где Pt — вероятность того, что система находится в i-u состоянии.
Энтропия равна нулю только в одном случае, когда все вероятности Рiравны нулю, кроме одной, которая равна единице. Это точно описывает отсутствие неопределенности: система находится всегда в одном и том же состоянии.
Энтропия максимальна, когда все вероятности равны.
Если вес исходы равновероятны, т.е. Pi = 1/к, то согласно формуле Шеннона Н(a) = log к
Например, энтропия нашего алфавита из 32 букв: Н = log32 = 5 бит. Энтропия десятичного набора цифр Н = log 10 =3,32 бита. Энтропия системы, в которой отдельно храниться 32 буквы и 10 цифр Н =log (32 х 10)= 5 + 3,32 = 8,32 бита.
Вооружившись таким основательным понятием, как количество информации, рассмотрим его с позиций семиотики.
В качестве синтаксической меры количество информации представляет объем данных.
Объем данных Vdв сообщении «в» измеряется количестве символов (разрядов) в этом сообщении. Как мы упоминали, в двоичной системе счисления единица измерения — бит. На практике наряду с этой «самой мелкой» единицей измерения данных чаще применяется более крупная единица — байт, равная 8 бит. Для удобства в качестве измерителей используются кило- (103), мега- (106), гига- (109) и тера- (1012) байты и т.д. В знакомых всем байтах измеряется объем кратких письменных сообщений, толстых книг, музыкальных произведений, изображений, а также программных продуктов. Понятно, что эта мера никак не может характеризовать того, что и зачем несут эти единицы информации. Измерять в килобайтах роман Л.Н. Толстого «Война и мир» полезно, например, чтобы понять, сможет ли он разместиться на свободном месте твердого диска. Это столь же полезно, как измерять размер книги — ее высоту, толщину и ширину, чтобы оценить, поместится ли она на книжной полке, или взвешивать ее на предмет того, выдержит ли портфель совокупную тяжесть
Итак. одной синтаксической меры информации явно недостаточно для характеристики сообщения: в нашем примере с погодой в последнем случае сообщение приятеля содержало ненулевой объем данных, но в нем не было нужной нам информации. Заключение о полезности информации следует из рассмотрения содержания сообщения. Для измерения смыслового содержания информации, т.е. ее количества на семантическом уровне, введем понятие «тезаурус получателя информации».
Тезаурус — это совокупность сведений и связей между ними, которыми располагает получатель информации.Можно сказать, что тезаурус — это накопленные знания получателя.
В очень простом случае, когда получателем является техническое устройство — персональный компьютер, тезаурус формируется «вооружением» компьютера — заложенными в него программами и устройствами, позволяющими принимать, обрабатывать и представлять текстовые сообщения на разных языках, использующих разные алфавиты, шрифты, а также аудио- и видеоинформацию из локальной или всемирной сети. Если компьютер не снабжен сетевой картой, нельзя ожидать получения на него сообщений от других пользователей сети ни в каком виде. Отсутствие драйверов с русскими шрифтами не позволит работать с сообщениями на русском языке и т.д.
Если получателем является человек, его тезаурус — это тоже своеобразное интеллектуальное вооружение человека, арсенал его знаний. Он также образует своеобразный фильтр для поступающих сообщений. Поступившее сообщение обрабатывается с использованием имеющихся знаний с целью получения информации. Если тезаурус очень богат, то арсенал знаний глубок и многообразен, он позволит извлекать информацию из практически любого сообщения. Маленький тезаурус, содержащий скудный багаж знаний, может стать препятствием для понимания сообщений, требующих лучшей подготовки.
Заметим, однако, что одного понимания сообщения для влияния на принятие решения мало — надо, чтобы в нем содержалась нужная для этого информация, которой нет в нашем тезаурусе и которую мы в него хотим включить. В случае с погодой в нашем тезаурусе не было последней, «актуальной» информации о погоде в районе университета. Если полученное сообщение изменяет наш тезаурус, может измениться и выбор решения. Такое изменение тезауруса и служит семантической мерой количества информации своеобразной мерой полезности полученного сообщения.
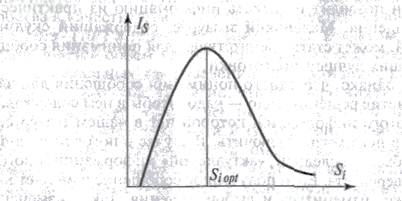
Формально количество семантической информации Is, включаемой в дальнейшем в тезаурус, определяется соотношением тезауруса получателя Si , и содержания передаваемой в сообщении «в» информации S. Графический вид этой зависимости показан на рис.1.
Рассмотрим случаи, когда количество семантической информации Isравно или близко к нулю:
• при Si = 0 получатель не воспринимает поступающую информацию;
• при 0 < Si< S0 получатель воспринимает, но не понимает поступившую в сообщении информацию;
•при Si—» ∞получатель имеет исчерпывающие знания и поступающая информация не может пополнить его тезауруса.
Рис. Зависимость количества семантической информации от тезаурса получателя
При тезаурусе Si > S0 количество семантической информации Is, получаемое из вложенной сообщение β информации S вначале быстро растет с ростом собственного тезауруса получателя, а затем — начиная с некоторого значения Si — падает. Падение количества полезной для получателя информации происходит оттого, что багаж знаний получателя стал достаточно солидным и удивить его чем-то новым становится все труднее.
Это можно проиллюстрировать на примере студентов, изучающих экономическую информатику и читающих материалы сайтов по корпоративным ИС. Вначале при формировании первых знаний об информационных системах чтение мало что дает — много непонятных терминов, аббревиатур, даже заголовки не все понятны. Настойчивость в чтении книг, посещение лекций и семинаров, общение с профессионалами помогают пополнить тезаурус. Со временем чтение материалов сайта становится приятным и полезным, а к концу профессиональной карьеры — после написания многих статей и книг — получение новых полезных сведений с популярного сайта будет случаться намного реже.
Можно говорить об оптимальном для данной информации S тезаурусе получателя, при котором им будет получена максимальная информация Is, а также об оптимальной информации в сообщении «в» для данного тезауруса Sj. В нашем примере, когда получателем является компьютер, оптимальный тезаурус означает, что его аппаратная часть и установленное программное обеспечение воспринимают и правильно интерпретируют для пользователя все содержащиеся в сообщении «в» символы, передающие смысл информации S. Если в сообщении есть знаки, которые не соответствуют содержимому тезауруса, часть информации будет утрачена и величина Isуменьшится.
С другой стороны, если мы знаем, что получатель не имеет возможности получать тексты на русском (его компьютер не имеет нужных драйверов), а иностранных языков, на которых наше сообщение может быть послано, ни он, ни мы не изучали, для передачи необходимой информации мы можем прибегнуть к транслитерации — написанию русских текстов с использованием букв иностранного алфавита, хорошо воспринимаемого компьютером получателя. Так мы приведем в соответствие нашу информацию с имеющимся в распоряжении получателя тезаурусом компьютера. Сообщение будет выглядеть некрасиво, но всю необходимую информацию получателю удастся прочитать.
Таким образом, максимальное количество семантической информации Is из сообщения β получатель приобретает при согласовании ее смыслового содержания S c тезаурусом Si, (при Si = Sjopt). Информация из одного и того же сообщения может иметь смысловое содержание для компетентного пользователя и быть бессмысленной для пользователя некомпетентного. Количество семантической информации в сообщении, получаемом пользователем, является величиной индивидуальной, персонифицированной — в отличие от синтаксической информации. Однако измеряется семантическая информация так же, как синтаксическая, — в битах и байтах.
Относительной мерой количества семантической информации служит коэффициент содержательности С, который определяется как отношение количества семантической информации к ее объему данных Vd, содержащихся в сообщении β: