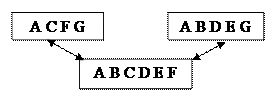1) Централизованную БД. Она хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети. Возможен распределенный доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях ПК.
2) Распределенную БД. Она состоит из нескольких, возможно повторяющихся или дублирующих друг друга частей, хранимых в различных машинах вычислительной сети. Работа в такой базе осуществляется с помощью системы управления распред-й БД (СУБДР).
По способу доступа к даннымразделяются на БД с локальным доступом и БД с удаленным(сетевым) доступом.
Системы централизованных БД с удаленным (сетевым) доступом предполагают различную архитектуру подобных систем:
1.Файл – сервер. Архитектура систем БД с сетевым доступом предполагает выделение 1 из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользователей системы к централизованной БД. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно.
рабочие станции
- хранение
- обработка
2.Клиент – сервер. В этой концепции подразумевается, что помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемые клиентом (раб.ст.) порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети к клиенту. Спецификой архитектуры клиент – сервер является использование языка запросов SQL.
рабочие станции
Виды моделей данных (МД)
Ядром любой БД является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели данных, на комбинации этих моделей или на некотором их подмножестве.
Рассмотрим 3 основных типа МД:
1) Иерархическая МД представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями образуют ориентированный граф(перевернутое дерево). Основные понятия – узел (элемент), уровень, связь.
Ур.1
Ур.3
Узел – совокупность атрибутов данных, описывающих некоторый объект. Узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на 2,3 и т.д. уровнях. Количество деревьев в БД определяется числом корневых записей. К каждой записи в БД существует только один (иерархический) путь от корневой записи. Например, для записи путь проходит через записи А и .
2) Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
3) Реляционная МД ориентирована на организацию данных в виде двумерных таблиц, и возможность использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
– каждый элемент таблицы – один элемент данных
– все столбцы однородные, т.е. все элементы в столбце имеют одинаковый тип данных и размер
– каждый столбец имеет уникальное имя
– одинаковые строки в таблице отсутствуют
– порядок следования строк и столбцов может быть произвольным
БД состоящая из реляционных таблиц называют Реляционной БД. В дальнейшем мы будем рассматривать только такие БД.
В БД совокупности данных представляются в виде простой двумерной таблицы. Примером может служить обыкновенный телефонный справочник.
TELEFON Словарь
Простейшая двумерная таблица, состоящая из одиночных строк, называется реляционной таблицей.
Каждая таблица состоит из фиксированного количества столбцов и переменного количества строк. Описание столбцов, составляемое разработчиком, называется макетом таблицы.
Каждый столбец – конкретное поле (данное)
Каждая строка таблицы называется записью
Каждое поле может входить в несколько таблиц
Каждая запись в таблице должна иметь первичный ключ, т.е. идентификатор ( или адрес), значение которого однозначно определяет эту и только эту запись. Ключ может состоять из одного поля, тогда его называют простым или из нескольких полей, тогда его называют составным ключом.
Первичный ключ должен обладать свойствами:
1. Однозначная идентификация записи, т.е. запись должна однозначно определяться значением ключа.
2. Отсутствие избыточности: никакое поле нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации.
Каждое значение первичного ключа в пределах таблицы должно быть уникальным, в противном случае невозможно отличить одну запись от другой! Фамилия никогда не может быть ключом таблицы.
Кроме первичного существует вторичный ключ. Его значение может быть неуникальным. Первичный ключ в каждой таблице может быть только один, а вторичных – множество.
Ключи используются при индексировании (упорядочивании) таблиц, для более быстрой и удобной сортировки данных. По определению ключей СУБД автоматически строит индексы, которые представляют собой механизмы быстрого доступа к хранящимся в таблице данным.
Индекс – набор указателей на строки таблицы, упорядоченный по значению ключа. Каждый элемент этого набора состоит из двух частей: порядкового номера записи в таблице и значения ключа сортировки.
Например, индекс для телефонного справочника – сортировка по возрастанию номеров:
Индексы
номер номер телефона в данной записи(по возрастанию)
записи
в таблице
Вернемся к телефонному справочнику.
В таблице «Словарь» мы можем указать те категории, для которых в таблице «Телефон» еще нет записей. Но не имеет смысла включать в таблицу «Телефон» номер, для которого не определена категория в «Словаре». Т.о., «Словарь» - главная таблица, «Телефон» - подчиненная. Главная таблица называется родительской, подчиненная – дочерней.
Данные таблицы связаны по полю категория. Категория – первичный ключ для «Словаря». И каждому значению первичного ключа в главной таблице соответствует одна, несколько или ни одной записи в подчиненной таблице. Такое отношение между двумя таблицами называется связью.
«Один – ко – многим». Это самый распространенный тип связи в реляционных БД(в телефоне может быть несколько абонентов с категорией ДР, один с РД, или ни одного с МН).
Реже встречается отношение «Один – к – одному». В этом случае каждому значению первичного ключа в главной таблице соответствует одна или ни одной записи в подчиненной таблице.
В таблице «Словарь» поле категория – первичный ключ, ключ связи в подчиненной таблице. В таблице «Телефон» поле категория – внешний ключ, т.к. ключ связи в главной таблице всегда уникальный первичный ключ.
Словарь – главная таблица. В таблице «Телефон» первичный ключ – поле Номер.
Логические связи между таблицами в реляционной БД реализуются за счет одинаковых полей в связывающих таблицах. Каждому значению первичного ключа соответствует несколько записей в подчиненной таблице и наоборот.
Реляционный подход к построению инфологической модели
Понятие информационного объекта
Информационный объект – описание некоторой сущности(реального объекта, явления, события) в виде совокупности логически связанных реквизитов (информационных элементов).
И.о. определенного реквизитного состава и структуры образует класс(тип), которому присваивается уникальное имя (или символьное обозначение). Например, Телефон, Словарь.
И.о. имеет множество реализаций – экземпляров, каждый из которых представлен совокупностью конкретных значений реквизитов и идентифицируется значением ключа(простого – один реквизит или составной -несколько реквизитов). Остальные реквизиты И.о. являются описательными. При этом одни и те же реквизиты в одних И.о. могут быть ключевыми, а в других – описательными.
Например. В И.о. телефон ключом является реквизит Номер, к описательным относятся имя, адрес, Категория.
А записи являются экземплярами И.о. Телефон.
Представляется т.о.:
Нормализация отношений
Одни и те же данные могут группироваться в таблицы (отношения) различными способами. Группировка атрибутов в отношениях должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления.
Нормализация отношений – формальный аппарат ограничения на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непр-ть данных, уменьшает трудозатраты на ведение(ввод, корректировку) БД.
Нам понадобиться def повторяющихся групп.
Пример повторяющихся групп.
Пусть разрабатывается БД системы управления персоналом. Разработчик стремиться включить как можно больше информации о работнике. Если включать все в одну основную таблицу, то придется брать число полей по максимально возможному. Допустим, ученый может иметь до 30 премий, в таблицу придется добавить 60 полей. Data N – дата премии и код N – код премии. Следовательно, большая часть значений этих полей в конкретных записях будет «пустой» (или на примере телефонного справочника).
Такую def информацию, разную по объему для каждого экземпляра, называют повторяющимися группами.
Нормализация таблиц – устранение избыточности данных.
Признаки нормализованности таблиц:
1. Каждое поле таблицы неделимо и не содержит повторяющиеся группы. Неделимость поля означает, что содержащиеся в нем значения не должны делиться на более мелкие.
2. Все поля зависят от первичного ключа, т.е. первичный ключ однозначно определяет запись, и не избыточен. Т.е. поля, которые зависят только от части первичного ключа (в случае составного ключа), должны быть выделены в составе отдельных таблиц.
3. Значение любого поля, не входящего в первичный ключ не зависит от значения другого поля, так же не входящего в первичный ключ, т.е. чтобы не было зависимостей между неключевыми полями.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные.
1а) Функциональная зависимость. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
б) Полная функциональная зависимость.Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А. Обозначается функциональная зависимость стрелочками.
2 Многозначная зависимость.Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует хорошо определенное множество соответствующих значений В.
Например, таблица Обучение.
Дисциплина
Преподаватель
Учебник
Информатика
Шипилов П.А
Форсайт Р Паскаль для всех
Информатика
Шипилов П.А
Уэйт М. и др. язык Си
Информатика
Голованевский Г.Л.
Форсайт Р Паскаль для всех
Информатика
Голованевский Г.Л.
Уэйт М. и др. язык Си
…
…
…
В ней есть многозначная зависимость « Дисциплина – Преподаватель»: дисциплина (Информатика) может читаться несколькими преподавателями( Шипиловым и Голованевским). Есть и другая многозначная зависимость «Дисциплина – Учебник»: при изучении Информатики используются учебники «Паскаль для всех» и «язык Си». При этом Преподаватель и Учебник не связаны функциональной зависимостью, что приводит к появлению избыточности( для добавления еще одного учебника придется ввести в таблицу две новых строки). Дело улучшается при замене этой таблицы на две: (Дисциплина – Преподаватель и Дисциплина – Учебник).
Таблица находится в первой нормальной форме(1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле одного значения и ни одно из ее ключевых полей не пусто. Преобразование отн-я 1НФ может привести к увеличению реквизитов таблицы и уменьшению ключа.
Таблица находится во второй нормальной форме(2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Таблица находится в третьей нормальной форме(3НФ), если она удовлетворяет определению 2НФ и не одно из ее ключевых полей не зависит от любого другого не ключевого поля.
Существует 4НФ, 5НФ – это высшие нормальные формы. Здесь они рассматриваться не будут. Для данного случая достаточно 3НФ.
Процедура нормализации основывается на том, что единственными функциональными зависимостями в любой таблице должны быть зависимости вида KF, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым KF всегда имеет место для всех полей данной таблицы. Правило нормализации «Один факт встречается в одном месте» говорит о том, что не имеют силы никакие другие функциональные зависимости. Цель нормализации состоит в том, чтобы избавиться от всех «других» функциональных зависимостей.
Возможны два случая:
1.Таблица имеет составной первичный ключ вида, скажем, (К1, К2) и включает также поле F, которое функционально зависит от части этого ключа, например, от К2, но не от полного ключа. В этом случае рекомендуется сформировать другую таблицу, содержащую К2 и F (первичный ключ – К2), и удалить F из первоначальной таблицы:
2.Таблица имеет первичный ключ К,не являющееся ключом поле F1, которое функционально зависит от К, и другое не ключевое поле F2, которое функционально зависит от F1. Формируется другая таблица, содержащая F1 и F2, с первичным ключом F1, и F2 удаляется из первоначальной таблицы:
Заменить Т( К1, К2, F), первичный ключ К, Ф3 F1F2
на Т1(К, F1), первичный ключ К,
и Т2 (F1, F2), первичный ключ F1.
Для любой заданной таблицы, повторяя применение двух рассмотренных правил, почти во всех практических ситуациях можно получить, в конечном счете, множество таблиц, которые находятся в нормальной форме и, таким образом, не содержат каких-либо функциональных зависимостей вида, отличного от КF.
С учетом рассмотренных понятий уточним понятие видов связей.
Связи между объектами существуют, если логически взаимосвязаны экземпляры из этих информационных объектов.
Связи информационных объектов могут быть разного типа:
1) Одно – однозначные связи (1:1) имеют место, когда каждому экземпляру первого объекта (А) соответствует только один экземпляр второго объекта (В) и наоборот, каждому экземпляру второго объекта (В) соответствует только один экземпляр первого объекта (А).
Такие объекты легко могут быть объединены в один, строение, которого образуется объединением реквизитов обоих исходных объектов, а в качестве ключевого реквизита может быть выбран любой из альтернативных ключей, т.е. ключей исходных объектов.
2) Одно – многозначные связи ( 1:М) характеризуется тем, что каждому экземпляру одного объекта (А) может соответствовать несколько экземпляров другого объекта (В), а каждому экземпляру второго объекта (В) может соответствовать только 1 экземпляр первого объекта (А).
главный инф- й подчиненный информационный
объект объект
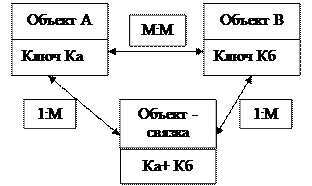
3) Много - многозначные связи (М:М)
Каждому экземпляру одного объекта (А) может соответствовать несколько экземпляров второго объекта (В) и наоборот, каждому экземпляру второго объекта (В) может соответствовать тоже несколько экземпляров первого объекта (А).
Много – многозначные связи не могут непосредственно реализовываться в реальной БД. Поэтому, если такие связи выявлены, может понадобиться их преобразование путем введения дополнительного объекта «связка». Исходные объекты будут связаны с этим объектом одно – многозначными связями. Т.о,, объект – связка является подчиненным в одно – многозначных связях по отношению к каждому из исходных объектов.
Объект – связка должен иметь идентификатор, образованный из идентификаторов исходных объектов, например, Ки К.
При рассмотренном ниже подходе к выделению информационных объектов объект – связка, как правило, выявляется в результате анализа функциональных зависимостей реквизитов. Много – многозначные связи в этом случае не требуют специальной реализации, т.к. осуществляется через объект, выполняющий роль объекта – связки.
Построение инфологической модели
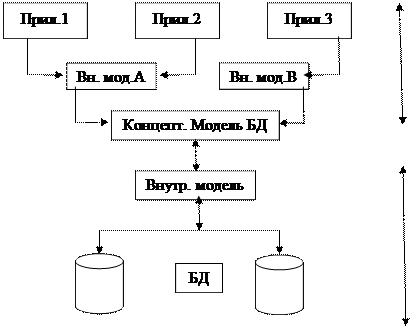
БД и СУБД имеют многоуровневую архитектуру.
Различают концептуальный, внутренний и внешний уровни представления данных БД, которые соответствуют модели аналогичного назначения.
Концептуальный уровень соответствует логическому аспекту представления данных предметной области в интегрированном виде.
Концептуальная модель состоит из множества экземпляров различных типов данных, стр-ных в соответствии с требованиями СУБД к логической структуре БД.
Внутренний уровень отображает требуемую организацию данных в среде хранения и соответствует физическому аспекту представления данных.
Внутренняя модель состоит из отдельных экземпляров записей, физически хранимых во внутренних носителях.
Внешний уровень поддерживает частные представления данных, требуемые конкретным пользователем.
Внешняя модель является подмножеством концептуальной модели.
Возможно пересечение внешних моделей по данным. Частная логическая структура данных для отдельной прил-я или пользователя соответствует внешней модели или подсхеме БД. С помощью внешних моделей поддерживается санкционированный доступ к данным БД приложений ( огромный состав и структура данных концептуальной модели БД, доступных в приложении, а также заданы допустимые режимы обработки этих данных: ввод, редактирование, удаление, поиск).
Появление новых или изменение информационных потребностей существующих приложений требуют определения для них корректных внешних моделей, при этом на уровне концептуальной и внутренней модели данных изменений не происходит.
Изменения в концептуальной модели, должны отражаться на внутренней модели, и при неизменной концептуальной модели возможна самостоятельная модификация внутренней модели БД с целью улучшению ее характеристик ( время доступа к данным, расхода памяти внешних устройств и др.).
Таким образом БД реализует принцип относительной независимости логической и физической организации данных.
Проектирование БД состоит в построении комплекса взаимосвязанных моделей данных. Важнейшим этапом проектирования БД является разработка инфологической (информационно – логической) модели предметной области, не ориентированной на СУБД.
В инфологической модели средствами структур данных в интегрированном виде отражают состав и структуру данных, а также информационные потребности приложений (задач и запросов).
Информационно – логическая (инфологическая) модель предметной области отражает предметную область в виде совокупности информационных объектов и их структурных связей. Эта модель представляет данные, подлежащие хранению в БД.
Инфологическая модель предметной области строится первой. Предварительная инфологическая модель строится еще на предпроектной стадии и затем уточняется на более поздних стадиях проектирования БД. Затем на ее основании строятся концептуальная (логическая), внутренняя (физическая) и внешняя модели.
Информационный объект – это описание некоторой сущности предметной области – реального объекта, процесса, явления или события. Информационный объект образуется совокупностью логически взаимосвязанных реквизитов, представляющих собой качественные и количественные характеристики сущности. Другими словами, информационный объект – это таблица, а реквизиты – поле.
Этапы проектирования и создания БД
Перед созданием БД необходимо располагать описанием выбранной предметной области, которое должно охватывать реальные объекты и процессы, определить все необходимые источники информации для удовлетворения предполагаемых запросов пользователя и определить потребности в обработке данных.
На основе такого описания на этапе проектирования БД определяется состав и структура данных предметной области, которые должны находиться в БД и обеспечивать выполнение необходимых запросов и задач пользователя. Структура данных предметной области отображается ИЛМ.
Определение связей между информационными объектами
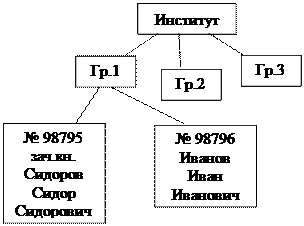
Связи между объектами ГРУППА СТУДЕНТ характеризуется отношением 1:М, т.к. одна группа включает много студентов, а один студент входит только в одну группу. Связь между ними осуществляется по номеру группы, который является уникальным идентификатором главного объекта ГРУППА и входит в составной идентификатор объекта СТУДЕНТ.
Аналогично КАФЕДРА и ПРЕПОДАВАТЕЛЬ находятся в отношении 1:М. Связь между ними осуществляется по уникальному ключу главного объекта КАФЕДРА – коду кафедры, который в подчиненном объекте ПРЕПОДАВАТЕЛЬ является описательным.
При разработке ИЛМ данных могут использоваться 2 подхода. В первом сначала определяются основные задачи для решения которых строится БД, выявляются потребности задачи в данных и определяется состав и структура информационных объектов. При втором подходе сразу устанавливаются типовые объекты предметной области. Наиболее рационально сочетание обоих подходов, тем более что Acceess позволяет на любом этапе разработки внести уменьшения в БД и модифицировать ее структуру без ущерба для уже введенных данных.
На этапе разработки модели данных необходимо выделить инф-е объекта, соответствующие требованиям нормы и определить связи между ними. Эта модель позволяет создать реляционную БД без дублирования, в которой обеспечивается однократный ввод данных при первоначальной загрузке и корректировках, а также целостность данных при внесении изменений.
При определении логической структуры реляционной БД на основе модели каждый информационный объект адекватно отображается реляционной таблицей. А связи между таблицами соответствуют связям между информационными объектами.
В процессе создания сначала конструируются таблицы БД-х Access, соответствующие информационным объектам построенной модели данных. Далее создается схема данных Access, в которой фиксируются существующие логические связи таблицами. Эти связи соответствуют связям информационных объектов. В схеме данных могу быть заданы параметры поддержания целостности БД, если модель данных была разработана в соответствии с требованиями нормализации. Целостность данных означает, что в БД установлены и корректно поддерживаются взаимосвязи между записями разных таблиц при загрузке, добавлении и удалении записей в связанных таблицах, а так же при изменении значений ключевых полей.
После формирования в Access схемы данных осуществляется ввод непротиворечивых данных из документов предметной области.
Порядок выделения информационных объектовпредметной области, отвечающих требованиям нормализации:
1. На основе описания предметной области выявить документы, подлежащие хранению в БД.
2. Определить функциональные зависимости между реквизитами.
3. Выбрать все зависимые реквизиты и указать для каждого все его ключевые реквизиты, т.е. те, от которых он зависит( один или несколько).
4. Сгруппировать реквизиты, одинаково зависимые от ключевых реквизитов. Полученные группы зависимых реквизитов вместе с их ключевыми реквизитами образуют информационные объекты.




 рабочие станции
рабочие станции - хранение
- хранение - обработка
- обработка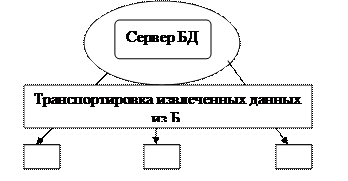
 путь проходит через записи А и
путь проходит через записи А и  .
.





 F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K
F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K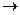 F
F



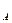 и К
и К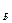 .
.