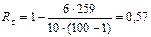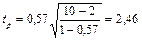Для оценки степени сопряженности между двумя признаками объектов можно использовать ранговый коэффициент корреляции Спирмена, который определяют по формуле
, где R1 и R2– ранги двух признаков у i-го объекта; N – число изучаемых объектов.
Достоверность этого показателя определяют по формуле:
Таблица Б
Критические разности в критерии Уилкоксона при сравнении пар градаций (групп генотипов, условий испытания и т. п.) для k = 3, 4, … 10 и n = 3, 4, … 18, 20, 22, 24. Наблюдаемая разность сумм значима при заданном уровне α = 0,05 (светлый шрифт) или α = 0,01 (жирный шрифт), если они равняется табличному значению или превышает его (Рунион, 1982).
k (число градаций)
n
.521
496
,
где tp – расчётный критерий Стьюдента, который необходимо сравнить с табличным.
Число степеней свободы определяют по формуле df = N – 2.
Если tp> tт, то сопряженность двух признаков достоверна.
Пример. Необходимо проверить наличие сопряженной изменчивости двух признаков: урожайности (количественный признак) и устойчивости к мучнистой росе (в баллах поражения) у 10 сортов персика.
Для сопоставимости двух признаков переводим оба признака в ранговые.
Этот метод позволяет выделить максимально тесные связи между объектами матрицы. Он работает с матрицами таксономических отношений, коэффициентов корреляции т.п., и представляет собой так называемую неиерархическую кластер-процедуру. В результате строится дендрит максимальных связей, который затем «разрезается» на кластеры или плеяды.
Рассмотрим пример. Дана матрица парных коэффициентов ранговой корреляции между 7 признаками у абрикоса (1-окраска побега, 2-размер листьев, 3-толщина побега, 4-длина черешка, 5-окраска кожицы плода, 6-окраска мякоти плода, 7-окраска косточки). Необходимо построить так называемый максимальный корреляционный путь между признаками.
0,32
-0,41
0,19
0,74
0,02
0,13
0,32
0,91
0,18
0,11
0,28
0,01
-0,41
0,91
0,83
0,21
0,12
0,30
0,19
0,18
0,83
0,01
0,03
0,40
0,74
0,11
0,21
0,01
0,78
0,50
0,02
0,28
0,12
0,03
0,78
0,80
0,13
0,01
0,30
0,40
0,50
0,80
Сначала в данной матрице необходимо найти максимальное по модулю значение коэффициентов корреляции (0,91). Далее строят вспомогательную таблицу.
Первой во вспомогательной таблице выписывается строка, содержащая максимальное по модулю значение коэффициента корреляции (то есть, строка 2). Столбец, совпадающий с номером первой анализируемой строки в дальнейшем игнорируется (то есть, столбец 2). Каждый коэффициент маркируется двумя индексами: номер строки (внизу) и номер столбца (вверху), например 20,913. Столбец, содержащий максимальный по модулю коэффициент в дальнейшем также игнорируется (то есть, столбец 3).
Номер следующей строки определяется номером столбца, содержащего максимальное по модулю значение коэффициента в предшествующей строке (то есть 3). При анализе очередной строки необходимо сравнить этот коэффициент корреляции с коэффициентом в предыдущей строке этого же столбца и выбрать больший по модулю.
Анализируем строку 3. Значение коэффициента в строке 3 для 1 столбца равно 3-0,411, что больше по модулю, чем коэффициент в предыдущей строке 1-го столбца (20,321). Следовательно, выписываем значение 3-0,411. Второй и третий столбцы игнорируются. Для 4 столбца строки 3 значение коэффициента корреляции равно 30,834, а в предыдущей 20,184, следовательно, выбираем 30,834. Для 5 столбца значение коэффициента корреляции равно 30,215, а в предыдущей 20,115, следовательно, выписываем 30,215. Для 6 столбца 3-ей строки значение коэффициента равно 30,126, что меньше, чем во 2-ой строке 6-го столбца (20,286). Значит, оставляем предыдущее значение 20,286. Для 7 столбца 3-ей строки значение коэффициента корреляции равно 30,307, что больше предыдущего 20,017, следовательно, выписываем 30,307. Переходим к сравнению коэффициентов 3-ей строки. Максимальным оказывается коэффициент 30,834, находящийся в 4 столбце, следовательно, следующей будет 4-ая строка (4 столбец в дальнейшем игнорируется).
Анализируем строку 4. В столбце 1 коэффициент равен 40,191, что меньше по модулю предыдущего 3-0,411, поэтому оставляем значение предыдущего коэффициента 3-0,411. Второй, третий и уже четвертый столбцы игнорируем. В столбце 5 коэффициент равен 40,015, что меньше предыдущего 30,215, поэтому оставляем 30,215. В столбце 6, коэффициент равен 40,036, что меньше предыдущего 20,286, поэтому оставляем 30,126. В столбце 7 имеется коэффициент 40,407, который больше 30,307, поэтому выписываем 40,407. В модифицированной строке 4 максимальным по модулю оказывается коэффициент 3-0,411, следовательно, следующей анализируемой срокой будет строка 1 (столбец 1 в последующем игнорируется).
Анализируем строку 1. Столбцы 1-4 игнорируем. В столбце 5 находится коэффициент 10,745, который больше предыдущего 30,215, следовательно, выписываем 10,745. В 6 и 7 столбцах коэффициенты равны соответственно 10,026 и 10,137. Они меньше предыдущих 20,286 и 40,407, поэтому эти два последних коэффициента остаются. Максимальным в строке 1 является коэффициент 10,745, поэтому следующей будет 5-ая строка (столбец 5 далее игнорируется).
Анализируем строку 5. Столбцы 1-5 игнорируем. В столбце 6 имеется коэффициент 50,786, который больше предыдущего 20,286, следовательно, он выписывается. Столбец 7 также содержит коэффициент 50,507 больший предыдущего 40,407. Следующей анализируется строка 6 (так как коэффициент 50,786 оказался максимальным), столбец 6 в дальнейшем игнорируется.
Анализируем строку 6. Столбцы 1-6 игнорируем. В столбце 7 имеется коэффициент 60,807, больший 50,507, поэтому он выписывается. На этом анализ исходной таблицы завершен.
20,321
20,913
20,184
20,115
20,286
20,017
3-0,411
30,834
30,215
20,286
30,307
3-0,411
30,215
20,286
40,407
10,745
20,286
40,407
50,786
50,507
60,807
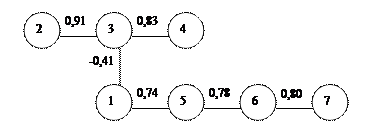
На основании полученных данных из последней таблицы можно построить так называемый дендрит или граф максимального корреляционного пути. Напомним, что подстрочные и надстрочные индексы максимальных коэффициентов каждой строки (выделены жирным шрифтом) являются номерами об4ъектов матрицы. Графическое изображение показано ниже:
После этого можно выделить плеяды сходных объектов. Разрезание максимального корреляционного пути для выделения плеяд проходит по наиболее слабому звену дендрита (связь между 3 и 1 признаками равная -0,41).
В результате выделены две тесно коррелирующих между собой плеяды признаков: плеяда 1 содержит три признака - 2,3,4; плеяда 2 содержит 4 признака - 1,5,6,7.
На следующем шаге рекомендуется определить средний коэффициент корреляции внутри каждой плеяды и сравнить его со средним коэффициентом корреляции между плеядами. Если внутрикластерный коэффициент корреляции достоверно превышает межкластерный, то кластеризация проведена правильно. Если наоборот, то выбранный уровень разрезания максимальных связей дендрита был занижен и его следует увеличить (например, до 0,74).
Вопросы:
1. Каковы особенности многолетних культур как объектов исследования?
2. Какие типы шкал используются для описания признаков и в чем их особенности?
3. Чем отличаются одномерные математические модели от многомерных?
4. Что называется рангом?
5. В каких случаях используют параметрические методы статистики, и в каких непараметрические?
6. Какие существуют типы статистических ошибок и как они связаны с понятием мощности критерия?
7. Какие имеются способы унификации признаков?
8. Какие непараметрические критерии используют при работе с номинальной и ранговой шкалами?
Литература
Основная
1. Вентцель Е.С. Исследование операций: задачи, принципы, методология. М., Наука, 1988. 208 с.
2. Гильдерман Ю.И. Закон и случай. Новосибирск, Наука, 1991. 199 с.
3. Горстко А.Б. Познакомьтесь с математическим моделированием. М., Знание, 1991, 150 с.
4. Смит Дж. Математические модели в биологии. М., Мир, 1970, 175 с.
5. Смит Дж. Модели в экологии. М., Мир, 1976, 184 с.
6. Тюрин Ю.Н.,Макаров А.А. Статистический анализ данных на компьютере. М.:Инфра, 1997, 528 с.
7. Хеттманспергер Т. Статистические выводы, основанные на рангах.-М.: Финансы и статистика. 1987, 334 с.
8. Якушев В.П., Буре В.М. Статистический анализ опытных данных. Непараметрические критерии. Санкт-Петербург: АФИ, 2001, 61 с.
Дополнительная
1. Гильдерман Ю.И. Лекции по высшей математике для биологов. Новосибирск, Наука, 1974, 410 с.
2. Дегтярев Ю.П., Кузнецов Н.Г., Корниенко В.С., Коломок О.И. Математическое моделирование и оптимизация. Волгоград, Изд. ВГСХА, 1999, 218 с.
3. Ризниченко Г.Ю., Рубин А.Б. Математические модели биологии продукционных процессов. М., МГУ, 1993, 299 с.
4. Рунион Р. Справочник по непараметрической статистике, М.: Финансы и статистика, 1982, 197 с.
5. Франс Дж., Торнли Дж. Математические модели в сельском хозяйстве. М., Агропромиздат, 1987, 400 с.

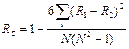 , где R1 и R2 – ранги двух признаков у i-го объекта; N – число изучаемых объектов.
, где R1 и R2 – ранги двух признаков у i-го объекта; N – число изучаемых объектов.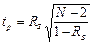 ,
,