Исходя из условий конкретной задачи, можно выбрать другой способ подготовки данных. Можно использовать нелинейные преобразования. Рассмотрим задачу прогнозирования курса доллара на следующий день на основе курсов в предыдущие дни. Хорошие результаты были получены при таком выборе выхода сети:
y = sgn (f(ti+1) – f(ti))
или y = c (f(ti+1) – f(ti))
где f(ti)— значение курса в i- й день.
От сети требуется предсказать или только направление изменения курса (первая формула), или само изменение. Оказалось, что точность предсказания в первом случае выше, чем когда предсказывается абсолютное значение курса. Направление изменения предсказывается, когда для прогнозирования точного значения недостаточно данных.
Если диапазон изменения входных данных очень велик (например, при обработке яркостной информации о реальных объектах), можно использовать логарифмическую шкалу для данных. Другие нелинейные преобразования при подготовке данных тоже находят применение.
(вставка)
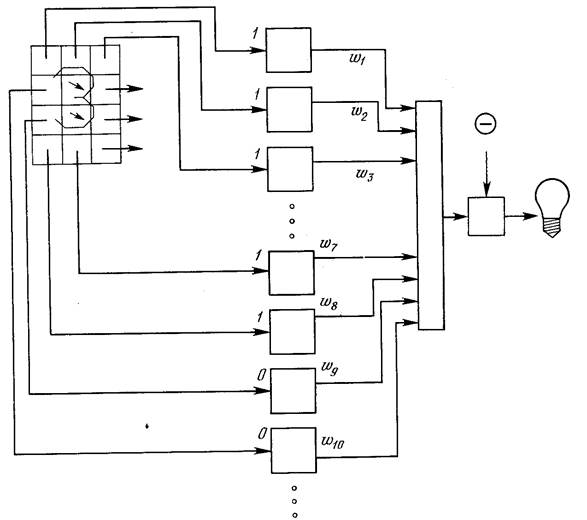
Персептрон обучают, подавая множество образов по одному на его вход и подстраивая веса до тех пор, пока для всех образов не будет достигнут требуемый выход. Допустим, что входные образы нанесены на демонстрационные карты. Каждая карта разбита на квадраты и от каждого квадрата на персептрон подается вход. Если в квадрате имеется линия, то от него подается единица, в противном случае – ноль. Множество квадратов на карте задает, таким образом, множество нулей и единиц, которое и подается на входы персептрона. Цель состоит в том, чтобы научить персептрон включать индикатор при подаче на него множества входов, задающих нечетное число, и не включать в случае четного.
Рис. 19. Персептронная система распознавания изображений
На рис. 19 показана такая персептронная конфигурация. Допустим, что вектор Х является образом распознаваемой демонстрационной карты. Каждая компонента (квадрат) Х – (x1, x2, …, xn) – умножается на соответствующую компоненту вектора весов W – (w1, w2, ..., wn). Эти произведения суммируются. Если сумма превышает порог θ, то выход нейрона Y равен единице (индикатор зажигается), в противном случае он – ноль. Эта операция компактно записывается в векторной форме как Y = XW, а после нее следует пороговая операция.
Для обучения сети образ Х подается на вход и вычисляется выход Y. Если Y правилен, то ничего не меняется. Однако если выход неправилен, то веса, присоединенные к входам, усиливающим ошибочный результат, модифицируются, чтобы уменьшить ошибку.
Чтобы увидеть, как это осуществляется, допустим, что демонстрационная карта с цифрой 3 подана на вход и выход Y равен 1 (показывая нечетность). Так как это правильный ответ, то веса не изменяются. Если, однако, на вход подается карта с номером 4 и выход Y равен единице (нечетный), то веса, присоединенные к единичным входам, должны быть уменьшены, так как они стремятся дать неверный результат. Аналогично, если карта с номером 3 дает нулевой выход, то веса, присоединенные к единичным входам, должны быть увеличены, чтобы скорректировать ошибку.
Этот метод обучения может быть сформулирован следующим образом:
1. Подать входной образ и вычислить Y.
2 а. Если выход правильный, то перейти на шаг 1;
б. Если выход неправильный и равен нулю, то добавить все входы к соответствующим им весам; или
в. Если выход неправильный и равен единице, то вычесть каждый вход из соответствующего ему веса.
3. Перейти на шаг 1.
За конечное число шагов сеть научится разделять карты на четные и нечетные при условии, что множество цифр линейно разделимо. Это значит, что для всех нечетных карт выход будет больше порога, а для всех четных – меньше. Отметим, что это обучение глобально, т. е. сеть обучается на всем множестве карт. Возникает вопрос о том, как это множество должно предъявляться, чтобы минимизировать время обучения. Должны ли элементы множества предъявляться- последовательно друг за другом или карты следует выбирать случайно? Несложная теория служит здесь путеводителем.