Общие сведения о системах управления базами данных
Функциональные возможности СУБД.
Основные этапы решения задач средствами СУБД Access 2003.
База данных – это совокупность хранимых в информационной системе данных различного характера, организованных по определенным правилам, регламентирующим процессы создания, ведения и доступа к данным.
Совокупность лингвистических и программных средств, предназначенных для создания, ведения и совместного использования баз данных многими пользователями, называется системой управления базами данных.
Под системой управления понимается комплекс программ, который позволяет не только хранить большие массивы данных в определенном формате, но и обрабатывать их, представляя в удобном для пользователей виде. Access — это система управления базами данных (СУБД).
Различают четыре типа моделей СУБД: иерархическую, сетевую, реляционную и объектно-ориентированную. Наиболее распространенной для ПЭВМ является модель СУБД реляционного типа.
Общие сведения о системах управления базами
Данных
Классификация моделей данных
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы.
Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание.
Поэтому центральным понятием в области баз данныхявляется понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее можно выделить нечто общее в этих определениях.
Модель данных— это некоторая абстракция, которая, будучи применима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
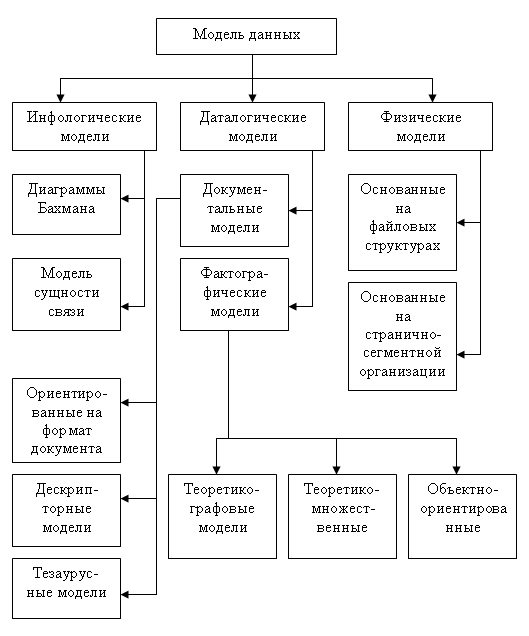
На рис. 4 представлена классификация моделей данных.
Рисунок 4 Классификация моделей баз данных
Модель выражающая информацию о предметной области в виде, независимом от используемой СУБД называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а дата-логические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы кэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
В зависимости от вида организации данных в группе теоретико-графовых моделях данных различают следующие основные модели СУБД:
- иерархическую;
- сетевую;
- реляционную;
- объектно-ориентированную.
Иерархические модели СУБД имеют древовиднуюструктуру. При этом каждому узлу структуры соответствует одинсегмент, представляющий собой поименованный линейный кортежполей данных. Каждому сегменту соответствует один входной и несколько выходных сегментов (рис. 5)..
Рисунок 5- Иерархическая структура СУБД
Каждыйсегмент структуры лежит на единственном иерархическом пути, начинающемся откорневого сегмента
Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента — это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающий сотрудника организации, мы должны выделить те характеристики сотрудника, которые могут его однозначно идентифицировать в рамках БД предприятия. Если предположить, что на предприятии могут работать однофамильцы, то, вероятно, наиболее надежным будет идентифицировать сотрудника по его табельному номеру. Однако если мы будем строить БД, содержащую описание множества граждан, например нашей страны, то, скорее всего, нам придется в качестве ключа выбрать совокупность полей, отражающих его паспортные данные.
Для описания такой логической организации данных достаточно предусматривать для каждого сегмента данных только идентификацию входногодля него сегмента. Так как в иерархической модели каждому входномусегменту данных соответствует N выходных, то такие модели весьма удобны для представления отношений типа 1:N впредметной области.
Сетевая даталогическая модель СУБД во многом подобна иерархической (рис. 6):
Рисунок 6 – Структура сетевой СУБД
Отличие заключается в том, что если в иерархической модели (рис. 1) для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевоймодели для сегментов допускаетсянесколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры. На рис. 2 представлен простой пример сетевой структуры, полученной на основе модификации иерархической структуры (рис. 1). Графическое изображение структуры связей сегментов в такого типа моделях представляет собойсеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД.
Таким образом, подсетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня.
Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям. В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическимсетевые СУБД предполагают разработку БД-приложенийопытными программистами и системными аналитиками.
СУБД реляционного типа являются наиболее распространенными на всех классах ЭВМ, а на ПК занимают доминирующее положение.
Основной структурой данных в модели является отношение, именно поэтому модель получила название реляционной (от английского relation — отношение).
Реляционной называется СУБД, в которой средства управления БД поддерживают реляционную модель данных. Концепция реляционной модели была предложена в 1970 г. Эдгаром Коддом и имеет большое значение в деле организации работы с БД.
Данная модель позволяет определять:
• операции по запоминанию и поиску данных;
• ограничения, связанные с обеспечением целостности данных.
Модель основана на математическом понятииотношения, расширенном за счет значительного добавления специальной терминологии и развития соответствующей теории. В такой модели общая структура данных (отношение) может быть представлена в виде таблицы, в которой каждая строка значений (кортеж) соответствует логической записи, а заголовки столбцов являются названиями полей(элементов) записи.
Операции запоминания и поиска делятся на две группы:
- операции на множествах (объединение, пересечение, разность, произведение);
- реляционные операции (выбрать, спроецировать, соединить, разделить).
Любойязык манипулирования данными, обеспечивающий все эти операции, являетсяреляционно полным. Для увеличения эффективности работы во многих СУБДреляционного типа приняты ограничения, соответствующие строгой реляционной модели.
Основным преимуществом реляционных СУБД является возможность связывания на основе определенных соотношений файлов БД. Со структурной точки зрения реляционные модели являются более простыми и однородными, чем иерархические и сетевые. В реляционной модели каждому объекту предметной области соответствует одно или более отношений. При необходимости определить связь между объектами явно, она выражается в виде отношения, в котором в качестве атрибутов присутствуют идентификаторы взаимосвязанных объектов.
СУБДсчитаетсяреляционной при выполнении следующих двух условий:
• поддерживает реляционную структуру данных;
• реализует, по крайней мере, операции селекции, проекции и соединения отношений.
Сутьреляционной СУБД можно пояснить на следующем простом примере (рис. 3).
В некоторой реляционной БД (РБД) имеются два файла – авторови публикаций, каждый из которых содержит определенное число записей, состоящих из фиксированного числа полей(соответственно 4 и 5), представляющих данные по соответствующим элементам предметной области. Можно сказать, что определены два отношения(таблицы), имеющие общий элемент -значения поля Автор. Операцииреляционной алгебры могут объединять два типа записей по этому общему элементу. Например, в результате соединения записьИванов может быть представлена в следующем виде:
Файл авторов публикаций БД
Автор
Адрес
Телефон
Число
публ.
...
...
...
...
Иванов
Оренбург
52-45-67
Сидоров
Москва
234-56-43
Петров
С.Петербург
456-78-90
Файл публикаций РБД
Назв.
публикации
Автор
Тип
публ.
Дата
Объем
в п.л.
Основы ..
Иванов
Статья
23.09.97
2,5
Проблема
Петров
Книга
30.05.86
Теория ..
Сидоров
Статья
12.04.93
5,7
• ••
• ••
• ••
•• •
• ••
Рисунок 3 – Иллюстрация принципа реляционной модели
т.е. к сведениям об авторе добавляются сведения о всех его публикациях, имеющихся в РБД.
Связь между записями допускается по нескольким полям, позволяя образовывать достаточно сложные операции. Поля данных, связывающие вместе две записи, могут быть уникальными для данной пары, но могут дублироваться и во многих других записях. Они могут повторяться неоднократно, связывая между собой записи. Аналогичным образом можно проиллюстрировать выполнение в реляционной модели операций проекциии селекции.
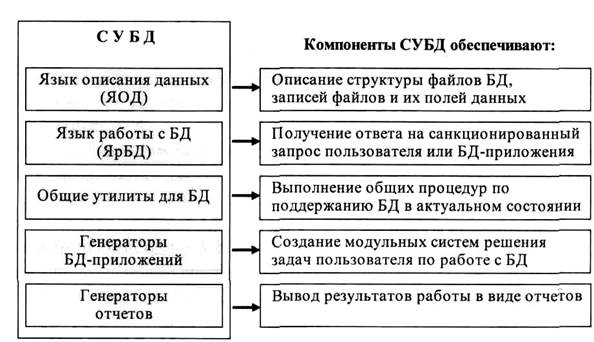
Большинство современных СУБД включают следующие пять основных компонентов (рис. 4):
Рисунок 4 – Основные компоненты СУБД
Остановимся несколько детальнее на каждой из этих компонент. В общем случаелингвистическое обеспечение СУБД включает ряд языков, обеспечивающих интерфейс с банком данных пользователям различного уровня. Из данныхязыковых средств можно выделить две основные группы: языки описания данных (ЯОД) и языки работы с БД (ЯрБД). Группа ЯОД предназначена для описания структур данных и отношений между ними, поддерживаемых СУБД. Каждая конкретная СУБД располагает своим ЯОД, но все ЯОД поддерживают один и тот же набор основных функций.
Среди лингвистических средств СУБД центральное место занимают ЯрБД, спектр которых весьма широк по их уровню синтаксическо-семантической организации, реализации и назначению (рис. 4). Языки данной группы позволяют не только организовывать запросы из БД нужной информации, но и программировать нужные БД-приложения.
Наборобщих утилит (рис. 4) предназначен для обеспечения наиболее часто используемых процедур работы с данными и файлами БД (редактирование данных, удаление записей, создание новых файлов и т.д.). В этом отношении средства данной группы обеспечивают общие функции поддержания БД в актуальном состоянии, подобно тому, как это делают утилиты MS-DOS для обеспечения работы с ее файловой структурой.
Генератор приложений представляет собой компоненту СУБД, обеспечивающую пользователя средствами создания простейших БД-приложений без их программирования. На основе описания задачигенератор из программных модулей, находящихся в специальных библиотеках, компилирует (собирает и редактирует) программную систему, обеспечивающую решение поставленной задачи.
Наконец,генераторы отчетов позволяют выводить результаты работы с БД в виде отчетов, оформленных по требованию пользователя, используя достаточно простой язык (командный, табличный и др.).
При реализации запросов на получение информации из БД задействованными оказываются практически все основные компоненты СУБД.
Одной из важных особенностей СУБД является их многофункциональность, диапазон которой определяется степенью еефункциональной полноты.Функционально полная СУБД должна включать в свой состав средства, обеспечивающие нужды пользователей различных категорий и уровней на всех этапахжизненногоцикла БД (проектирование, разработка и эксплуатация), который для данного типа систем может составлять несколько десятков лет. Функционально полную СУБД можно определять следующим составом ее функциональных характеристик:
• поддерживаемая системой даталогическая модель;
• средства администратора БД;
• средства разработки БД-приложений;
• интерфейсы с пользователями и другими БД-приложениями;
• интерфейсы с другими СУБД;
• средства обеспечения сетевой и распределенной обработки информации.