Традиционной архитектурой многопользовательских систем, которая сложиилась до появления ПК, считалась схема, при которой один мощный компьютер с единственным процессором был соединен с несколькими пользовательскими терминалами, не имеющими для хранения и обработки данных собственных ресурсов. Системы распределенной обработки данных строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа к ней. СУБД и приложения также располагались на центральной ЭВМ. Пользовательские приложения обращались к необходимым службам СУБД. Таким же образом сообщения возвращались назад на пользовательский терминал. Естественно, что при такой архитектуре основная и чрезвычайно большая нагрузка возлагалась на центральный компьютер, который должен выполнять не только действия прикладных программ и СУБД, но и большую работу по обслуживанию терминалов.
Первой системой, работающей в многопользовательском режиме, была СУБД SYSTEM R, разработанная фирмой IBM. В ней были реализованы основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД.
С момента появления СУБД SYSTEM R прошел длительный период времени. В этот период происходили значительные колебания в вычислительных ресурсах и схемах их применения, используемых для хранения и обработки информации. Наблюдались и отдельные тенденции в этих колебаниях:
Downsizing – децентрализация;
UpSizing – централизация;
RightSizing – определение размера и схемы в соответствии с реальной ситуацией.
Первая тенденция была вызвана движением от отдельных Mainframe-систем к открытым распределенным системам, использующим сети персональных компьютеров, и привела к более эффективным с точки зрения эксплуатационных затрат системам. Этот подход отражает организационную структуру компании, логически состоящую из отдельных подразделений, которые распределены по разным офисам.
Встречный по отношению к рассмотренной тенденции процесс происходил практически параллельно с первым и был обусловлен бурным развитием персональных компьютеров, появлением локальных сетей. Высокие темпы роста производительности и функциональных возможностей ПК позволили разработчикам профессиональных СУБД выпустить в свет ряд систем, получивших широкое распространение.
Однако рано или поздно встречные процессы должны были погасить в некоторой степени амплитуду подобных колебаний. В результате этого господствующее положение должна была занять тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам.
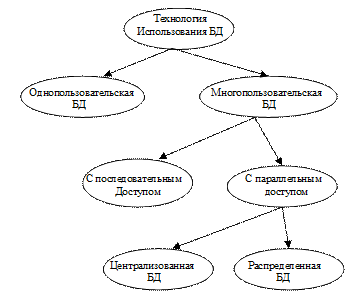
Различные варианты реализации режимов работы систем БД можно представить в виде схемы (рисунок 1).
Рисунок 1. Технологии использования БД
Различные режимы могут быть реализованы в пределах одной и той же организации и даже на одном и том же компьютере.
Из всех режимов, показанных на рисунке 1, наибольшие проблемы возникают при реализации баз данных с параллельным доступом. Рассмотрим технологии параллельного или распределенного доступа, применяемых в настоящее время для работы с централизованными БД. Наиболее часто упоминаются в соответствующей литературе в этом плане два типа технологий: технология файлового сервера и технология "клиент - сервер", которые являются двухуровневыми структурами. Поскольку, первую можно считать частным случаем второй, то все технологии такого рода относятся к технологиям "клиент - сервер", последующее развитие которых, стремление устранить их некоторые недостатки вызвали появление других моделей и структур совместной работы клиентов и сервера.
Модели двухуровневой технологии "клиент – сервер"
Общая цель систем баз данных – поддержка разработки и выполнения приложений баз данных. Систему баз данных можно рассматривать как систему, где осуществлено распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели называется "клиентом", а другой, обслуживающий клиента, – сервером(машина, хранящая базы данных). Клиентский процесс запрашивает некоторые услуги, а серверный процесс обеспечивает их выполнение. При этом предполагается, что один серверный процесс - может обслужить множество клиентских процессов.
Серверв простейшем случае – это собственно СУБД. Он поддерживает все основные функции СУБД, и предоставляет полную поддержку на внешнем, концептуальном и внутреннем уровнях.
Клиенты – это различные приложения, которые выполняются над СУБД.
Подобное разбиение явилось естественным продолжением полученного в наследство опыта построения многопользовательских систем. Однако следует отметить, что в это наследие пришлось внести существенные коррективы. Дело в том, что сейчас в подобные сети объединяют компьютеры с собственными немалыми ресурсами и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их возможности.
Обычно в приложении выделяются следующие группы функций:
- функции ввода и отображения данных;
- прикладные функции, определяющие основные алгоритмы решения задач приложения;
- функции обработки данных внутри приложения; П функции управления информационными ресурсами;
- служебные функции, играющие роль связок между функциями первых четырех групп.
Функции ввода и отображения данных – презентационная часть приложения – определяются тем, что пользователь видит на своем экране, когда работает приложение. Поэтому основными задачами этой части приложения являются:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатий клавиш клавиатуры.
Прикладные функции определяют основные алгоритмы решения конкретных задач приложения. Обычно код приложения пишется с использованием различных языков программирования, таких как Си, Cobol, SmallTalk, Pascal.
Функции обработки данныхсвязаны с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL. Обычно операторы языка SQL встраиваются в языки, которые используются для написания кода приложения.
Функции управления информационными ресурсами(процессор управления данными) – это собственно СУБД, которая обеспечивает хранение и управление базами данных.
Служебные функциивыполняют роль связок между функциями других групп.
В монолитном исполнении все перечисленные компоненты приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти части приложения распределяются по сети.
Если все пять компонентов приложения распределяются только между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере, то такая модель называется двухуровневой.Она имеет несколько основных разновидностей. Рассмотрим их.
Файловый сервер
Модель файлового сервера называется моделью удаленного управления данными.Данная модель предполагает следующее распределение функций: на клиенте располагаются почти все части приложения: презентационная часть приложения, прикладные функции, а также функции управления информационными ресурсами. Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД и поддерживает доступ к файлам.
СУБД посылает запросы файловому серверу по всем необходимым ей данным. Запрос клиента формулируется в командах языка манипулирования данными (ЯМД). СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента. Далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о передаче следующего блока информации и т. д. Передача информации с сервера производится до тех пор, пока не будет получен ответ на запрос клиента.
Поскольку передача файлов представляет собой длительную процедуру, такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом.
Помимо этого недостатка использование файлового сервера несет еще и другие:
- на каждой рабочей станции должна находиться полная копия СУБД;
- управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД;
- узкий спектр операций манипулирования данными, который определяется только файловыми командами;
- защита данных осуществляется только на уровне файловой системы.
Тем не менее, следует обратить внимание и на основное достоинство этой модели, заключающееся в том, что в ней уже осуществлено разделение монопольного приложения на два взаимодействующих процесса. При этом сервер может обслуживать множество клиентов, обращающихся к нему с запросами.
Модель удаленного доступа к данным
В модели удаленного доступа база данных также хранится на сервере. На сервере же находится и ядро СУБД. На клиенте располагаются части приложения, поддерживающие функции ввода и отображения данных и прикладные функции.
Клиент обращается к серверу с запросами на языке SQL. По отношению к файловому серверу данный подход имеет серьезные преимущества. С одной стороны, установка компонента представления и прикладного компонента на клиентский компьютер не позволяет перегрузить сервер БД, сводя к минимуму общее число процессов в операционной системе. С другой стороны, серверу БД выделяются только свойственные ему функции; он загружается операциями обработки данных, запросов и транзакций.
Сервер принимает и обрабатывает запросы со стороны клиентов, проверяет полномочия пользователей, гарантирует соблюдение ограничений целостности, выполняет обновление данных, выполняет запросы и возвращает результаты клиенту, поддерживает системный каталог, обеспечивает параллельный доступ к базе данных и её восстановление. К тому же резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не файловые команды, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, соответствующие запросу, а не блоки файлов, как в модели файлового сервера. Основное достоинство данной технологии в том, что стандартом при общении приложения-клиента и сервера становится язык SQL.
Тем не менее, данная технология обладает и рядом недостатков:
- запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть;
- презентационные и прикладные функции приложения должны быть повторены для каждого клиентского приложения;
- сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте.
Модель сервера баз данных
Технологию "клиент – сервер" поддерживают большинство современных СУБД. Только та технология, которую они поддерживают, является дальнейшим развитием только что рассмотренной модели удаленного доступа к данным. В основу данной модели добавлен механизм хранимых процедур и механизм триггеров.
Механизм хранимых процедурпозволяет создавать подпрограммы, работающие на сервере и управляемые его процессами. Подобные подпрограммы могут быть активизированы вызывающим их приложением. Кроме того, они могут быть вызваны правилами, поддерживающими целостность данных, или триггерами. Хранимые процедуры тесно взаимодействуют с оптимизатором сервера, что позволяет получить высокую производительность при обработке данных.
Таким образом, размещение на сервере хранимых процедур означает, что прикладные функции приложения разделены между клиентом и сервером. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, которые требуются клиенту либо для вывода на экран, либо для выполнения той части прикладных функций, которые расположены на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль целостности базы данных в модели сервера баз данных выполняется с использованием механизма триггеров. Триггер – это особый тип хранимой процедуры, реагирующей на возникновение определенного события в БД. Он активизируется при попытке изменения данных – при операциях добавления, обновления и удаления. Триггеры определяется для конкретных таблиц БД. Они дают возможность поддерживать целостность БД, не пролагаясь на программное обеспечение приложений. Ядро СУБД проводит контроль всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер.
Триггер – фильтр, применяемый после выполнения операции. Если триггер вызывает ошибку в запросе, обновление информации не производится, а в приложение, выполняющее это действие, возвращает сообщение об ошибке. Триггер рассматривается как единое целое - как одна транзакция, которая либо фиксируется, либо откатывается.
В модели сервера БД сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. Поскольку функции клиента облегчены переносом части прикладных функций на сервер, он в этом случае называется «тонким».
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для описания хранимых процедур и триггеров используется расширение стандартного языка SQL – встроенный SQL.
При всех положительных качествах данной модели у нее все же есть один недостаток – очень большая загрузка сервера.
Для разгрузки сервера была предложена трехуровневая модель - сервер приложений.