Национальный исследовательский ядерный университет «МИФИ»
Кафедра Компьютерных систем, сетей и технологий
Лабораторная работа №1
Динамическая структура данных типа «Стек»
Выполнил: студент
Группы ВТ2-С10
Сергеев А.Н.
Проверил:
Тельнов В.П.
Обнинск, 2012
Постановка задачи. Разработайте в MS Visual Studio программное решение на языке Си, которое реализует динамическую структуру данных (контейнер) типа «Стек». Каждый элемент контейнера содержит строки символов произвольной длины.
В программном решении следует реализовать следующие операции над контейнером:
· создание и уничтожение контейнера;
· добавление и извлечение элементов контейнера;
· обход всех элементов контейнера (итератор);
· удаление из контейнера дублирующих элементов;
· вычисление количества элементов в контейнере;
· реверс контейнера (первый элемент контейнера становится последним, второй
элемент становится предпоследним и т.д.);
· объединение, пересечение и вычитание контейнеров;
· сохранение контейнера в дисковом файле и восстановление контейнера из файла.
Рисунок, изображающий структуру данных:
Стек — структура данных, в которой доступ к элементам организован по принципу LIFO (last in — first out, «последним пришёл — первым вышел»). Добавление элемента, называемое также проталкиванием (push), возможно только в вершину стека (добавленный элемент становится первым сверху). Удаление элемента, называемое также выталкиванием (pop), тоже возможно только из вершины стека, при этом второй сверху элемент становится верхним.
Стеки широко применяются в вычислительной технике. Например, для отслеживания точек возврата из подпрограмм используется стек вызовов, который является неотъемлемой частью архитектуры большинства современных процессоров. Языки программирования высокого уровня также используют стек вызовов для передачи параметров при вызове процедур.
Достоинства стека:
· размер структуры ограничивается только размером памяти машины;
· при изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей.
Однако существуют и недостатки:
· работа с указателями требует, как правило, более высокой квалификации от программиста;
· на поля связок расходуется дополнительная память;
· доступ к элементам может быть менее эффективным по времени.
· нельзя напрямую обратиться к элементу, не лежащему на вершине стека
В данной лабораторной работе над структурой данных типа «Стек» можно выполнить следующие операции:
1. Начальное формирование стека.
2. Добавление элемента в стек.
3. Выборка из стека.
4. Итератор (проход всех элементов стека)
5. Удаление из стека дублирующих элементов.
6. Реверс стека.
7. Объединение стеков.
8. Пересечение стеков.
9. Вычитание стеков.
10. Сохранение стека в дисковый файл.
11. Считывание стека из дискового файла.
12. Удаление стека.
13. Подсчёт количества элементов в стеке.
Сам элемент динамической структуры представляет собой структуру с тремя полями: данные, указатель на следующий элемент, номер элемента (последнее поле необязательно, но в данном случае оно необходимо для реализации итератора (см. далее)):
Выделяется память под новый элемент стека, после чего полю Data присваивается введённая строка data, а полю Next – значение нуль, т.к. элемент стека на данный момент первый и перед ним ничего нет. Указатель на вершину top меняется на указатель на данный элемент, т.е. первый элемент на данный момент является вершиной стека; нумеруем элемент как нулевой.
Выделяется память под новый элемент, в него записывается введённая строка, указателю на следующий элемент присваивается значение указателя на вершину, данный элемент теперь является вершиной стека; элемент нумеруется.
3. Выборка из стека: char* Pop(struct Node** top);
Выделяем дополнительную память, в которую запишем данные, которые хранит элемент, лежащий на вершине; выделяем ещё одну доп. память, которой присваиваем элемент, лежащий на вершине. Адрес вершины меняем на адрес следующего элемента и освобождаем память, которую занимает данный элемент.
4. Итератор: char* Iter(struct Node** top, int num);
Выделяем дополнительную память, которая будет являться копией нашего стека. После чего поочерёдно вынимаем элементы до тех пор, пока значение num не совпадёт с номером искомого элемента.
5. Удаление из стека дублирующих элементов: void DelSimilar(struct Node** top);
Выделяем память под дополнительный стек, в котором будет храниться первоначальный стек, но уже без дублирующих элементов. Первым элементом дополнительного стека будет элемент, лежащий на вершине первоначального стека. После чего начинаем вынимать элементы из первоначального стека и сравнивать их с элементами, лежащими в дополнительном стеке. Если среди них попадаются равные, то эти элементы в стек не добавляются. Если же похожих элементов нет, то на последней итерации этот элемент будет добавлен в дополнительный стек. В конце реверсируем стек (см. далее), чтобы он выглядел как первоначальный.
6. Реверс стека: void Rev(struct Node** top);
Выделяем дополнительный стек, который и будет реверсивным. Первым элементом реверсивного стека будет верхний элемент первоначального стека. Далее просто вынимаем поочерёдно элементы из исходного стека и помещаем их также поочерёдно в дополнительный стек.
7. Объединение стеков: void Union(struct Node** top1, struct Node** top2);
Выделяем память под дополнительный стек, в котором будет храниться результат. В данной функции участвуют два исходных стека top1 и top2. Первым элементом дополнительного стека будет элемент, лежащий на вершине первого исходного стека. Далее просто начинаем заполнять дополнительный стек элементами из обоих исходных стеков. После чего удаляем дублирующие элементы функцией удаления дублирующих элементов (см.выше).
Выделяем память под дополнительный стек, в котором будет храниться результат. В данной функции участвуют два исходных стека top1 и top2. Вводим флаг для проверки первого элемента результата, который изначально равен нулю. Подсчитываем количество элементов во втором стеке. Далее, вынимаем поочерёдно каждый из элементов первого стека и сравниваем их с элементами второго стека. Если попадается равный, и флаг при этом всё ещё равен нулю, то записываем элемент в результат как первый элемент и меняем значение флага. Если флаг не равен нулю, то помещаем элемент в результат функцией Push. После прохода всех элементов удаляются дублирующие элементы. Если же по проходу все элементов обоих стеков равных не обнаружилось, выдаётся соответствующее сообщение.
Выделяем память под дополнительный стек, в котором будет храниться результат. В данной функции участвуют два исходных стека top1 и top2. Вводим флаг для проверки первого элемента результата, который изначально равен нулю. Подсчитываем количество элементов во втором стеке. Далее начинаем поочерёдно вынимать каждый из элементов первого стека и сравнивать их с элементами второго стека. Если попадаются равные, то эти элементы в результат не записываем. Если похожих элементов нет, и флаг при этом остаётся равным нулю, то на последней итерации добавляем этот элемент в результат в качестве первого элемента, меняя при этом флаг. Если же флаг не был равным нулю, то добавляем этот элемент в результат функцией Push. Если все элементы были одинаковыми, то результат вычитания должен быть равным нулю, в этом случае выводится соответствующее сообщение.
Открываем файл. Выделяем память под строку, в которую будем записывать каждый элемент стека. Если при считывании первой строки не был достигнут конец файла, то эту строку записываем как первый элемент стека. После чего выписываем остальные элементы, пока не будет достигнут конец файла, не забывая при это выделять память под дополнительную строку.
Здесь всё просто – вынимаем элементы из стека функцией Pop, память освобождается автоматически при вызове этой функции.
13. Подсчёт количества элементов в стеке: int Num(Node** top);
Вводим счётчик элементов. Выделяем дополнительную память, которая будет являться копией исходного стека. Пока указатель на вершину не будет равен нулю, инкрементируем счётчик.
Руководство пользователя:
Прежде, чем приступить к запуску программы, нужно обратить внимание на несколько важных нюансов:
1. Для работы с файлами требуется создать два файла на диске C с расширением .txt, которые будут называться input и output. То есть, адреса этих файлов должны выглядеть так: C:\\input.txt и C:\\output.txt. В output вы, при вызове функции void Write(FILE *fout, struct Node** top), будете записывать стек, который вы предварительно должны создать и заполнить уже по ходу работы программы. Из input вы будете, используя функцию void Read(FILE *fin, struct Node** top) считывать стек, каждый элемент которого должен быть записан в отдельной строке файла, т.е. сначала в этот файл нужно записать данные, например:
(1-я строка) abc
(2-я строка) bcd
и так далее.
2. Программа выделяет память только под два стека. То есть вы не можете работать с тремя и более стеками, так как выделение память под стеки происходит независимо от вас.
После того, как вы убедитесь в том, что эти нюансы учтены, можете запускать программу. После запуска на экране появляется меню программы и предложение выбрать режим работы (Choose the mode of work: ). Обратите внимание на меню – здесь вы видите пронумерованные операции, которые можно проделать со стеком (Operations what you can do with stack:):
Operations what you can do with stack:
1. Create the stack by pushing the first element.
2. Push the element to the stack.
3. Pop the element from the top of stack.
4. Show the element of stack with number... (write the number of element).
5. Delete from the stack duplicate elements.
6. Reverse the stack.
7. Unite two stacks.
8. Intersect two stacks.
9. Substract from the stack A a stack B.
10. Save the stack into file.
11. Read the stack from file.
12. Delete the stack.
13. Calculate the number of elements.
14. Quit the program.
Соответственно:
1. Создать стек посредством добавления первого элемента.
2. Добавить элемент в стек.
3. Достать элемент из стека.
4. Показать элемент стека под номером… (напишите номер элемента)
5. Удалить из стека дублирующие элементы.
6. Реверсировать стек.
7. Объединить два стека.
8. Пересечь два стека.
9. Вычесть из стека А стек В.
10. Сохранить стек в файл.
11. Считать стек из файла.
12. Удалить стек.
13. Подсчитать количество элементов.
14. Выйти из программы.
После того, как вы выберите нужную вам операцию, введите её номер в командной строке и нажмите Enter. Теперь вам будет предложено выбрать стек, с которым вы хотите продолжить работу (первый или второй). Заметим, что этого не произойдёт, если вы выберите операцию под номером 14, так как эта операция завершит работу программы. После того, как вы выберите стек, введите в командную строку его номер (1 или 2) и нажмите Enter. Кроме цифр 1 или 2 больше ничего вводить нельзя! Если ваш стек ещё не заполнен, но вы хотите начать его заполнять, то обязательно воспользуйтесь командой под номером 1. Если вы начнёте заполнять стек командой 2 без использования команды 1, то в дальнейшем обработка такого стека приведёт к ошибке программы. После выбора стека на экране высветится сообщение, соответствующее действию команды (например, команда 1 выдаст следующее сообщение: «Write the value of first element: », что означает «Напишите значение первого элемента: »). Теперь вам остаётся только записать в командную строку значение (например, abc) и нажать Enter. Программа возвратит вас в меню. Далее вы можете продолжать операции со стеками по вышеупомянутой схеме. Если вы хотите выйти из программы, то во вновь появившемся меню введите 14.
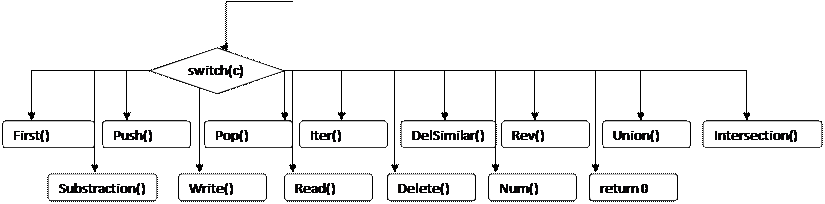
Структурная схема программы:
Листинг авторского кода на языке Си:
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
//элемент стека
struct Node
{
char* Data; //данные
struct Node* Next; //указатель на след. эл-т
int sp; //номер элемента стека (для удобства)
};
//меню программы
void menu(void)
{
printf(
"\n"
"*****************************************\n"
"Operations what you can do with stack:\n"
"1. Create the stack by pushing the first element.\n"
"2. Push the element to the stack.\n"
"3. Pop the element from the top of stack.\n"
"4. Show the element of stack with number... (write the number of element).\n"
"5. Delete from the stack duplicate elements.\n"
"6. Reverse the stack.\n"
"7. Unite two stacks.\n"
"8. Intersect two stacks.\n"
"9. Substract from the stack A a stack B.\n"
"10. Save the stack into file.\n"
"11. Read the stack from file.\n"
"12. Delete the stack.\n"
"13. Calculate the number of elements.\n"
"14. Quit the program.\n\n"
);
}
//инициализация стека
void Init(struct Node** top)
{
*top = (struct Node*)malloc(sizeof(struct Node));
(*top)->sp = NULL;
(*top)->Data = NULL;
(*top)->Next = NULL;
}
//начальное формирование стека
struct Node* First(struct Node** top, char* data)
{
struct Node* t = (struct Node*)malloc(sizeof(struct Node));
t->Data = data;
t->Next = 0; //т.к. эл-т первый, то перед ним ничего нет
*top = t;
(*top)->sp = 0; //даём элементу номер 0
return t;
}
//функция помещения элемента в стек
void Push(struct Node** top, char* data)
{
struct Node* t = (struct Node*)malloc(sizeof(struct Node)); //выделяем память под новый эл-т
t->Data = data; //записываем в поле Data введённую строку
t->Next = *top; //указываем на след. эл-т
*top = t; //меняем указатель вершины на данный эл-т, который теперь сам становится вершиной
(*top)->sp = (((*top)->Next)->sp) + 1; //нумеруем элемент