Сочетание средств проверки полномочий и проверки подлинности - мощное орудие борьбы за безопасность информационных систем и баз данных. Если все пользователи, работающие в интерактивном режиме или запускающие пакетные приложения, достаточно надежны и имеют доступ к максимально закрытой информации, хранимой в системе, то упомянутый подход к обеспечению безопасности может быть вполне достаточным. Например, если в системе хранится информация, классифицированная по уровням от полностью открытой до совершенно секретной (чуть ниже мы рассмотрим понятие уровней защиты данных), но все пользователи системы имеют доступ к самым секретным данным, то в такой системе достаточно иметь надежные механизмы проверки полномочий и проверки подлинности. Такая модель называется "работой на высшем уровне (секретности)" (running at system high).
Однако она оказывается неудовлетворительной, если в учреждении необходимо организовать действительно многоуровневую среду защиты информации. Многоуровневая защита означает, что (1) в вычислительной системе хранится информация, относящаяся к разным классам секретности; (2) часть пользователей не имеют доступа к максимально секретному классу информации. Классический пример подобной среды - вычислительная система военного учреждения, где в логически единой базе данных (централизованной или распределенной) может содержаться информация от полностью открытой до совершенно секретной, при этом степень благонадежности пользователей также варьируется от допуска только к несекретной информации до допуска к совершенно секретным данным. Таким образом, пользователь, имеющий низший статус благонадежности, может выполнять свою работу в системе, содержащей сверхсекретную информацию, но ни при каких обстоятельствах не должен быть допущен к ней.
Многоуровневая защита баз данных строится обычно на основе модели Белл-ЛаПадула (Bell-LaPadula), которая предназначена для управления субъектами, т. е. активными процессами, запрашивающими доступ к информации, и объектами, т. е. файлами, представлениями, записями, полями или другими сущностями данной информационной модели.
Объекты подвергаются классификации, а субъекты причисляются к одному из уровней благонадежности (clearanсe). Классы и уровни благонадежности называются классами доступа или уровнями.
Класс доступа характеризуется двумя компонентами. Первый компонент определяет иерархическое положение класса. Второй компонент представляет собой множество элементов из неиерархического набора категорий, которые могут относиться к любому уровню иерархии. Так применяется следующая иерархия классов (сверху вниз):
· совершенно секретно;
· секретно;
· конфиденциально;
· несекретно.
Второй компонент может относиться, например, к набору категорий:
· ядерное оружие;
· недоступно для иностранных правительств;
· недоступно для служащих по контракту.
В частной компании возможны такие уровни иерархии:
· секретно;
· для ограниченного распространения;
· конфиденциально;
· для служебного пользования;
· несекретно.
Второй компонент в такой компании мог бы принадлежать к набору категорий:
· недоступно для служащих по контракту;
· финансовая информация компании;
· информация об окладах.
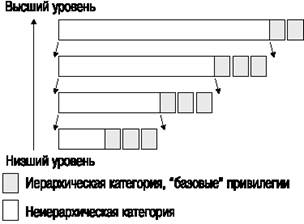
Очевидно, что можно определить матрицу соотношений между иерархическими и неиерархическими компонентами. Например, если некоторый объект классифицирован как совершенно секретный, но ему не приписана ни одна из категорий неиерархического набора, то он может предоставляться иностранным правительствам, в то время как менее секретный объект может иметь категорию "недоступно для иностранных правительств" и, следовательно, не должен им предоставляться. Однако в модели Белл-ЛаПадула создается "решетка", где неирархические компоненты каждого уровня иерархии автоматически приписываются и всем более высоким уровням (так называемое "обратное наследование"). Эта модель отображена на рис. 21-3.
Рис. 21-3Решетка классов доступа в модели Белл-ЛаПадула
До сих пор наше обсуждение касалось вполне очевидных понятий. Из него следует, что субъект класса CL1 имеет доступ к объектам класса CL2, если CL2 не выше CL1. Например, пользователь класса "совершенно секретно", имеет доступ к информации классов "совершенно секретно", "секретно", "конфиденциально", "несекретно". В модели Белл-ЛаПадула этот принцип известен под названием простого свойства секретности (simple security property).
Менее очевидно другое свойство, обозначаемое символом *, которое позволяет субъекту иметь право на запись в объект только в том случае, если класс субъекта такой же или ниже, чем класс записываемого объекта. Это означает, что информация, принадлежащая какому-либо уровню секретности, никогда не может быть записана в какой-либо объект, имеющий более низкий уровень секретности, поскольку это могло бы привести по неосторожности к деградации защиты классифицированной информации.
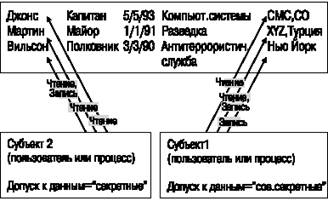
С учетом двух принятых в модели Белл-ЛаПадула ограничений (простое свойство секретности и *-свойство) можно представить себе базу данных с многоуровневой защитой так, как показано на рис. 21-4. Заметим, что субъект 1, пользователь или процесс, имеющий высший уровень благонадежности, может читать информацию всех кортежей, но в силу *-свойства он может записать данные только в кортеж наивысшей классификации (субъект может записывать информацию только "вверх по иерархии", но не "вниз по иерархии"). Субъект 2, принадлежащий к классу "секретно", не может прочитать "самую секретную" строку, но может прочитать две остальные. В то же время, субъекту 2 разрешена запись в строку класса "секретно" и в строку класса "совершенно секретно" (запись "вверх").
Рис. 21-4Пример применения правил доступа Белл-ЛаПадула
Как и в большинстве областей вычислительных средств и информационного управления и, в особенности, в области безопасности, приведенная выше простая модель в реальности представляет не слишком большую ценность, подобно упрощенным моделям проверки полномочий и подлинности, которые мы обсуждали в разд. 1.2. Хотя принципы Белл-ЛаПадула сами по себе вполне здравые, но требование поддержки нескольких уровней защиты в пределах одной таблицы (или в одной базе данных) сопряжено с рядом серьезных проблем. Рассмотрим, например, следующие ситуации.
Сотрудник военного ведомства, чьи персональные данные хранятся в базе данных с многоуровневой защитой, может иметь "настоящую" миссию, например быть сотрудником отдела по борьбе с терроризмом, и в то же время некоторое "прикрытие", согласно которому он является, допустим, членом отряда десантников. При этом в базе данных должна быть представлена и реальная информация, и прикрытие.
Сержант оказывается в действительности майором контрразведки; или разжалованный и с позором уволенный ветеран на самом деле является глубоко засекреченным государственным агентом, причем в чине полковника (такие истории все мы не раз видели в кино).
Настоящее имя суперсекретного правительственного эксперта по борьбе с терроризмом классифицировано как сверхсекретная информация; его официальный статус - почтовый служащий на пенсии.
Мы могли бы расширить представленную на рис. 21-4 модель, добавив свойство секретности не только для каждой строки, но и на уровне элементов, т. е. для каждого столбца (значение каждого столбца внутри каждой строки имеет свою классификацию). Но это расширение приведет к новым серьезным проблемам, поскольку каждый столбец в строке может принимать одно из нескольких возможных значений, в зависимости от обозреваемой классификации (рис. 21-5). Такое положение дел на фундаментальном уровне нарушает требование первой нормальной формы (множественные значения, рассматриваемые как нечто вроде повторяемых групп), т. е. один из важнейших принципов реляционных баз данных. Следовательно, необходимо каким-то образом решить эту проблему. В следующем разделе мы рассмотрим такое решение, а именно многозначные кортежи.
Рис. 21-5Поэлементная классификация и возникающие в связи с этим проблемы