Рис. 14.2. Пример разрешения имен с использованием DNS-серверов
В действительности, каждый сервер DNS имеет достаточно большой кэш, содержащий адреса серверов DNS для всех последних запросов. Поэтому реальная схема обычно существенно проще, из приведенной цепочки общения DNS-серверов выпадают многие звенья за счет обращения напрямую.
Рассмотренный способ разрешения адресов позволяет легко добавлять компьютеры в сеть и исключать их из сети, так как для этого необходимо внести изменения только на DNS-сервере соответствующей области.
Если DNS-сервер, отвечающий за какую-либо область, выйдет из строя, то может оказаться невозможным разрешение адресов для всех компьютеров этой области. Поэтому обычно назначается не один сервер DNS, а два - основной и запасной. В случае выхода из строя основного сервера его функции немедленно начинает выполнять запасной.
В реальных сетевых вычислительных системах обычно используется комбинация рассмотренных подходов. Для компьютеров, с которыми чаще всего приходится устанавливать связь, в специальном файле хранится таблица соответствий символьных и числовых адресов. Все остальные адреса разрешаются с использованием служб, аналогичных службе DNS. Способ построения удаленных адресов и методы разрешения адресов обычно определяются протоколами сетевого уровня эталонной модели.
Мы разобрались с проблемой удаленных адресов и знаем, как получить числовой удаленный адрес нужного нам компьютера. Давайте рассмотрим теперь проблему адресов локальных: как нам задать адрес процесса или объекта для хранения данных на удаленном компьютере, который в конечном итоге и должен получить переданную информацию.
Локальная адресация. Понятие порта.Во второй лекции мы говорили, что каждый процесс, существующий в данный момент в вычислительной системе, уже имеет собственный уникальный номер –PID. Но этот номер неудобно использовать в качестве локального адреса процесса при организации удаленной связи. Номер, который получает процесс при рождении, определяется моментом его запуска, предысторией работы вычислительного комплекса и является в значительной степени случайным числом, изменяющимся от запуска к запуску. Представьте себе, что адресат, с которым вы часто переписываетесь, постоянно переезжает с место на место, меняя адреса, так что, посылая очередное письмо, вы не можете с уверенностью сказать, где он сейчас проживает, и поймете все неудобство использования идентификатора процесса в качестве его локального адреса. Все сказанное выше справедливо и для идентификаторов промежуточных объектов, использующихся при локальном взаимодействии процессов в схемах с непрямой адресацией.
Для локальной адресации процессов и промежуточных объектов при удаленной связи обычно организуется новое специальное адресное пространство, например представляющее собой ограниченный набор положительных целочисленных значений или множество символических имен, аналогичных полным именам файлов в файловых системах. Каждый процесс, желающий принять участие в сетевом взаимодействии, после рождения закрепляет за собой один или несколько адресов в этом адресном пространстве. Каждому промежуточному объекту при его создании присваивается свой адрес из этого адресного пространства. При этом удаленные пользователи могут заранее договориться о том, какие именно адреса будут зарезервированы для данного процесса, независимо от времени его старта, или для данного объекта, независимо от момента его создания. Подобные адреса получили название портов, по аналогии с портами ввода-вывода.
Необходимо отметить, что в системе может существовать несколько таких адресных пространств для различных способов связи. При получении данных от удаленного процесса операционная система смотрит, на какой порт и для какого способа связи они были отправлены, определяет процесс, который заявил этот порт в качестве своего адреса, или объект, которому присвоен данный адрес, и доставляет полученную информацию адресату. Виды адресного пространства портов (т.е. способы построения локальных адресов) определяются, как правило, протоколами транспортного уровня эталонной модели.
Полные адреса. Понятие сокета (socket).Таким образом, полный адрес удаленного процесса или промежуточного объекта для конкретного способа связи с точки зрения операционных систем определяется парой адресов: <числовой адрес компьютера в сети, порт>. Подобная пара получила наименование socket (в переводе – "гнездо" или, как стали писать в последнее время, сокет), а сам способ их использования – организация связи с помощью сокетов. В случае непрямой адресации с использованием промежуточных объектов сами эти объекты также принято называть сокетами. Поскольку разные протоколы транспортного уровня требуют разных адресных пространств портов, то для каждой пары надо указывать, какой транспортный протокол она использует, – говорят о разных типах сокетов.
В современных сетевых системах числовой адрес обычно получает не сам вычислительный комплекс, а его сетевой адаптер, с помощью которого комплекс подключается к линии связи. При наличии нескольких сетевых адаптеров для разных линий связи один и тот же вычислительный комплекс может иметь несколько числовых адресов. В таких системах полные адреса удаленного адресата (процесса или промежуточного объекта) задаются парами <числовой адрес сетевого адаптера, порт> и требуют доставки информации через указанный сетевой адаптер.
14.8. Проблемы маршрутизации в сетях
При наличии прямой линии связи между двумя компьютерами обычно не возникает вопросов о том, каким именно путем должна быть доставлена информация. Но, как уже упоминалось, одно из отличий взаимодействия удаленных процессов от взаимодействия процессов локальных состоит в использовании в большинстве случаев процессов-посредников, расположенных на вычислительных комплексах, не являющихся комплексами отправителя и получателя. В сложных топологических схемах организации сетей информация между двумя компьютерами может передаваться по различным путям. Возникает вопрос: как организовать работу операционных систем на комплексах - участниках связи (это могут быть конечные или промежуточные комплексы) для определения маршрута передачи данных? По какой из нескольких линий связи (или через какой сетевой адаптер) нужно отправить пакет информации? Какие протоколы маршрутизации возможны? Существует два принципиально разных подхода к решению этой проблемы: маршрутизация от источника передачи данных и одношаговая маршрутизация.
- Маршрутизация от источника передачи данных. При маршрутизации от источника данных полный маршрут передачи пакета по сети формируется на компьютере-отправителе в виде последовательности числовых адресов сетевых адаптеров, через которые должен пройти пакет, чтобы добраться до компьютера-получателя, и целиком включается в состав этого пакета. В этом случае промежуточные компоненты сети при определении дальнейшего направления движения пакета не принимают самостоятельно никаких решений, а следуют указаниям, содержащимся в пакете.
- Одношаговая маршрутизация. При одношаговой маршрутизации каждый компонент сети, принимающий участие в передаче информации, самостоятельно определяет, какому следующему компоненту, находящемуся в зоне прямого доступа, она должна быть отправлена. Решение принимается на основании анализа содержащегося в пакете адреса получателя. Полный маршрут передачи данных складывается из одношаговых решений, принятых компонентами сети.
Маршрутизация от источника передачи данных легко реализуется на промежуточных компонентах сети, но требует полного знания маршрутов на конечных компонентах. Она достаточно редко используется в современных сетевых системах, и далее мы ее рассматривать не будем.
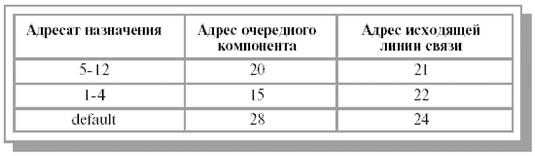
Для работы алгоритмов одношаговой маршрутизации, которые являются основой соответствующих протоколов, на каждом компоненте сети, имеющем возможность передавать информацию более чем одному компоненту, обычно строится специальная таблица маршрутов (рис. 14.3). В простейшем случае каждая запись такой таблицы содержит: адрес вычислительного комплекса получателя; адрес компонента сети, напрямую подсоединенного к данному, которому следует отправить пакет, предназначенный для этого получателя; указание о том, по какой линии связи (через какой сетевой адаптер) должен быть отправлен пакет. Поскольку получателей в сети существует огромное количество, для сокращения числа записей в таблице маршрутизации обычно прибегают к двум специальным приемам.
Во-первых, числовые адреса типологически близко расположенных комплексов (например, комплексов, принадлежащих одной локальной вычислительной сети) стараются выбирать из последовательного диапазона адресов. В этом случае запись в таблице маршрутизации может содержать не адрес конкретного получателя, а диапазон адресов для некоторой сети (номер сети).
Во-вторых, если для очень многих получателей в качестве очередного узла маршрута используется один и тот же компонент сети, а остальные маршруты выбираются для ограниченного числа получателей, то в таблицу явно заносятся только записи для этого небольшого количества получателей, а для маршрута, ведущего к большей части всей сети, делается одна запись -маршрутизация по умолчанию (default). Пример простой таблицы маршрутизации для некоторого комплекса некой абстрактной сети приведен ниже:
Рис. 14.3. Простая таблица маршрутизации
По способам формирования и использования таблиц маршрутизации алгоритмы одношаговой маршрутизации можно разделить на три класса:
- алгоритмы фиксированной маршрутизации;
- алгоритмы простой маршрутизации;
- алгоритмы динамической маршрутизации.
При фиксированной маршрутизации таблица, как правило, создается в процессе загрузки операционной системы. Все записи в ней являются статическими. Линия связи, которая будет использоваться для доставки информации от данного узла к некоторому узлу A в сети, выбирается раз и навсегда. Обычно линии выбирают так, чтобы минимизировать полное время доставки данных. Преимуществом этой стратегии является простота реализации. Основной же недостаток заключается в том, что при отказе выбранной линии связи данные не будут доставлены, даже если существует другой физический путь для их передачи.
В алгоритмах простой маршрутизации таблица либо не используется совсем, либо строится на основе анализа адресов отправителей приходящих пакетов информации. Различают несколько видов простой маршрутизации – случайную, лавинную и маршрутизацию по прецедентам. При случайной маршрутизации прибывший пакет отсылается в первом попавшемся направлении, кроме исходного. При лавинной маршрутизации один и тот же пакет рассылается по всем направлениям, кроме исходного. Случайная и лавинная маршрутизации, естественно, не используют таблиц маршрутов. При маршрутизации по прецедентам таблица маршрутизации строится по предыдущему опыту, исходя из анализа адресов отправителей приходящих пакетов. Если прибывший пакет адресован компоненту сети, от которого когда-либо приходили данные, то соответствующая запись об этом содержится в таблице маршрутов, и для дальнейшей передачи пакета выбирается линия связи, указанная в таблице. Если такой записи нет, то пакет может быть отослан случайным или лавинным способом. Алгоритмы простой маршрутизации действительно просты в реализации, но отнюдь не гарантируют доставку пакета указанному адресату за приемлемое время и по рациональному маршруту без перегрузки сети.
Наиболее гибкими являются алгоритмы динамической или адаптивной маршрутизации, которые умеют обновлять содержимое таблиц маршрутов на основе обработки специальных сообщений, приходящих от других компонентов сети, занимающихся маршрутизацией, удовлетворяющих определенному протоколу. Такие алгоритмы принято делить на два подкласса: алгоритмы дистанционно-векторные и алгоритмы состояния связей.
При дистанционно-векторной маршрутизации компоненты операционных систем на соседних вычислительных комплексах сети, занимающиеся выбором маршрута (их принято называть маршрутизатор или router), периодически обмениваются векторами, которые представляют собой информацию о расстояниях от данного компонента до всех известных ему адресатов в сети. Под расстоянием обычно понимается количество переходов между компонентами сети h(ops), которые необходимо сделать, чтобы достичь адресата, хотя возможно существование и других метрик, включающих скорость и/или стоимость передачи пакета по линии связи. Каждый такой вектор формируется на основании таблицы маршрутов. Пришедшие от других комплексов векторы модернизируются с учетом расстояния, которое они прошли при последней передаче. Затем в таблицу маршрутизации вносятся изменения, так чтобы в ней содержались только маршруты с кратчайшими расстояниями. При достаточно длительной работе каждый маршрутизатор будет иметь таблицу маршрутизации с оптимальными маршрутами ко всем потенциальным адресатам.
Векторно-дистанционные протоколы обеспечивают достаточно разумную маршрутизацию пакетов, но не способны предотвратить возможность возникновения маршрутных петель при сбоях в работе сети. Поэтому векторно-дистанционная маршрутизация может быть эффективна только в относительно небольших сетях. Для больших сетей применяются алгоритмы состояния связей, на каждом маршрутизаторе строящие графы сети, в качестве узлов которого выступают ее компоненты, а в качестве ребер, обладающих стоимостью, существующие между ними линии связи. Маршрутизаторы периодически обмениваются графами и вносят в них изменения. Выбор маршрута связан с поиском оптимального по стоимости пути по такому графу.
Обычно вычислительные сети используют смесь различных стратегий маршрутизации. Для одних адресов назначения может использоваться фиксированная маршрутизация, для других – простая, для третьих – динамическая. В локальных вычислительных сетях обычно используются алгоритмы фиксированной маршрутизации, в отличие от глобальных вычислительных сетей, в которых в основном применяют алгоритмы адаптивной маршрутизации. Протоколы маршрутизации относятся к сетевому уровню эталонной модели.
14.9. Связь с установлением логического соединения и передача данных с помощью сообщений
Рассказывая об отличиях взаимодействия локальных и удаленных процессов, мы упомянули, что в основе всех средств связи на автономном компьютере так или иначе лежит механизм совместного использования памяти, в то время как в основе всех средств связи между удаленными процессами лежит передача сообщений. Неудивительно, что количество категорий средств удаленной связи сокращается до одной – канальных средств связи. Обеспечивать интерфейс для сигнальных средств связи и разделяемой памяти, базируясь на передаче пакетов данных, становится слишком сложно и дорого.
Рассматривая канальные средства связи для локальных процессов в лекции 4, мы говорили о существовании двух моделей передачи данных по каналам связи (теперь мы можем говорить о двух принципиально разных видах протоколов организации канальной связи): поток ввода-вывода и сообщения. Для общения удаленных процессов применяются обе модели, однако теперь уже более простой моделью становится передача информации с помощью сообщений. Реализация различных моделей происходит на основе протоколов транспортного уровня OSI/ISO.
Транспортные протоколы связи удаленных процессов, которые предназначены для обмена сообщениями, получили наименование протоколов без установления логического соединения (connectionless) или протоколов обмена датаграммами, поскольку само сообщение здесь принято называть датаграммой (datagramm) или дейтаграммой. Каждое сообщение адресуется и посылается процессом индивидуально. С точки зрения операционных систем все датаграммы – это независимые единицы, не имеющие ничего общего с другими датаграммами, которыми обмениваются эти же процессы.
Необходимо отметить, что с точки зрения процессов, обменивающихся информацией, датаграммы, конечно, могут быть связаны по содержанию друг с другом, но ответственность за установление и поддержание этой семантической связи лежит не на сетевых частях операционных систем, а на самих пользовательских взаимодействующих процессах (вышележащие уровни эталонной модели).
По-другому обстоит дело с транспортными протоколами, которые поддерживают потоковую модель.
Они получили наименование протоколов, требующих установления логического соединения (connection-oriented). И в их основе лежит передача данных с помощью пакетов информации. Но операционные системы сами нарезают эти пакеты из передаваемого потока данных, организовывают правильную последовательность их получения и снова объединяют полученные пакеты в поток, так что с точки зрения взаимодействующих процессов после установления логического соединения они имеют дело с потоковым средством связи, напоминающим pipe или FIFO. Эти протоколы должны обеспечивать надежную связь.
14.10. Синхронизация удаленных процессов
Мы рассмотрели основные принципы логической организации сетевых средств связи, внешние по отношению к взаимодействующим процессам. Однако, как отмечалось в лекции 5, для корректной работы таких процессов необходимо обеспечить определенную их синхронизацию, которая устранила бы возникновение race condition на соответствующих критических участках. Вопросы синхронизации удаленных процессов обычно рассматриваются в курсах, посвященных распределенным операционным системам.
14.11. Выводы по лекции 14
Основными причинами объединения компьютеров в вычислительные сети являются потребности в разделении ресурсов, ускорении вычислений, повышении надежности и облегчении общения пользователей.
Вычислительные комплексы в сети могут находиться под управлением сетевых или распределенных вычислительных систем. Основой для объединения компьютеров в сеть служит взаимодействие удаленных процессов. При рассмотрении вопросов организации взаимодействия удаленных процессов нужно принимать во внимание основные отличия их кооперации от кооперации локальных процессов.
Базой для взаимодействия локальных процессов служит организация общей памяти, в то время как для удаленных процессов – это обмен физическими пакетами данных.
Организация взаимодействия удаленных процессов требует от сетевых частей операционных систем поддержки определенных протоколов. Сетевые средства связи обычно строятся по "слоеному" принципу. Формальный перечень правил, определяющих последовательность и формат сообщений, которыми обмениваются сетевые компоненты различных вычислительных систем, лежащие на одном уровне, называется сетевым протоколом. Каждый уровень слоеной системы может взаимодействовать непосредственно только со своими вертикальными соседями, руководствуясь четко закрепленными соглашениями – вертикальными протоколами или интерфейсами. Вся совокупность интерфейсов и сетевых протоколов в сетевых системах, построенных по слоеному принципу, достаточная для организации взаимодействия удаленных процессов, образует семейство протоколов или стек протоколов.
Удаленные процессы, в отличие от локальных, при взаимодействии обычно требуют двухуровневой адресации при своем общении. Полный адрес процесса состоит из двух частей: удаленной и локальной.
Для удаленной адресации используются символьные и числовые имена узлов сети. Перевод имен из одной формы в другую (разрешение имен) может осуществляться с помощью централизованно обновляемых таблиц соответствия полностью на каждом узле или с использованием выделения зон ответственности специальных серверов. Для локальной адресации процессов применяются порты. Упорядоченная пара из адреса узла в сети и порта получила название socket.
Для доставки сообщения от одного узла к другому могут использоваться различные протоколы маршрутизации.
С точки зрения пользовательских процессов обмен информацией может осуществляться в виде датаграмм или потока данных.
ЛЕКЦИЯ 15. ОСНОВНЫЕ ПОНЯТИЯ ИНФОРМАЦИОННОЙ БЕЗОПАСНОСТИ
15.1. Введение
В октябре 1988г. в США произошло событие, названное специалистами крупнейшим нарушением безопасности американских компьютерных систем из когда-либо случавшихся. 23-летний студент выпускного курса Корнельского университета Роберт Т. Моррис запустил в компьютерной сети ARPANET программу, представлявшую собой редко встречающуюся разновидность компьютерных вирусов - сетевых "червей". В результате атаки был полностью или частично заблокирован ряд общенациональных компьютерных сетей, в частности Internet, CSnet, NSFnet, BITnet, ARPANET и несекретная военная сеть Milnet. В итоге вирус поразил более 6200 компьютерных систем по всей Америке, включая системы многих крупнейших университетов, институтов, правительственных лабораторий, частных фирм, военных баз, клиник, агентства NASA. Общий ущерб от этой атаки оценивается специалистами минимум в 100 млн. долл. Р. Моррис был исключен из университета с правом повторного поступления через год и приговорен судом к штрафу в 270 тыс. долл. и трем месяцам тюремного заключения.
Важность решения проблемы информационной безопасности в настоящее время общепризнанна, подтверждением чему служат громкие процессы о нарушении целостности систем. Убытки ведущих компаний в связи с нарушениями безопасности информации составляют триллионы долларов, причем только треть опрошенных компаний смогли определить количественно размер потерь. Проблема обеспечения безопасности носит комплексный характер, для ее решения необходимо сочетание законодательных, организационных и программно-технических мер.
Таким образом, обеспечение информационной безопасности требует системного подхода и нужно использовать разные средства и приемы - морально-этические, законодательные, административные и технические. Нас будут интересовать последние. Технические средства реализуются программным и аппаратным обеспечением и решают разные задачи по защите, они могут быть встроены в операционные системы либо могут быть реализованы в виде отдельных продуктов. Во многих случаях центр тяжести смещается в сторону защищенности операционных систем.
Есть несколько причин для реализации дополнительных средств защиты. Наиболее очевидная - помешать внешним попыткам нарушить доступ к конфиденциальной информации. Не менее важно, однако, гарантировать, что каждый программный компонент в системе использует системные ресурсы только способом, совместимым с установленной политикой применения этих ресурсов. Такие требования абсолютно необходимы для надежной системы. Кроме того, наличие защитных механизмов может увеличить надежность системы в целом за счет обнаружения скрытых ошибок интерфейса между компонентами системы. Раннее обнаружение ошибок может предотвратить "заражение" неисправной подсистемой остальных.
Политика в отношении ресурсов может меняться в зависимости от приложения и с течением времени. Операционная система должна обеспечивать прикладные программы инструментами для создания и поддержки защищенных ресурсов. Здесь реализуется важный для гибкости системы принцип - отделение политики от механизмов. Механизмы определяют, как может быть сделано что-либо, тогда как политика решает, что должно быть сделано. Политика может меняться в зависимости от места и времени. Желательно, чтобы были реализованы по возможности общие механизмы, тогда как изменение политики требует лишь модификации системных параметров или таблиц.
К сожалению, построение защищенной системы предполагает необходимость склонить пользователя к отказу от некоторых интересных возможностей. Например, письмо, содержащее в качестве приложения документ в формате Word, может включать макросы. Открытие такого письма влечет за собой запуск чужой программы, что потенциально опасно. То же самое можно сказать про Web-страницы, содержащие апплеты. Вместо критического отношения к использованию такой функциональности пользователи современных компьютеров предпочитают периодически запускать антивирусные программы и читать успокаивающие статьи о безопасности Java.
15.2. Угрозы безопасности
Знание возможных угроз, а также уязвимых мест защиты, которые эти угрозы обычно эксплуатируют, необходимо для того, чтобы выбирать наиболее экономичные средства обеспечения безопасности.
Считается, что безопасная система должна обладать свойствами конфиденциальности, доступности и целостности. Любое потенциальное действие, которое направлено на нарушение конфиденциальности целостности и доступности информации, называется угрозой. Реализованная угроза называется атакой.
Конфиденциальная (confidentiality) система обеспечивает уверенность в том, что секретные данные будут доступны только тем пользователям, которым этот доступ разрешен (такие пользователи называются авторизованными). Под доступностью (availability) понимают гарантию того, что авторизованным пользователям всегда будет доступна информация, которая им необходима. И наконец, целостность (integrity) системы подразумевает, что неавторизованные пользователи не могут каким-либо образом модифицировать данные.
Защита информации ориентирована на борьбу с так называемыми умышленными угрозами, то есть с теми, которые, в отличие от случайных угроз (ошибок пользователя, сбоев оборудования и др.), преследуют цель нанести ущерб пользователям ОС.
Умышленные угрозы подразделяются на активные и пассивные. Пассивная угроза – несанкционированный доступ к информации без изменения состояния системы, активная – несанкционированное изменение системы. Пассивные атаки труднее выявить, так как они не влекут за собой никаких изменений данных. Защита против пассивных атак базируется на средствах их предотвращения.
Можно выделить несколько типов угроз. Наиболее распространенная угроза – попытка проникновения в систему под видом легального пользователя, например попытки угадывания и подбора паролей. Более сложный вариант – внедрение в систему программы, которая выводит на экран слово login. Многие легальные пользователи при этом начинают пытаться входить в систему, и их попытки могут протоколироваться. Такие безобидные с виду программы, выполняющие нежелательные функции, называются "троянскими конями". Иногда удается торпедировать работу программы проверки пароля путем многократного нажатия клавиш del, break, cancel и т.д. Для защиты от подобных атак ОС запускает процесс, называемый аутентификацией пользователя (см. лекцию 16, раздел "Идентификация и аутентификация").
Угрозы другого рода связаны с нежелательными действиями легальных пользователей, которые могут, например, предпринимать попытки чтения страниц памяти, дисков и лент, которые сохранили информацию, связанную с предыдущим использованием. Защита в таких случаях базируется на надежной системе авторизации (см. лекцию 16, раздел "Авторизация. Разграничение доступа к объектам ОС"). В эту категорию также попадают атаки типа отказ в обслуживании, когда сервер затоплен мощным потоком запросов и становится фактически недоступным для отдельных авторизованных пользователей.
Наконец, функционирование системы может быть нарушено с помощью программ-вирусов или программ - "червей", которые специально предназначены для того, чтобы причинить вред или недолжным образом использовать ресурсы компьютера. Общее название угроз такого рода - вредоносные программы (malicious software). Обычно они распространяются сами по себе, переходя на другие компьютеры через зараженные файлы, дискеты или по электронной почте. Наиболее эффективный способ борьбы с подобными программами - соблюдение правил "компьютерной гигиены". Многопользовательские компьютеры меньше страдают от вирусов по сравнению с персональными, поскольку там имеются системные средства защиты.
Таковы основные угрозы, на долю которых приходится львиная доля ущерба, наносимого информационным системам.
Обеспечение безопасности имеет и правовые аспекты, но это уже выходит за рамки данного курса.
15.3. Формализация подхода к обеспечению информационной безопасности
Проблема информационной безопасности оказалась настолько важной, что в ряде стран были выпущены основополагающие документы, в которых регламентированы основные подходы к проблеме информационной безопасности. В результате оказалось возможным ранжировать информационные системы по степени надежности.
Наиболее известна оранжевая (по цвету обложки) книга Министерства обороны США 1993 года. В этом документе определяется четыре уровня безопасности - D, С, В и А. По мере перехода от уровня D до А к надежности систем предъявляются все более жесткие требования. Уровни С и В подразделяются на классы (Cl, C2, Bl, B2, ВЗ). Чтобы система в результате процедуры сертификации могла быть отнесена к некоторому классу, ее защита должна удовлетворять оговоренным требованиям.
В качестве примера рассмотрим требования класса С2, которому удовлетворяют ОС Windows NT, отдельные реализации Unix и ряд других.
- Каждый пользователь должен быть идентифицирован уникальным входным именем и паролем для входа в систему. Доступ к компьютеру предоставляется лишь после аутентификации.
- Система должна быть в состоянии использовать эти уникальные идентификаторы, чтобы следить за действиями пользователя (управление избирательным доступом). Владелец ресурса (например, файла) должен иметь возможность контролировать доступ к этому ресурсу.
- Операционная система должна защищать объекты от повторного использования. Перед выделением новому пользователю все объекты, включая память и файлы, должны инициализироваться.