Под информационной моделью понимается модель в терминах информационных данных. Основными понятиями являются понятия информационных элементов и отношений между ними. К основным информационным моделям относятся:
1. Модели в терминах свойство – связь.
2. Реляционная модель.
3. Многомерная модель данных.
4. Объектная и объектно – реляционная модель данных.
Наиболее простой, с которой и началась история БД, является модель свойство – связь.
.Модель свойство-связь
Основными понятиями данной мод ели являются понятия информационного элемента и отношений между этими элементами.
Информационным элементом называется единая неделимая единица информации, которая характеризуется именем, типом, размером и экземпляром. Под именем понимается идентификатор, позволяющий однозначно определить данный элемент. Под типом информационного элемента будем понимать вещественный тип (E), целый (I), текстовый (T), дату (D) и Булев (B). Размером информационного элемента называется сколько места он занимает в памяти в байтах. Экземпляром информационного элемента называется одно из возможных значений, которые он может принимать. Например, информационный элемент «Ф.И.О. студента» можно задать следующим образом:
· Имя элемента - FIOS.
· Тип элемента – T.
· Размер элемента – 30 байт.
· Экземпляр элемента – Иванов С.Ю.
Основными отношениями, используемыми в данной модели данных, являются:
· Одно-однозначное отношение (1:1). Отношение между элементами A и B называется одно-однозначным, если одному экземпляру A соответствует один экземпляр B, и наоборот. Это отношение обозначается A(1:1)B и изображается в виде:
Примером такого отношения может служить ИНН и номер пенсионного страхования.
· Одно – многозначное отношение (1:n). Отношение между элементами A, B называется одно – многозначным, если одному экземпляру A соответствует несколько экземпляров B, но одному экземпляру B соответствует один экземпляр. Такое отношение обозначается A(1:n)B и изображается:
Примером такого отношения может служить № группы и № зачетки.
· Много – многозначное отношение (m:n). Элементы A, B находятся в много – многозначном отношении, если одному экземпляру A соответствует много экземпляров B и наоборот.
Если это особо не оговорено, то на графе связь не изображается. В противном случае изображается следующим образом:
Примером такого отношения может служить № зачетки студента и ИНН преподавателя.
Таким образом, модель свойство-связь можно представить в виде графа. Для построения этого графа используется графический метод проектирования.
Графический метод проектирования
Графический метод проектирования состоит из следующих этапов:
1. Выделение информационных элементов и связей между ними.
2. Агрегирование элементов.
3. Удаление транзитивных зависимостей.
4. Введение фиктивных элементов.
Выделение информационных элементов можно проводить с помощью двух подходов: функционального и объектного. В первом случае анализируются задачи, которые предполагается решать с использованием данного приложения базы данных. Например, если в ходе эксплуатации приложения предполагается необходимость ответа на запрос:
Здесь «В какой группе» является целевой частью запроса, в которой можно рассматривать № группы,как информационный элемент, а «обучается студент» - квалифицирующая часть, где Иванов М. М. – экземпляр информационного элемента Ф. И. О. студента.Недостатком данного подхода является то, что при изменении запросов, в БД может не оказаться требуемая информация. При объектном подходе анализируется объект, для которого строится база, и в нее вносятся все возможные элементы, выявляемые в ходе анализа. Недостатком данного подхода является то, что база может оказаться избыточной, и в нее могут быть включены элементы, к которым не будет проводиться обращение. Поэтому на практике используют комбинацию подходов. Пусть в ходе выделения информационных элементов был выделены следующие элементы:
№
Имя
Тип
Размер
Экземпляр
Факультет
Текстовый
ФИТ
№ группы
Текстовый
АП51
№ зачетки
Текстовый
АП03\5
№ пропуска
Текстовый
АП03\5
Ф.И.О. студента
Текстовый
Иванов М.М.
Кафедра
Текстовый
ИТАС
Ф.И.О. преподавателя
Текстовый
Попов С.Н.
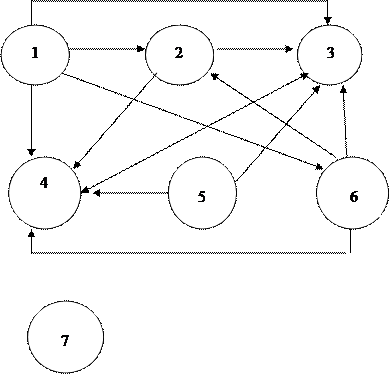
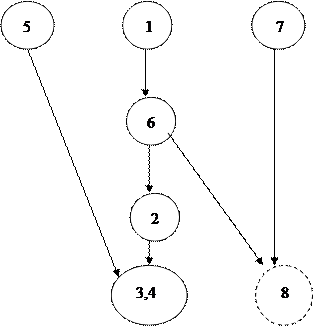
Для установления связей анализируется каждая пара информационных элементов. Получаем:
Здесь предполагается, что среди студентов и преподавателей могут быть однофамильцы.
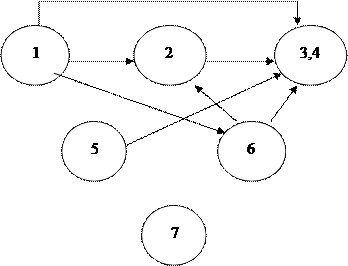
На следующем шаге агрегируются (объединяются) информационные элементы, находящиеся в одно-однозначном соответствии. Такими элементами являются № зачетки и № пропуска. Получаем новый граф:
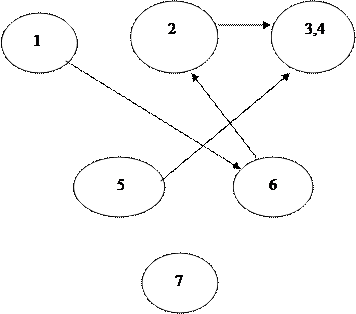
На следующем шаге удаляются транзитивные связи. Транзитивные связи имеют на графе следующий вид:
Здесь можно удалить перечеркнутую связь. Фактически задача сводится к оставлению в графе путей наибольшей длины, связывающих вершины. В нашем случае получим:
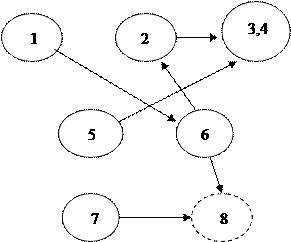
Недостаток этого графа заключается в том, что он не является связанным. Для того чтобы устранить этот недостаток вводится фиктивный информационный элемент, который находился бы в одно-многозначном соответствии с какими-либо элементами несвязанных подграфов. Для нашего примера таким элементом является ИНН преподавателя.Получаем:
Такой граф принято изображать следующим образом. На верхнем уровне изображаются корневые вершины, а на нижнем – вершины листья.
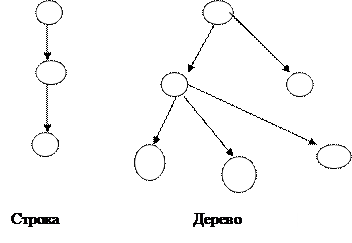
В зависимости от получаемого графа различают три структуры данных: строка, дерево, сеть.
Граф, полученный в примере, соответствует сети.
Строка – это такая структура данных, в которой в вершину входит не более одной дуги, и выходит из нее также не более одной дуги (плоские БД).
В структуре данных дерево в вершину входит не более одной дуги, а исходит из нее сколь угодно много (иерархические БД – IMS).
В сети в вершину может входить сколь угодно много дуг и из вершины также выходит сколь угодно много дуг (сетевые БД – IDMS).