::out | ios::binary);
if(!out) {
cout << "Cannot open file.\n";
return 1;
}
out.write((const char *) &n, sizeof n);
out.close();
for (i=0; i<5; i++)
n[i]=0;
ifstream in("test", ios::in | ios::binary);
in.read((char *) &n, sizeof n);
for(i=0; i<5; i++)
cout << n[i] << " ";
in.close();
return 0;
}
Следует обратить внимание, что приведение типов в вызовах read() и write() необходимо для работы с буфером, который не определён как массив символов.
Если конец файла достигается до того, как будет прочитано заданное число символов, функция read() просто прекращает работу и буфер содержит столько символов, сколько было прочитано. Можно определить, сколько символов было прочитано, используя другую функцию-член gcount(), имеющую следующий прототип:
int gcount();
Она возвращает число символов, прочитанных последним оператором двоичного ввода.
40. Функции-шаблоны
Функция-шаблон определяет общий набор операций, который будет применён к данным различных типов. Используя этот механизм, можно применять некоторые общие алгоритмы к широкому кругу данных. Как известно, многие алгоритмы логически одинаковы вне зависимости от типа данных, с которыми они оперируют. Например, алгоритм быстрой сортировки один и тот же и для массива целых чисел и для массива чисел с плавающей точкой. При помощи создания функции-шаблона можно определить сущность алгоритма безотносительно к типу данных. После этого компилятор автоматически генерирует корректный код для того типа данных, для которого создаётся данная конкретная реализация функции на этапе компиляции.
Функции-шаблоны создаются с использованием ключевого слова template (шаблон). Шаблон используется для создания каркаса функции, оставляя компилятору реализацию подробностей. Общая форма функции-шаблона имеет следующий вид:
Здесь Т является параметром-типом, «держателем места» для имени типа данных, которое используется функцией. Этот параметр-тип может быть использован в определении функции. Он будет автоматически заменён компилятором на фактический тип данных во время создания конкретной версии функции.
Листинг 1
// пример шаблона функции
#include <iostream>
using namespace std;
// шаблон функции
template <class X> void Swap(X &a, X &b)
{
X temp;
temp=a;
a=b;
b=temp;
}
int main()
{
int i=10, j=20;
double x=10.1, y=23.3;
char a='x', b='z';
cout<<"Original i, j: "<< i << " " << j << "\n";
cout<<"Original x, y: "<< x << " " << y << "\n";
cout<<"Original a, b: "<< a << " " << b << "\n";
Swap(i, j);
Swap(x, y);
Swap(a, b);
cout<<"Swapped i, j: " << i << " " << j << "\n";
cout<<"Swapped x, y: " << x << " " << y << "\n";
cout<<"Swapped a, b: " << a << " " << b << "\n";
return 0;
}
Можно определить несколько типов-шаблонов данных в инструкции template, используя список с запятыми в качестве разделителя. Например, следующая программа создаёт функцию-шаблон имеющую два типа-шаблона.
Листинг 2
#include <iostream>
using namespace std;
template <class type1, class type2> void myfunc(type1 x, type2 y)
{
cout << x << " " << y << endl;
}
int main()
{
myfunc(10, "hi");
myfunc(0.23, 10L);
return 0;
}
Явная перегрузка функций-шаблонов
Хотя функция-шаблон перегружает себя по мере необходимости, также можно перегрузить её явным образом. Если перегружается функция – шаблон, то перегруженная функция переопределяет функцию шаблон для того конкретного набора типов параметров, для которых создаётся перегруженная функция. В качестве примера рассмотрим следующую версию функции swap().
Листинг 3
// перегрузка функции-шаблона
#include <iostream>
using namespace std;
// шаблон функции
template <class X> void Swap(X &a, X &b)
{
X temp;
temp=a;
a=b;
b=temp;
}
// отдельная версия Swap()
void Swap(int &a, int &b)
{
int temp;
temp=a;
a=b;
b=temp;
cout << "Inside overloaded Swap().\n";
}
int main()
{
int i=10, j=20;
double x=10.1, y=23.3;
char a='x', b='z';
cout << "Original i, j: " << i << " " << j << "\n";
cout << "Original x, y: " << x << " " << y << "\n";
cout << "Original a, b: " << a << " " << b << "\n";
Swap(i, j);
Swap(x, y);
Swap(a, b);
cout << "Swapped i, j: " << i << " " << j << "\n";
cout << "Swapped x, y: " << x << " " << y << "\n";
cout << "Swapped a, b: " << a << " " << b << "\n";
return 0;
}
Ограничения на функции-шаблоны
Функции-шаблоны сходны с перегруженными функциями, за исключением того, что они более ограничены. Для перегруженных функций можно выполнять различные действия в теле каждой функции. Для функции-шаблона необходимо выполнять одни и те же общие действия, и только тип данных может быть различным.
Пример (перегруженные функции не могут быть заменены на функцию-шаблон)
#include <iostream>
#include <math.h>
using namespace std;
void myfunc(int i)
{
cout << "value is: " << i << "\n";
}
void myfunc(double d)
{
double intpart;
double fracpart;
fracpart = modf(d, &intpart);
cout << "fractional part: " << fracpart;
cout << "\n";
cout << "Integer part: " << intpart;
}
int main()
{
myfunc(1);
myfunc(12.2);
return 0;
}
Другим ограничением на классы-шаблоны является то, что виртуальная функция не может быть функцией-шаблоном.
41. Классы-шаблоны
Кроме функций – шаблонов можно также определить классы – шаблоны. Для этого следует создать класс, определяющий все алгоритмы, но фактический тип данных является параметром, определяющимся при создании класса.
Общая форма объявления класса – шаблона приведена ниже:
template <class T> class имя_класса {
…
};
Здесь T является параметром – типом, который будет указан при создании объекта класса. При необходимости можно определить несколько типов – шаблонов, используя список и запятую в качестве разделителя.
После создания класса – шаблона можно создать конкретный экземпляр класса и объекты этого класса, использую общую форму:
имя_класса <тип> объект;
Здесь тип является именем типа данных, с которым будет оперировать данный класс.
Функции – члены класса – шаблона являются сами по себе автоматически шаблонами.
В следующей программе создаётся класс – шаблон stack, реализующий стандартный стек «последним вошёл – первым вышел». Он может использоваться для реализации стека с произвольным типом данных.
Класс-шаблон может иметь несколько типов-шаблонов. Достаточно объявить все типы-шаблоны в виде списка, разделённого запятыми.
// используются два типа-параметра
#include <iostream>
using namespace std;
template <class Type1, class Type2> class Myclass
{
Type1 i;
Type2 j;
public:
Myclass(Type1 a, Type2 b){ i=a; j=b; }
void show(){cout << i << " " << j << "\n";}
};
int main()
{
Myclass<int, double> ob1(10, 0.23);
Myclass<char, char *> ob2('X', "This is a test");
ob1.show();
ob2.show();
return 0;
}
42. Использование пространства имён
Поскольку пространства с глобальной областью видимости добавляются к системе, то имеется возможность коллизии имён. Это становится особенно актуальным при использовании библиотек, разработанных различными независимыми производителями. Использование namespace позволяет разбить глобальное пространство имён для того, чтобы решить проблему.
Общая форма namespace следующая:
namespace имя{
// объявление объекта
}
Пример
namespace MyNameSpace {
int i, k;
void myfunc(int j) {cout << j;}
}
Здесь i, k и myfunc() составляют область видимости пространства имён MyNameSpace.
Поскольку пространство имён определяет область видимости, то для ссылки на объекты, определённые в пространстве имён, необходимо использовать оператор области видимости. Например:
MyNameSpace::i =10;
Если элементы области видимости будут использоваться часто, то можно использовать директиву using для упрощения доступа к ним. Инструкция using имеет две общие формы записи:
using namespace имя;
using имя::член;
В первом случае имя определяет пространство имён, к которому нужно получить доступ. Все члены, определённые в указанном пространстве имён, могут быть использованы без оператора области видимости. Во втором варианте только указанные члены пространства имён становятся видимыми. Например, для определённого выше пространства имен MyNameSpace следующее использование инструкции using является корректным:
using MyNameSpace::k; // видим только k
k = 10; // допустимо, поскольку k видим
using namespace MyNameSpace; // все члены MyNameSpace видимы
i = 10;
43. Контейнерные классы
Контейнерные классы – это классы, предназначенные для хранения данных, организованных определенным образом. Примерами контейнеров могут служить массивы, очереди или стеки. Для каждого типа контейнера определены методы для работы с его элементами, не зависящие от конкретного типа данных, которые хранятся в контейнере. Эта возможность реализована с помощью шаблонов классов, поэтому часть библиотеки С++ называют стандартной библиотекой шаблонов (STL – standart template library).
Использование контейнеров позволяет значительно повысить надежность программ, их переносимость и универсальность, а также уменьшить сроки их разработки.
STL содержит контейнеры, реализующие основные структуры данных, используемые при написании программ – векторы, двусторонние очереди, списки и их разновидности, словари и множества. Контейнеры можно разделить на два типа: последовательные и ассоциативные.
Последовательные контейнеры обеспечивают хранение конечного количества однотипных величин в виде непрерывной последовательности. К ним относятся векторы (vector), двусторонние очереди (deque) и списки (list), а также так называемые адаптеры, то есть варианты, контейнеров – стеки (stack), очереди (queue) и очереди с приоритетами (priority_queue).
Каждый вид контейнера обеспечивает свой набор действий над данными. Выбор вида контейнера зависит от того, что требуется делать с данными в программе. Например, при необходимости часто вставлять и удалять элементы из середины последовательности следует использовать список, а если включение элементов выполняется главным образом в конец или начало – двустороннюю очередь.
Ассоциативные контейнеры обеспечивают быстрый доступ к данным по ключу. Эти контейнеры построены на основе сбалансированных деревьев. Существует пять типов ассоциативных контейнеров: словари (map), словари с дубликатами (multimap), множества (set), множества с дубликатами (multiset) и битовые множества (bitset).
Контейнерные классы обеспечивают стандартизированный интерфейс при их использовании. Смысл одноименных операций для различных контейнеров одинаков, основные операции применимы ко всем типам контейнеров.
Практически в любом контейнерном классе определены поля перечисленных ниже типов:
Поле
Пояснение
value_type
Тип элемента контейнера
size_type
Тип индексов, счётчиков элементов и т.д.
iterator
Итератор
reverse_iterator
Обратный итератор
reference
Ссылка на элемент
const_reference
Константная ссылка на элемент
key_type
Тип ключа (для ассоциативных контейнеров)
key_compare
Тип критерия сравнения (для ассоциативных контейнеров)
Итераторы также включены в библиотеку. Они представляют собой объекты, которые в большей или меньшей степени можно рассматривать как указатели. Они предоставляют возможность организовывать циклы с содержимым контейнера подобно тому, как используются указатели для организации циклов с массивами.
Во всех контейнерах определены методы, позволяющие получить сведения о размере контейнеров.
Метод
Пояснение
size()
Число элементов
max_size()
Максимальный размер контейнера
empty()
Функция, показывающая, пуст ли контейнер
Пример
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v;
cout<< "size = " << v.size() <<endl;
int i;
for(i=0; i<10; i++)
v.push_back(i);
cout<< "size now = " << v.size() << endl;
for(i=0; i<10; i++) cout << v[i] << " ";
cout << endl;
cout << "front = " << v.front() << endl;
cout << "back = " << v.back() <<endl;
vector<int>::iterator p=v.begin();
while(p!=v.end()) {
cout << *p << " ";
p++;
}
return 0;
}
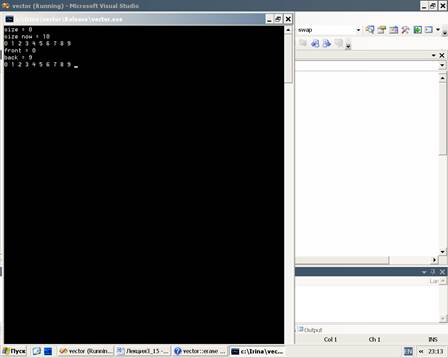
На экран программа выдаст следующие данные
В этой программе вектор первоначально создаётся с нулевой длиной. Функция-член push_back() добавляет значение к концу вектора, увеличивая его размер, если в этом есть необходимость. Функция size() возвращает размер вектора. Вектор может быть индексирован подобно обычному массиву. Доступ к нему может быть обеспечен также с помощью итератора.
Посмотрим, как используется класс list
#include <list>
#include <iostream>
#include <string>
using namespace std;
int main()
{
list<string> groceryList;
list<string>::iterator i = groceryList.begin();
i = groceryList.insert(i, "apple");
i = groceryList.insert(i, "bread");
i = groceryList.insert(i, "juce");
cout << "Number of list elements " << groceryList.size() << endl;
cout << "List's elements:" << endl;
i = groceryList.begin();
while(i !=groceryList.end())
{
cout << *i << endl;
i++;
}
system("pause");
return 0;
}
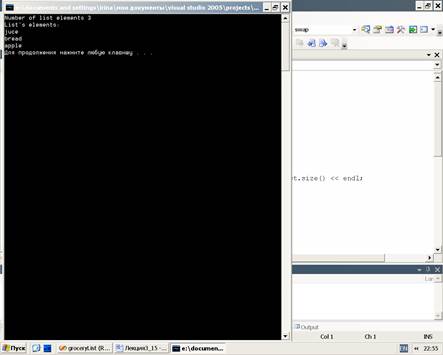
Здесь использована функция-член insert, её прототип:
iterator insert(iterator i, const T& val=T());
Функция вставляет элемент val в список непосредственно перед элементом, на который установлен итератор. Итератор должен быть проинициализирован, даже если список пуст. Функция возвращает итератор, установленный на вновь созданный элемент.
Программа выдаёт на консоль:
Использование класса map для кодирования
#include <iostream>
#include <map>
#include <string>
#include <strstream>
using namespace std;
int main()
{
map <int, string, greater<int>> a;
map <int, string, greater<int>>::iterator p;
a[1]="00";
a[2]="01";
a[3]="100";
a[4]="101";
a[5]="1100";
a[6]="1101";
a[7]="1110";
a[8]="1111";
int mas[]={0,5,6,4,2,7};
char str[100];
ostrstream message(str,100);
int i;
for(i=0;i<sizeof mas/sizeof(int);i++) {
if(!a[mas[i]].empty()) message<<a[mas[i]];
}
message<<ends;
cout << str << endl;
return 0;
}
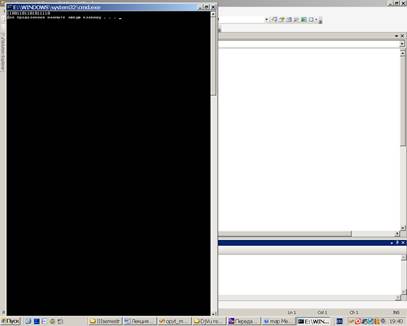
Программа выдаст на консоль
Обратите внимание, что ошибочное сообщение (0, для которого нет кода) не было кодировано, поскольку оператор [ ] в этом случае возвращает пустой объект string.
46. Основы обработки исключений
Обработка исключений
Обработка исключений позволяет упорядочить обработку ошибок времени исполнения. Используя обработку исключений С++, программа может автоматически вызывать код для обработки ошибок тогда, когда такая ошибка возникает.
Основы обработки исключений
Обработка исключений в С++ использует три ключевых слова: try, catch и throw. Те инструкции программы, где ожидается возможность появления исключительных ситуаций, содержится в блоке try. Если в блоке try возникает исключение, т.е. ошибка, то генерируется исключение. Исключение перехватывается, используя catch, и обрабатывается. Ниже это общее описание будет рассмотрено более подробно.
Инструкция, генерирующая исключение, должна исполняться внутри блока try. Вызванные из блока try функции также могут генерировать исключения. Всякое исключение должно быть перехвачено инструкцией catch, которая непосредственно следует за инструкцией try, сгенерировавшей исключение. Общая форма блоков try и catch показано ниже:
try {
// блок try
}
catch (тип1 аргумент) {
// блок catch
}
catch (тип2 аргумент) {
// блок catch
}
…
catch (типN аргумент) {
// блок catch
}
Размеры блока try могут изменяться в больших пределах. Например, блок try может содержать несколько инструкций какой-либо функции, либо же, включать в себя весь код функции main( ), так что вся программа будет охвачена обработкой исключений.
Когда исключение сгенерировано, оно перехватывается соответствующей инструкцией catch, обрабатывающей это исключение. Одному блоку try может отвечать несколько инструкций catch. Какая именно инструкция catch исполняется, зависит от типа исключения. Это означает, что если тип данных, указанных в инструкции catch, соответствует типу данных исключения, то только эта инструкция catch и будет исполнена. Когда исключение перехвачено, аргумент получает её значение. Перехваченным может быть любой тип данных, включая созданные программистом классы. Если никакого исключения не сгенерировано, то инструкции catch выполняться не будут.
Общая форма записи инструкции throw имеет вид:
throw исключение;
Инструкция throw должна выполняться либо внутри блока try, либо в функции, вызванной из блока try. В приведённом выше выражении исключение обозначает сгенерированное значение.
Если генерируется исключение, для которого отсутствует подходящая инструкция catch, может произойти аварийное завершение программы.
Пример
// обработка простого исключения
#include <iostream>
using namespace std;
int main()
{
cout << "Start\n";
try { // начало блока try
cout << "Inside try block\n";
throw 100; // генерация исключения
cout << "This will no execute";
}
catch (int i) { // перехват ошибки
cout << "Caught an exception -- value is: ";
cout << i << "\n";
}
cout << "End";
getchar();
return 0;
}
Программа выведет на экран:
Start
Inside try block
Caught an exeption –– value is: 100
End
Блок try содержит три инструкции. За ним следует инструкция catch(int i), обрабатывающая исключения целого типа. В блоке try будут выполняться только две инструкции: первая и вторая – throw. Как только исключение было сгенерировано, управление передаётся инструкции catch, а блок try прекращает своё исполнение. Таким образом, инструкция после инструкции throw никогда не выполняется.
Обычно код в инструкции catch пытается исправить ошибку путём выполнения подходящих действий. Если ошибку удалось исправить, то выполнение продолжается с инструкции, непосредственно следующей за catch. Однако иногда не удаётся справится с ошибкой, и блок catch завершает программу путём вызова функции exit() или abort().
Как отмечалось выше, тип исключения должен соответствовать указанному в инструкции типу.