1. Знакомство с методами определения функции, соответствующей некоторым данным (аппроксимация данных).
2. Разработка численной ММ, аппроксимирующей данные методом наименьших квадратов.
3. Решение задачи аппроксимации при помощи средств MATLAB.
Если информации о моделируемом объекте (процессе) недостаточно или он настолько сложен (имеет случайный характер), что невозможно составить его детерминированную модель, используют стохастические модели и соответствующие экспериментально-статистические методы.
На практике весьма распространенной является задача определения функции (аналитической зависимости), которая должна соответствовать некоторым данным, полученным, например, при проведении экспериментальных исследований. При этом можно выделить два направления приближения функции – процесс интерполяции, определяющий вид функции, совпадающей с табличными данными, а также процесс аппроксимации, направленный на восстановление функциональной зависимости по данным эксперимента, возможно содержащего ошибки. Аппроксимация при этом должна обеспечивать оптимальное расположение линии (поверхности для многофакторного эксперимента) функции среди множества экспериментальных точек, не обязательно совпадающей с ними.
Простейшим случаем интерполяции является определение вида функции f(x) одной переменной, проходящей через заданные точки (xi, yi), т.е. f(xi)=yi , i=1,…,N (рис. 1а).
y y
xx
а) б)
Рис. 1. Виды аппроксимации
Говорят, что функция f интерполирует данные, и в этом случае она называется интерполянтом или интерполирующей функцией. Как видно из графика, в зависимости от способа интерполяции можно получить различные интерполянты. Отсюда следует:
1) данные (xi, yi) сами по себе не могут определить интерполянт, и для фиксированного набора данных существует бесконечное множество интерполянтов;
2) интерполяция может быть полезна только в том случае, если данные не содержат ошибок, если же, например yi содержит погрешности, данные необходимо аппроксимировать как-то по-другому;
Наиболее употребительным способом аппроксимации данных, содержащих ошибки, является метод наименьших квадратов. Он позволяет определить вид функции с минимальной суммой квадратов отклонений ее значений от экспериментальных. На рис. 1б отражен вариант такой функции при одномерной линейной аппроксимации.
В общем случае задача аппроксимации данных решается для нелинейной функции многих переменных.
Так как в реальном процессе всегда существуют неуправляемые и неконтролируемые переменные, результат эксперимента есть случайная величина. Пусть, например, требуется исследовать зависимость y(x1, x2,…xm), причем величины y и Х={x1, x2,…xm} измеряются в одних и тех же экспериментах. Будем считать, что погрешность измерения величин xj пренебрежимо мала по сравнению с погрешностью измерения величины y, т.е. величины xj измеряются точно, в то время как измерение величины y содержит случайные погрешности. Таким образом, результаты эксперимента можно рассматривать как выборочные значения случайной величины h(X), зависящей от X , как от параметра.
Регрессией называют зависимость условного математического ожидания величины h(X) от переменной X , т.е. . Задача регрессионного анализа состоит в этом случае в восстановлении функциональной зависимости по результатам измерений (Xi, yi), i=1,2,…, N. Аппроксимируем неизвестную зависимость при помощи заданной функции уравнения регрессии . Это значит, что результаты измерений можно представить в виде , где – неизвестные параметры регрессии, zi – случайные величины, характеризующие погрешности эксперимента. С учетом разложения исследуемой зависимости в ряд Тейлора в окрестности X0 и использования выборочных коэффициентов , как оценок теоретических (b0=f(X0), b1=¶ f(X0)/¶ x1,…) уравнение регрессии можно записать в следующем общем виде [7]
, (1)
где b0 – свободный член уравнения регрессии; bj – линейные эффекты; bjj – квадратичные эффекты; bjk – эффекты взаимодействия.
Коэффициенты уравнения (1) определяются методом наименьших квадратов
, (2)
где N – объем выборки.
Необходимым условием минимума является равенство нулю соответствующих частных производных , … Тогда после преобразования получим
(3)
Система (3) содержит столько же уравнений, сколько неизвестных коэффициентов входит в уравнение регрессии и называется в математической статистике системой нормальных уравнений. Для решения системы (3) необходимо задать конкретный вид функции .
Линейная регрессия одного параметра. Определим по методу наименьших квадратов коэффициенты линейного уравнения . Тогда с учетом и для системы (3) можно записать
или (4)
Решая данную систему относительно и , получим при помощи определителей следующие выражения
, .
Коэффициент проще найти по известному из первого уравнения системы (4) , где – средние значения x и y ( ).
Для оценки силы линейной связи вычисляется выборочный коэффициент корреляции r*
Чем ближе r* к единице, тем выше линейность зависимости между x и y.
Параболическая регрессия одного параметра определяется коэффициентами параболического уравнения . Тогда для параболы второго порядка система нормальных уравнений (3) имеет вид
Аналогично могут быть определены коэффициенты для параболы любого порядка.
Трансцендентная регрессия одного параметра определяется коэффициентами уравнений показательного , дробно-степенного типа и др. Обычно трансцендентную регрессию используют, чтобы уменьшить число неопределенных коэффициентов, т.к. при малых объемах выборки N увеличение порядка полинома может привести к росту остаточной дисперсии. Вычисление коэффициентов трансцендентной регрессии может оказаться весьма трудоемким вследствие необходимости решать систему нелинейных уравнений. Вычисления можно упростить, если провести замену переменных и линеаризовать приведенные выше зависимости путем логарифмирования:
Пусть и
Пусть и
Коэффициенты или определяются методом наименьших квадратов, значения которых используются для нахождения .
Для оценки силы (тесноты) нелинейной связи (проведения корреляционного анализа) вычисляется корреляционное отношение:
,
где f1=N–1, f2=N–l – числа степеней свободы; l – число связей, наложенных на выборку (для уравнения регрессии это число определяемых коэффициентов ); – остаточная дисперсия; – дисперсия относительно среднего.
Чем больше q, тем сильнее связь (0£q£1). При q=0 однозначное отсутствие связи между случайными величинами возможно только для нормального распределения. В случае линейной регрессии (l=2) корреляционное отношение равно коэффициенту корреляции q=|r* |.
Множественная регрессия предполагает определение коэффициентов (исследование корреляционной связи) для многофакторного уравнения. Например, для линейного случая уравнение множественной регрессии имеет вид . Здесь, следовательно, требуется определить не линию регрессии, а поверхность (m=2), или гиперповерхность (m>2).
Статистический анализ результатов (регрессионный анализ) проводится после определения уравнения регрессии и включает: оценку адекватности уравнения; проверку значимости всех коэффициентов в сравнении с ошибкой воспроизводимости; расчет доверительных интервалов для параметров модели и выходной переменной .
При отсутствии параллельных опытов и, следовательно, дисперсии воспроизводимости, а также нормальном распределении случайных величин yi качество аппроксимации (адекватность) можно оценить по критерию Фишера [1]. В данном случае он показывает, во сколько раз уменьшается рассеяние относительно полученного уравнения регрессии по сравнению с рассеянием относительно среднего. Чем больше значение F превышает табличное (или f – распределение в табл. 1) для выбранного уровня вероятности (значимости, надежности) p (обычно p=0.95) и чисел , тем эффективнее уравнение регрессии.
При одинаковом числе параллельных опытов (каждый i-й опыт с объемом выборки N ( ) проводится U раз ) выборочные дисперсии должны быть однородны. Последнее выполняется если справедливо условие Gmax<GpТАБ(N,U-1), где GpТАБ(N,U-1) – табличное значение критерия Кохнера при уровне значимости p; ; – максимальное значение выборочной дисперсии. Для однородных выборочных дисперсий рассчитываются дисперсия воспроизводимости и дисперсия адекватности , которые необходимы для определения критерия Фишера . Если расчетное значение меньше табличного , то уравнение адекватно.
Таблица 1
Степень свободы
--
161,4
199,5
215.7
224,6
230,2
234,0
238,9
243,9
249,0
254,3
18,51
19,00
19,16
19,25
19,30
19,33
19,37
19,41
19,46
19,50
10,13
9,55
9,28
9,12
9,01
8,94
8,84
8,74
8,64
8,53
7,71
6,94
6,59
6,39
6,26
6,16
6,04
5,91
5,77
5,63
6,61
5,79
5,41
5,19
5,05
4,95
4,82
4,68
4,53
4,36
5,99
5,14
4,76
4,53
4,39
4,28
4,15
4,00
3,84
3,67
5,59
4,74
4,35
4,12
3,97
3,87
3,73
3,57
3,41
3,23
5,32
4,46
4,07
3,84
3,69
3,58
3,44
3,28
3,12
2,93
5,12
4,26
3,86
3,63
3,48
3,37
3,23
3,07
2,90
2,71
4,96
4,10
3,71
3,48
3,33
3,22
3,07
2,91
2,74
2,540
4,84
3,98
3,59
3,36
3,20
3,09
2,95
2,79
2,61
2,40
4,75
3,88
3,49
3,26
3,11
3,00
2,85
2,69
2,50
2,30
4,67
3,80
3,41
3,18
3,02
2,92
2,77
2,60
2,42
2,21
4,60
3,74
3,34
3,11
2,96
2,85
2,70
2,53
2,35
2,13
4,54
3,68
3,29
3,06
2,90
2,79
2,64
2,48
2,29
2,07
Оценка значимости коэффициентов уравнения регрессии проводится по критерию Стьюдента , где – h-й коэффициент уравнения; – среднее квадратичное отклонение h-го коэффициента. Если больше табличного для выбранного уровня значимости p и степени свободы f=N(U–1), то коэффициент значимо отличается от нуля. Незначимые коэффициенты из уравнения исключаются с последующим пересчетом оставшихся.
Для уравнения регрессии
, .
Определив и табличные значения величины ta корня уравнения FN-2( )=1–0.5a функции распределения Стьюдента (t – распределение) с N-2 степенями свободы можно найти доверительные интервалы параметров модели и доверительный коридор выходной переменной . Для уравнения регрессии получим [1] для параметров и
,
,
где b0, b1 – половина ширины доверительного интервала для и ;
для определения концов доверительных интервалов (доверительной полосы или коридора) выходной переменной при каждом конкретном значении (доказано, что доверительный интервал накрывает истинное значение с вероятностью 1–a)
;
для определения доверительной области всей линии регрессии соответственно нижней (left) и верхней (right) границ полосы
,
где – корень уравнения F2,N-2( )=1-a; F2,N-2(x) – функция распределения Фишера (F – распределение) с 2 и N-2 степенями свободы.
Использование модели за пределами исследуемого диапазона не обосновано. Примеры аппроксимации данных средствами MATLAB приведены в прил. 5.

 y y
y y









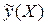 условного математического ожидания величины h(X) от переменной X , т.е.
условного математического ожидания величины h(X) от переменной X , т.е. 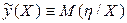 . Задача регрессионного анализа состоит в этом случае в восстановлении функциональной зависимости
. Задача регрессионного анализа состоит в этом случае в восстановлении функциональной зависимости 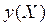 по результатам измерений (Xi, yi), i=1,2,…, N. Аппроксимируем неизвестную зависимость
по результатам измерений (Xi, yi), i=1,2,…, N. Аппроксимируем неизвестную зависимость 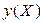 при помощи заданной функции уравнения регрессии
при помощи заданной функции уравнения регрессии 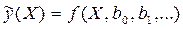 . Это значит, что результаты измерений можно представить в виде
. Это значит, что результаты измерений можно представить в виде 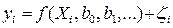 , где
, где 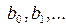 – неизвестные параметры регрессии, zi – случайные величины, характеризующие погрешности эксперимента. С учетом разложения исследуемой зависимости в ряд Тейлора в окрестности X0 и использования выборочных коэффициентов
– неизвестные параметры регрессии, zi – случайные величины, характеризующие погрешности эксперимента. С учетом разложения исследуемой зависимости в ряд Тейлора в окрестности X0 и использования выборочных коэффициентов 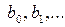 , как оценок теоретических (b0=f(X0), b1=¶ f(X0)/¶ x1,…) уравнение регрессии можно записать в следующем общем виде [7]
, как оценок теоретических (b0=f(X0), b1=¶ f(X0)/¶ x1,…) уравнение регрессии можно записать в следующем общем виде [7]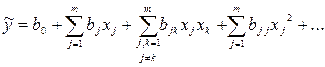 , (1)
, (1)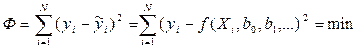 , (2)
, (2)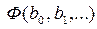 является равенство нулю соответствующих частных производных
является равенство нулю соответствующих частных производных 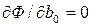 ,
, 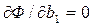 … Тогда после преобразования получим
… Тогда после преобразования получим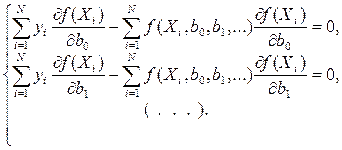 (3)
(3)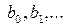 входит в уравнение регрессии и называется в математической статистике системой нормальных уравнений. Для решения системы (3) необходимо задать конкретный вид функции
входит в уравнение регрессии и называется в математической статистике системой нормальных уравнений. Для решения системы (3) необходимо задать конкретный вид функции 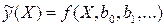 .
.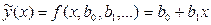 . Тогда с учетом
. Тогда с учетом 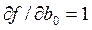 и
и 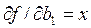 для системы (3) можно записать
для системы (3) можно записать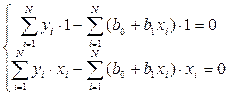 или
или  (4)
(4)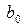 и
и 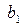 , получим при помощи определителей следующие выражения
, получим при помощи определителей следующие выражения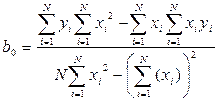 ,
, 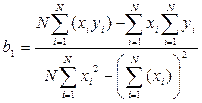 .
.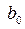 проще найти по известному
проще найти по известному 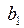 из первого уравнения системы (4)
из первого уравнения системы (4) 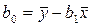 , где
, где 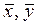 – средние значения x и y (
– средние значения x и y ( 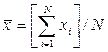 ).
).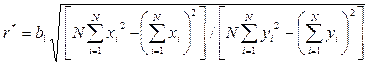
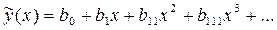 . Тогда для параболы второго порядка
. Тогда для параболы второго порядка 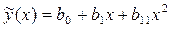 система нормальных уравнений (3) имеет вид
система нормальных уравнений (3) имеет вид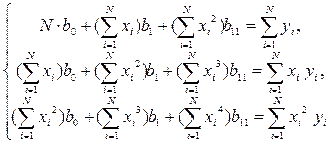
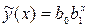 , дробно-степенного типа
, дробно-степенного типа 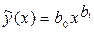 и др. Обычно трансцендентную регрессию используют, чтобы уменьшить число неопределенных коэффициентов, т.к. при малых объемах выборки N увеличение порядка полинома может привести к росту остаточной дисперсии. Вычисление коэффициентов трансцендентной регрессии может оказаться весьма трудоемким вследствие необходимости решать систему нелинейных уравнений. Вычисления можно упростить, если провести замену переменных и линеаризовать приведенные выше зависимости путем логарифмирования:
и др. Обычно трансцендентную регрессию используют, чтобы уменьшить число неопределенных коэффициентов, т.к. при малых объемах выборки N увеличение порядка полинома может привести к росту остаточной дисперсии. Вычисление коэффициентов трансцендентной регрессии может оказаться весьма трудоемким вследствие необходимости решать систему нелинейных уравнений. Вычисления можно упростить, если провести замену переменных и линеаризовать приведенные выше зависимости путем логарифмирования: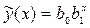
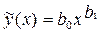
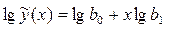
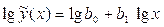
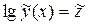 и
и 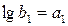
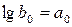 и
и 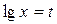
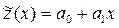
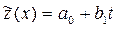
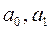 или
или 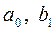 определяются методом наименьших квадратов, значения которых используются для нахождения
определяются методом наименьших квадратов, значения которых используются для нахождения 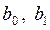 .
.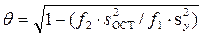 ,
,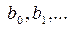 );
); 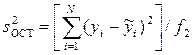 – остаточная дисперсия;
– остаточная дисперсия; 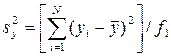 – дисперсия относительно среднего.
– дисперсия относительно среднего.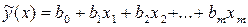 . Здесь, следовательно, требуется определить не линию регрессии, а поверхность (m=2), или гиперповерхность (m>2).
. Здесь, следовательно, требуется определить не линию регрессии, а поверхность (m=2), или гиперповерхность (m>2).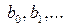 и выходной переменной
и выходной переменной 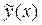 .
.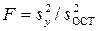 [1]. В данном случае он показывает, во сколько раз уменьшается рассеяние относительно полученного уравнения регрессии по сравнению с рассеянием относительно среднего. Чем больше значение F превышает табличное
[1]. В данном случае он показывает, во сколько раз уменьшается рассеяние относительно полученного уравнения регрессии по сравнению с рассеянием относительно среднего. Чем больше значение F превышает табличное 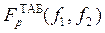 (или f – распределение в табл. 1) для выбранного уровня вероятности (значимости, надежности) p (обычно p=0.95) и чисел
(или f – распределение в табл. 1) для выбранного уровня вероятности (значимости, надежности) p (обычно p=0.95) и чисел 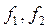 , тем эффективнее уравнение регрессии.
, тем эффективнее уравнение регрессии.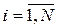 ) проводится U раз
) проводится U раз 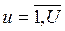 ) выборочные дисперсии
) выборочные дисперсии 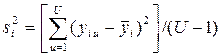 должны быть однородны. Последнее выполняется если справедливо условие Gmax<GpТАБ(N,U-1), где GpТАБ(N,U-1) – табличное значение критерия Кохнера при уровне значимости p;
должны быть однородны. Последнее выполняется если справедливо условие Gmax<GpТАБ(N,U-1), где GpТАБ(N,U-1) – табличное значение критерия Кохнера при уровне значимости p; 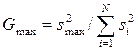 ;
; 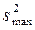 – максимальное значение выборочной дисперсии. Для однородных выборочных дисперсий рассчитываются дисперсия воспроизводимости
– максимальное значение выборочной дисперсии. Для однородных выборочных дисперсий рассчитываются дисперсия воспроизводимости 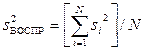 и дисперсия адекватности
и дисперсия адекватности 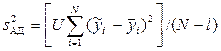 , которые необходимы для определения критерия Фишера
, которые необходимы для определения критерия Фишера 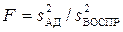 . Если расчетное значение меньше табличного
. Если расчетное значение меньше табличного 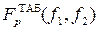 , то уравнение адекватно.
, то уравнение адекватно.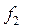
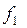
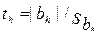 , где
, где 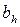 – h-й коэффициент уравнения;
– h-й коэффициент уравнения; 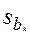 – среднее квадратичное отклонение h-го коэффициента. Если
– среднее квадратичное отклонение h-го коэффициента. Если 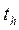 больше табличного
больше табличного 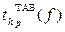 для выбранного уровня значимости p и степени свободы f=N(U–1), то коэффициент
для выбранного уровня значимости p и степени свободы f=N(U–1), то коэффициент 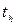 значимо отличается от нуля. Незначимые коэффициенты из уравнения исключаются с последующим пересчетом оставшихся.
значимо отличается от нуля. Незначимые коэффициенты из уравнения исключаются с последующим пересчетом оставшихся.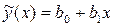
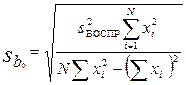 ,
, 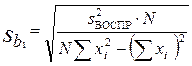 .
.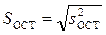 и табличные значения величины ta корня уравнения FN-2(
и табличные значения величины ta корня уравнения FN-2( 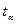 )=1–0.5a функции распределения Стьюдента (t – распределение) с N-2 степенями свободы можно найти доверительные интервалы параметров модели
)=1–0.5a функции распределения Стьюдента (t – распределение) с N-2 степенями свободы можно найти доверительные интервалы параметров модели 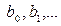 и доверительный коридор выходной переменной
и доверительный коридор выходной переменной 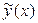 . Для уравнения регрессии
. Для уравнения регрессии 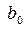 и
и 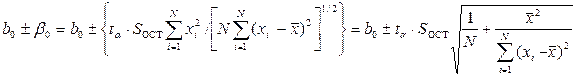 ,
,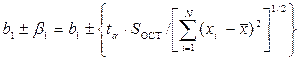 ,
,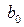 и
и 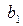 ;
;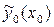 при каждом конкретном значении
при каждом конкретном значении 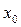 (доказано, что доверительный интервал накрывает истинное значение
(доказано, что доверительный интервал накрывает истинное значение 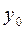 с вероятностью 1–a)
с вероятностью 1–a)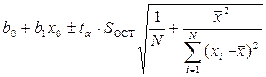 ;
;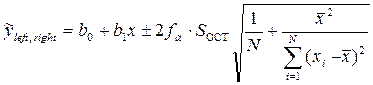 ,
,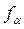 – корень уравнения F2,N-2(
– корень уравнения F2,N-2( 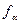 )=1-a; F2,N-2(x) – функция распределения Фишера (F – распределение) с 2 и N-2 степенями свободы.
)=1-a; F2,N-2(x) – функция распределения Фишера (F – распределение) с 2 и N-2 степенями свободы.