Процесс обучения сети RBF с учетом выбранного типа радиальной базисной функции сводится:
· к подбору центров и параметров формы базисных функций (часто используются алгоритмы обучения без учителя);
· к подбору весов нейронов выходного слоя (часто используются алгоритмы обучения с учителем).
Подбор количества базисных функций, каждой из которых соответствует один скрытый нейрон, считается основной проблемой, возникающей при корректном решении задачи аппроксимации. Как и при использовании сигмоидальных сетей, слишком малое количество нейронов не позволяет уменьшить в достаточной степени погрешность обобщения множества обучающих данных, тогда как слишком большое их число увеличивает погрешность выводимого решения на множестве тестирующих данных. Подбор необходимого и достаточного количества нейронов зависит от многих факторов. Как правило, количество базисных функций K составляет определенную долю от объема обучающих данных p, причем фактическая величина этой доли зависит от размерности вектора x и от разброса ожидаемых значений , соответствующих входным векторам , для t=1,2,…,p.
Процесс самоорганизации обучающих данных автоматически разделяет пространство на так называемые области Вороного, определяющие различающиеся группы данных. Данные, сгруппированные внутри кластера, представляются центральной точкой, определяющей среднее значение всех его элементов. Центр кластера отождествляется с центром соответствующей радиальной функции.
Разделение данных на кластеры можно выполнить с использованием алгоритма К-усреднений.
Согласно этому алгоритму центры радиальных базисных функций размещаются только в тех областях входного пространства, в которых имеются информативные данные. Если обучающие данные представляют непрерывную функцию, начальные значения центров в первую очередь размещают в точках, соответствующих всем максимальным и минимальным значениям функции.
Пусть - число нейронов скрытого слоя, t – номер итерации алгоритма. Тогда алгоритм К-усреднений можно описать следующим образом [6]:
1. Инициализация. Случайным образом выбираем начальные значения центров из усреднённых значений входных векторов, которые должны быть различны. При этом значения эвклидовой нормы по возможности должны быть небольшими.
2. Выборка. Выбираем вектор из входного пространства.
3. Определение центра-победителя. Выбираем центр , ближайший к , для которого выполняется соотношение:
4. Уточнение. Центр-победитель подвергается уточнению в соответствии с формулой (4.6):
(4.6)
где h - коэффициент обучения, имеющий малое значение (обычно h<<1), причем уменьшающееся во времени. Остальные центры не изменяются.
5. Продолжение. Увеличиваем на единицу значение t и возвращаемся к шагу 2, пока положение центров не стабилизируется.
Также применяется разновидность алгоритма, в соответствии с которой значение центра-победителя уточняется в соответствии с формулой (4.6), а один или несколько ближайших к нему центров отодвигаются в противоположном направлении, и этот процесс реализуется согласно выражению
(4.7)
Такая модификация алгоритма позволяет отдалить центры, расположенные близко друг к другу, что обеспечивает лучшее обследование всего пространства данных (h1<h).
После фиксации местоположения центров проводится подбор значений параметров , соответствующих конкретным базисным функциям. Параметр радиальной функции влияет на форму функции и величину области ее охвата, в которой значение этой функции не равно нулю. Подбор должен проводится таким образом, чтобы области охвата всех радиальных функций накрывали все пространство входных данных, причем любые две зоны могут перекрываться только в незначительной степени. При такой организации подбора значения , реализуемое радиальной сетью отображение функции будет относительно монотонным.
Для расчета может быть применен алгоритм, при котором на значение влияет на расстояние между i-м центром и его R ближайшими соседями. В этом случае значение определяется по формуле (4.8):
. (4.8)
На практике значение R обычно лежит в интервале [3; 5].
Данный алгоритм обеспечивает только локальную оптимизацию, зависящую от начальных условий и параметров процесса обучения.
При неудачно выбранных начальных условиях, некоторые центры могут застрять в области, где количество обучающих данных ничтожно мало, либо они вообще отсутствуют. Следовательно, процесс модификации центров затормозится или остановится.
Для решения данной проблемы могут быть применены два различных подхода:
1. Задать фиксированные значения h для каждого центра. Центр, наиболее близкий к текущему вектору x, модифицируется сильнее, остальные - обратно пропорционально их расстоянию до этого текущего вектора x.
2. Использовать взвешенную меру расстояния от каждого центра до вектора x. Весовая норма делает «фаворитами» те центры, которые реже всего побеждают.
Оба подхода не гарантируют 100% оптимальность решения.
Подбор коэффициента h тоже является проблемой. Если h имеет постоянное значение, то оно должно быть мало, чтобы обеспечить сходимость алгоритма, следовательно, увеличивается время обучения.
Адаптивные методы позволяют уменьшать значение h по мере роста времени t. Наиболее известным адаптивным методом является алгоритм Даркена-Муди:
, (4.9)
где T – постоянная времени, подбираемая для каждой задачи. При t<T h не изменяется, при t>T – уменьшается до нуля.

 и параметров
и параметров  формы базисных функций (часто используются алгоритмы обучения без учителя);
формы базисных функций (часто используются алгоритмы обучения без учителя); , соответствующих входным векторам
, соответствующих входным векторам  , для t=1,2,…,p.
, для t=1,2,…,p. - число нейронов скрытого слоя, t – номер итерации алгоритма. Тогда алгоритм К-усреднений можно описать следующим образом [6]:
- число нейронов скрытого слоя, t – номер итерации алгоритма. Тогда алгоритм К-усреднений можно описать следующим образом [6]: из усреднённых значений входных векторов, которые должны быть различны. При этом значения эвклидовой нормы по возможности должны быть небольшими.
из усреднённых значений входных векторов, которые должны быть различны. При этом значения эвклидовой нормы по возможности должны быть небольшими. , ближайший к
, ближайший к 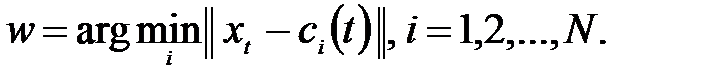
 (4.6)
(4.6) (4.7)
(4.7)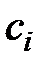 и его R ближайшими соседями. В этом случае значение
и его R ближайшими соседями. В этом случае значение  . (4.8)
. (4.8) , (4.9)
, (4.9)