где x – факторы (входные величины); b – неизвестные параметры (коэффициенты); h – реакция системы (выходная величина).
Целью анализа экспериментальных данных является определение оценок неизвестных параметров b в некоторой заданной области факторного пространства X. Рассмотрим статистическую модель (рис. 4.6).
Рис. 4.6. Модель системы
В реальных условиях, из-за наличия помехи e, вместо истинного значения выходной величины h экспериментатор измеряет величину . Следовательно, опираясь на результаты измерения, нельзя получить абсолютно точных значений b. Вместо истинных параметров b получают оценки параметров b. Тогда, оцениваемое уравнение для модели будет иметь вид:
Y=Y(x,b).
Чтобы правильно и точно оценить параметры модели, оценки должны быть: несмещенными, состоятельными, эффективными.
Оценки b являются несмещенными, если их математические ожидания равны истинным значениям параметров:
M[b]=b.
Это значит, что в процессе вычисления параметров модели не должны возникать статистические ошибки.
Оценка называется состоятельной, если при увеличении числа наблюдений n до бесконечности она сходится по вероятности к истинному значению параметра:
.
Достаточное условие для этого
.
Оценки будут эффективными, если они позволяют получить максимальную информацию из наблюдений. Часто бывает, что из исследуемого параметра можно найти несколько состоятельных оценок. Чтобы выбрать одну из них сравнивают дисперсии всех оценок и по минимуму дисперсии получают оценку, которая и будет эффективной
,
где D[b] - дисперсия оценки b, - дисперсия любых других несмещенных оценок b.
Существует несколько различных методов оценивания параметров:
- максимального правдоподобия;
- моментов;
- оценивание по Байесу;
- наименьших квадратов.
Метод максимального правдоподобия базируется на использовании априорной информации, полученной из эксперимента. При этом методе получают выборку значений случайной величины X(x1,x2,...,xn) и рассматривают оцениваемые параметры b как случайные величины с некоторым законом распределения вероятности. Затем это распределение перестраивается таким образом, чтобы получить апостериорное распределение вероятности, плотность которого несет информацию о возможных значениях b на основе экспериментальных данных X. Этот метод приводит к эффективным и состоятельным оценкам, однако оценки могут быть смещенными.
Метод моментов является одним из наиболее старых методов. При его использовании вычисляются первые n моментов случайной величины, которые затем приравниваются выборочным моментам. После этого находят n значений оцениваемых параметров b.
Оценивание по Байесу, как и метод максимального правдоподобия, основывается на использовании априорной информации. Определяется плотность распределения вероятностей случайных величин x, и на основе апостериорной информации принимается решение.
Метод наименьших квадратов (МНК) основывается на суммировании квадратов ошибок. Этот метод является самым распространенным методом при оценивании параметров модели.
При выборе методов обработки существенную роль играют три особенности машинного эксперимента с моделью системы S.
1. Возможность получать большие выборки позволяет количественно оценить характеристики процесса функционирования системы, но имеется серьезная проблема хранения промежуточных результатов моделирования. Эту проблему можно решить, используя рекуррентные алгоритмы обработки, когда оценки вычисляют по ходу моделирования.
2. Сложность исследуемой системы часто приводит к тому, что априорное суждение о характеристиках процесса функционирования системы, например о типе ожидаемого распределения выходных переменных, является невозможным. Поэтому при моделировании систем широко используются непараметрические оценки и оценки моментов распределения.
3. Блочность конструкции машинной модели Мм и раздельное исследование блоков связаны с программной имитацией входных переменных одной частичной модели по оценкам выходных переменных другой частичной модели. Если ЭВМ не позволяет воспользоваться переменными, записанными на внешние носители, то следует представить эти переменные в форме, удобной для построения алгоритма их имитации.
При исследовании сложных систем и большом числе реализаций N в результате моделирования получается значительный объем информации о состояниях процесса функционирования системы. Поэтому фиксацию и обработку результатов моделирования необходимо так организовать, чтобы оценки для искомых характеристик формировались постепенно по ходу моделирования, т. е. без специального запоминания всей информации о состояниях системы S.
Если при моделировании системы S учитываются случайные факторы, то и среди результатов моделирования присутствуют случайные величины. В этом случае в качестве оценок для искомых характеристик рассчитывают средние значения, дисперсии, корреляционные моменты и т. д.
Для оценки вероятных значений случайной величины, т. е. закона распределения, область возможных значений случайной величины h разбивается на п интервалов. Затем накапливается количество попаданий случайной величины в эти интервалы тk, к=1, п. Оценкой вероятности попадания случайной величины в интервал с номером k служит частота попадания в него – mk/N.
Для оценки среднего значения случайной величины накапливается сумма возможных значений случайной величины ( ), и среднее значение вычислдяется по формуле
.
При этом ввиду несмещенности и состоятельности оценки
;
.
В качестве оценки дисперсии случайной величины h можно использовать выражение
.
Более рационально оценивать дисперсию с помощью следующим образом:
.
При обработке результатов машинного эксперимента с наиболее часто возникают следующие задачи: определение эмпирического закона распределения случайной величины, проверка однородности распределений, сравнение средних значений и дисперсий переменных, полученных в результате моделирования, и т. д. Эти задачи с точки зрения математической статистики являются типовыми задачами по проверке статистических гипотез.
Задача определения эмпирического закона распределения случайной величины наиболее общая из перечисленных, но для правильного решения она требует большого числа реализаций N. В этом случае по результатам машинного эксперимента находят выборочный закон распределения Fэ(y) (либо плотность распределения fэ(y)) и выдвигают нулевую гипотезу Н0, что полученное распределение согласуется с каким-либо теоретическим распределением. Выбор вида теоретического распределения F(y) (или f(y)) проводится по графику зависимости выборочного закона распределения.
Далее эту гипотезу Н0 проверяют на состоятельность с помощью статистических критериев согласия: Колмогорова, Пирсона, Смирнова и т. д.. При этом необходимую статистическую обработку результатов по возможности ведут в процессе моделирования системы. Если вероятность расхождения теоретического и эмпирического распределений Р { UT≥ U} согласно выбранному критерию согласия не велика, то проверяемая гипотеза о виде распределения Н0 принимается.
Критерий согласия Колмогорова основан на выборе в качестве меры расхождения U величины .
Из теоремы Колмогорова следует, что при отклонение закона распределения имеет функцию распределения
,
где – значение случайной величины.
Если вычисленное на основе экспериментальных данных значение меньше, чем его табличное значение, то гипотезу H0 принимают, в противном случае гипотеза Н0 отвергается.
Критерий Колмогорова целесообразно применять для обработки результатов моделирования в тех случаях, когда известны все параметры теоретической функции распределения. Недостаток использования этого критерия связан с необходимостью фиксации в памяти ЭВМ всей информации.
Критерий согласия Пирсона основан на определении в качестве меры расхождения экспериментального и теоретического законов распределениявеличины
,
где тi— количество значений случайной величины h, попавших в i-й подынтервал; pi — вероятность попадания случайной величины h в i-й подынтервал, вычисленная из теоретического распределения; d — количество подынтервалов, на которые разбивается интервал измерения в машинном эксперименте.
При закон распределения расхождения зависит только от числа подынтервалов и приближается к закону распределения (хи-квадрат) с (d-r-1) степенями свободы, где r — число параметров теоретического закона распределения.
Из теоремы Пирсона следует, что, какова бы ни была функция распределения F(y) случайной величины h, при распределение величины имеет вид
.
где Г(k/2) — гамма-функция; z — значение случайной величины , k = d-r-1 — число степеней свободы. Функция распределения Fk(z) табулирована.
По вычисленному значению U= и числу степеней свободы k с помощью таблиц находится вероятность . Если эта вероятность превышает некоторый уровень значимости , то считается, что гипотеза Н0о виде распределения не опровергается результатами машинного эксперимента.
Хотя рассмотренные оценки искомых характеристик процесса функционирования системы S являются простейшими, они охватывают большинство случаев, встречающихся в практике обработки результатов моделирования системы.
Метод наименьших квадратов
Рассмотрим применение метода наименьших квадратов на примере линейной модели с одной независимой величиной.
Уравнение модели с одной независимой величиной имеет вид:
(4.4)
Оценкой уравнения (4.4) будет:
(4.5)
Зависимость (4.4) представляет собой уравнение теоретической линии регрессии, а (4.5) – эмпирической линию регрессии (рис.4.7). Коэффициенты b0 и b1 являются оценками истинных коэффициентов b0 и b1.
Рис. 4.7. Линия регрессии:
а – теоретическая линия регрессии; б – эмпирическая линия регрессии
На рис. 4.7 обозначены точки – одно измерение; – выборочное среднее наблюдение при xi; – предсказанное значение выходной величины yi при xi; – истинное значение выходной величины hi при xi.
Для несмещенных оценок , т.е. hi есть математическое ожидание при . Коэффициенты b0 и b1 находятся по экспериментальным данным следующим образом. Если бы все экспериментальные точки оказались на теоретической линии регрессии, то отклонение между прогнозируемым и теоретическим значением было равно нулю:
или
, i=1,2,...n , (4.6)
и тогда коэффициенты b0 и b1 могли быть определены решением системы уравнений (4.6).
Однако, в реальных условиях левая часть (4.6) отличается от нуля на величину ei
(4.7)
Величина ei называется невязкой. Она может быть вызвана ошибкой эксперимента или неправильным выбором линейной модели. Поэтому возникает задача найти такие коэффициенты уравнения регрессии, при которых невязка будет минимальной. Лучшей оценкой минимума ошибки является выражение
.
Это выражение приводит к методу наименьших квадратов:
, (4.8)
где – число повторных измерений величины y при данном значении xi.
Минимум функции Ф достигается при одновременном равенстве нулю частных производных этой функции по всем искомым коэффициентам:
(4.9)
где – среднее значение при данном значении .
После замены b0 и b1 их оценками b0 и b1 получаем систему нормальных уравнений:
или
(4.10)
Решая систему нормальных уравнений относительно b0 и b1 получаем:
, (4.20)
. (4.21)
Аналогичную методику можно применить для оценки динамических характеристик.

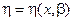 ,
,
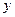 . Следовательно, опираясь на результаты измерения, нельзя получить абсолютно точных значений b. Вместо истинных параметров b получают оценки параметров b. Тогда, оцениваемое уравнение для модели будет иметь вид:
. Следовательно, опираясь на результаты измерения, нельзя получить абсолютно точных значений b. Вместо истинных параметров b получают оценки параметров b. Тогда, оцениваемое уравнение для модели будет иметь вид: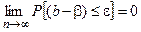 .
.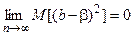 .
.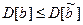 ,
,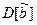 - дисперсия любых других несмещенных оценок b.
- дисперсия любых других несмещенных оценок b.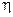 накапливается сумма возможных значений случайной величины
накапливается сумма возможных значений случайной величины 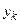 (
( 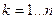 ), и среднее значение вычислдяется по формуле
), и среднее значение вычислдяется по формуле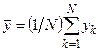 .
.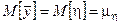 ;
;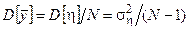 .
.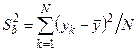 .
.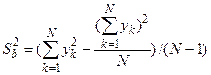 .
.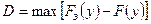 .
. отклонение закона распределения
отклонение закона распределения 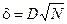 имеет функцию распределения
имеет функцию распределения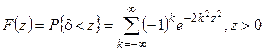 ,
,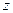 – значение случайной величины.
– значение случайной величины.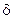 меньше, чем его табличное значение, то гипотезу H0 принимают, в противном случае гипотеза Н0 отвергается.
меньше, чем его табличное значение, то гипотезу H0 принимают, в противном случае гипотеза Н0 отвергается.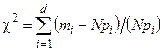 ,
,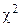 (хи-квадрат) с (d-r-1) степенями свободы, где r — число параметров теоретического закона распределения.
(хи-квадрат) с (d-r-1) степенями свободы, где r — число параметров теоретического закона распределения.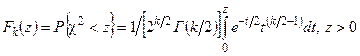 .
.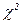 и числу степеней свободы k с помощью таблиц находится вероятность
и числу степеней свободы k с помощью таблиц находится вероятность 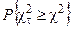 . Если эта вероятность превышает некоторый уровень значимости
. Если эта вероятность превышает некоторый уровень значимости 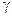 , то считается, что гипотеза Н0 о виде распределения не опровергается результатами машинного эксперимента.
, то считается, что гипотеза Н0 о виде распределения не опровергается результатами машинного эксперимента.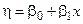 (4.4)
(4.4)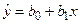 (4.5)
(4.5)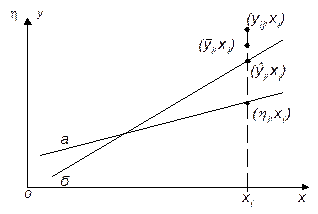
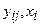 – одно измерение;
– одно измерение; 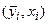 – выборочное среднее наблюдение при xi;
– выборочное среднее наблюдение при xi; 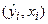 – предсказанное значение выходной величины yi при xi;
– предсказанное значение выходной величины yi при xi; 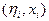 – истинное значение выходной величины hi при xi.
– истинное значение выходной величины hi при xi.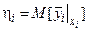 , т.е. hi есть математическое ожидание
, т.е. hi есть математическое ожидание 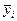 при
при 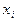 . Коэффициенты b0 и b1 находятся по экспериментальным данным следующим образом. Если бы все экспериментальные точки оказались на теоретической линии регрессии, то отклонение между прогнозируемым и теоретическим значением было равно нулю:
. Коэффициенты b0 и b1 находятся по экспериментальным данным следующим образом. Если бы все экспериментальные точки оказались на теоретической линии регрессии, то отклонение между прогнозируемым и теоретическим значением было равно нулю: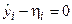 или
или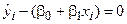 , i=1,2,...n , (4.6)
, i=1,2,...n , (4.6)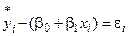 (4.7)
(4.7)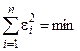 .
.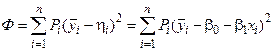 , (4.8)
, (4.8)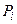 – число повторных измерений величины y при данном значении xi.
– число повторных измерений величины y при данном значении xi.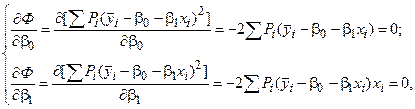 (4.9)
(4.9)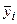 – среднее значение при данном значении
– среднее значение при данном значении 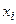 .
.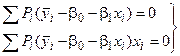
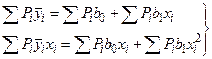 (4.10)
(4.10)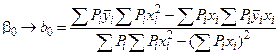 , (4.20)
, (4.20)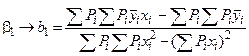 . (4.21)
. (4.21)