Нечеткая логика (fuzzy logic)возникла как наиболее удобный способ построения сложными технологическими процессами, а также нашла применение в бытовой электронике, диагностических и других экспертных системах. Математический аппарат нечеткой логики впервые был разработан в США в середине 60-х годов прошлого века, активное развитие данного метода началось и в Европе.
Классическая логика развивается с древнейших времен. Ее основоположником считается Аристотель. Логика известна нам как строгая наука, имеющая множество прикладных применений: например, именно на положениях классической (булевой) логики основан принцип действия всех современных компьютеров. Вместе с тем классическая логика имеет один существенный недостаток - с ее помощью невозможно адекватно описать ассоциативное мышление человека. Классическая логика оперирует только двумя понятиями: ИСТИНА и ЛОЖЬ (логические 1 или 0), и исключая любые промежуточные значения. Все это хорошо для вычислительных машин, но попробуйте представить весь окружающий вас мир только в черном и белом цвете, вдобавок исключив из языка любые ответы на вопросы, кроме ДА и НЕТ. В такой ситуации вам можно только посочувствовать.
Традиционная математика с ее точными и однозначными формулировками закономерностей также имеет в своей основе классическую логику. А поскольку именно математика, в свою очередь, представляет собой универсальный инструмент для описания явлений окружающего мира во всех естественных науках (физика, химия, биология и т. д.) и их прикладных приложениях (например, теория измерений, теория управления и т. д.), неудивительно все эти науки оперируют математически точными данными, такими как: «средняя скорость автомобиля на участке пути длиной 62 км равнялась 93 км/ч». Но мыслит ли в действительности человек такими категориями? Представим, что в вашей машине вышел из строя спидометр. Означает ли это, что отныне вы лишены возможности оценивать скорость вашего перемещения и не в состоянии ответить на вопросы типа «быстро ли ты доехал вчера домой?». Разумеется нет. Скорее всего вы скажете в ответ что-то вводе: «Да, довольно быстро». Собственно говоря, вы скорее всего ответите примерно в том же духе, даже и в том случае, если спидометр вашей машины был в полном порядке, поскольку, совершая поездки, не имеете привычки непрерывно отслеживать его показания в режиме реального времени. То есть, в своем естественном мышлении применительно к скорости мы склонны оперировать не точными значениями в км/ч или м/с, а приблизительными оценками типа: «медленно», «средне», «быстро» и бесчисленным множеством полутонов и промежуточных оценок: «тащился как черепаха», «катился, не торопясь», «не выбивался из потока», «ехал довольно быстро», «несся как ненормальный» и т. п.
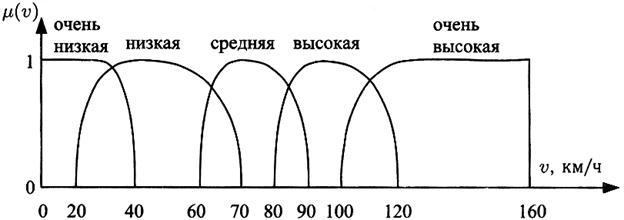
Если попытаться выразить наши интуитивные понятия о скорости графически, то получится нечто вроде рисунка ниже.
Здесь по оси X отложены значения скорости в традиционной строгой математической записи, а по оси Y – т. н. функцию принадлежности (изменяется от 0 до 1) точного значения скорости к нечеткому множеству, обозначенному тем или иным значением лингвистической переменной «скорость»: очень низкая, низкая, средняя, высокая и очень высокая. Этих градаций (гранул) может быть меньше или больше. Чем больше гранулированность нечеткой информации, тем больше она приближается к математически точной оценке (не забудем, что и выраженная в традиционной форме измерительная информация всегда обладает некоторой погрешностью, а значит в определенном смысле также является нечеткой). Таким образом, например значение скорости 105 км/ч принадлежит к нечеткому множеству «высокая» со значением функции принадлежности 0.8, а к множеству «очень высокая» со значением 0.5.
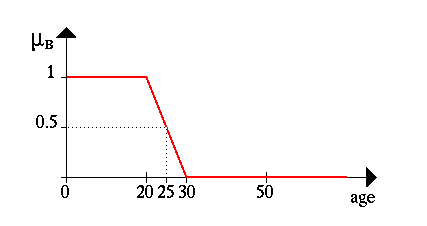
Другой пример – оценка возраста человека. Часто мы не имеем абсолютно точной информации о возрасте того или иного знакомого нам человека и поэтому, отвечая на соответствующий вопрос, вынуждены давать нечеткую оценку типа: «ему лет 30» или «ему далеко за 60» и т. п. Особенно часто используются такие значения лингвистической переменной «возраст» как: «молодой», «средних лет», «старый» и т. п. На рисунке ниже приведен графически возможный вид нечеткого множества «возраст = молодой» (очевидно, с точки зрения человека, которому самому ну никак не больше 20 лет ;)
Нечеткие числа, получаемые в результате “не вполне точных измерений”, во многом похожи (но не тождественны! см. пример с двумя бутылками) распределениям теории вероятностей, но свободны от присущих последним недостатков: малое количество пригодных к анализу функций распределения, необходимость их принудительной нормализации, соблюдение требований аддитивности, трудность обоснования адекватности математической абстракции для описания поведения фактических величин. По сравнению с точными и, тем более, вероятностными методами, нечеткие методы измерения и управления позволяют резко сократить объем производимых вычислений, что, в свою очередь, приводит к увеличению быстродействия нечетких систем.
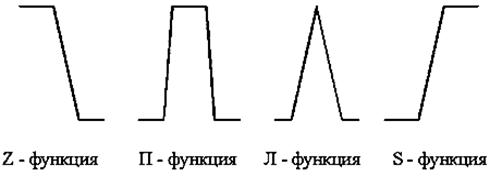
Как уже говорилось, принадлежность каждого точного значения к одному из значений лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рисунок ниже).
Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Процесс построения (графического или аналитического) функции принадлежности точных значений к нечеткому множеству называется фаззификацией данных.