От того, каким образом физически хранится информация на диске в большой степени зависит скорость работы с БД. Физически база хранится как набор и записей, каждая из которых состоит из одного или более полей. В реляционной базе данных каждая запись соответствует кортежу отношений, а поля – атрибутам.
Сотрудник(Табельный номер, номер отдела, имя)
Record
Num:integer;
DepNum:integer;
name:string[20];
end;
Часто при обсуждении физического хранения БД используется термин «Файл». В данном случае под файлом понимают набор записей одинакового формата. Под форматом записей понимают упорядоченный список полей с указанием их типов. Физически БД может хранить отношения в отдельных файлах (dbase), несколько баз данных в одном файле (mysql).
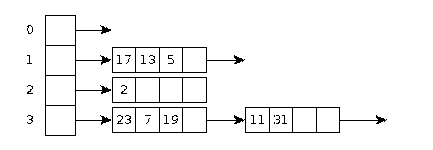
Организация хранения записей на диске.
Запись содержит, как минимум столько байтов, сколько требуется для хранения всех ее полей. Кроме того, запись может включать дополнительные байты, это необходимо в следующих случаях:
- некоторые байты могут свидетельствовать о формате записи, если совместно хранятся записи различных форматов;
- один или несколько байтов могут хранить информацию о длине байтов. Это необходимо, если записи могут иметь переменную длину;
- может быть специальный идентификатор, помечающий является ли запись удаленной или нет. В некоторых СУБД записи физически не удаляются сразу, а помечаются удаленными (механизм теневых страниц). Такие записи продолжаются храниться, но не рассматриваются при построении запросов. В этом случае СУБД должна иметь механизм сборки мусора и перераспределения памяти;
- бит использования – хранит информацию о наличии свободного места. Фактически говорит, что место под текущую запись свободно, служит для оптимизации распределения памяти. При добавлении записи в физический файл к нему может добавиться фрагмент больше, чем запись, то есть блок, соответственно этот бит отмечает, где начинается свободное место;
- неиспользованное пространство. Служит для ускорения доступа к записям, реализует, например, постраничное выравнивание записей.
Примеры: рассмотрим вышеприведенную запись:
1 2-5 6-9 10-29 30-32
Into num depNum name неисп. байты
Наиболее быстрая обработка данных возможна, если размещать базу данных целиком в оперативной памяти, однако, обычно размеры БД гораздо больше, поэтому возникает необходимость переноса фрагментов данных с диска в оперативную память, такие фрагменты называются блоками или страницами (могут отличаться от файловой системы диска). Соответственно блок может хранить некоторое множество записей. Обычно запись меньше, чем блок. Кроме записей блок хранит указатель на следующий блок, флаг блокировки и вспомогательные данные. Постраничная блокировка используется для оптимизации. СУБД редко использует блокировку каждой записи при выполнении транзакций. Всего возможны 4 стратегии блокировки в зависимости от объема блокировки: база данных, таблица, страница или блок, запись.
Блок, также как и запись , может иметь неиспользуемое пространство. Кроме того, может храниться специальный нулевой блок, содержащий служебную информацию. Например, в случае хранения в блоках записей одного формата он может хранить схемы отношений типа полей.
Скорость доступа к данным определяется количеством блоков, которые необходимо считать с диска, чтобы найти нужную запись. Операции ввода-вывода с диском занимают подавляющее количество времени при выполнении запросов. На скорость доступа к данным также могут влиять и дополнительные факторы. Например, ОС может буферизировать (кэшировать) блоки. Также на скорость записи влияет то, насколько далеко друг от друга находятся блоки.
Скорость доступа к данным будет зависеть от организации хранения блоков в файле.
Организация файла в виде кучи.
Это наиболее простой способ организации файлов. При этом записи помещаются в блоки без какого-либо порядка, блоки выстраиваются таким же образом. Записи помещаются в один блок последовательно по мере появления. Когда блок заполняется, выделяется новый блок и указатель на него помещается в предыдущий; аналогичным образом производится заполнение нового блока.
Поиск осуществляется следующим образом: задается значение ключа (значение искомых полей), и находится запись (записи), у которых значение полей совпадает с искомым значением. Если о ключе известно, что он уникален, поиск прекращается после первой же найденной записи.
Вставка представляет собой добавление записи в конец файла. Если отношение подразумевает наличие первичного ключа, то перед выполнением вставки выполняют операцию поиска для проверки уникальности первичного ключа.
При удалении предполагается, что неизвестно, есть ли удаляемая запись в файле. Поэтому также необходимо предварительно выполнить операцию поиска. Поиск выполняется и при модификации данных.
Эффективность кучи. Пусть в файле существует N записей. В каждый блок может поместиться R записей, то есть в файле должно быть R/N блоков. Время выполнения операций измеряем количеством блоков, которые должны быть запрошены с диска или записаны на него.
При поиске записи в файле возможны два варианта: если запись отсутствует в файле или если поле, по которому осуществляется поиск, не является уникальным, придется просмотреть R/N блоков. В противном случае потребуется считать R/2N блоков.
При вставке необходимо запросить последнюю запись в куче, так как именно после нее идет свободное место. То есть нужно считать последний блок, если последний блок не имеет пустого места, то нужно начать новый блок.
После вставки блок должен быть записан на диск. Таким образом, для вставки потребуются два обращения к диску: один по чтению, другой по записи. Если при этом необходимо контролировать отсутствие повторяющихся записей или уникальность сочетания атрибутов, то добавляется время выполнения поиска.
Удаление требует найти запись, то есть выполнить операцию поиска, а затем выполнить операцию записи блока, в котором была найдена запись. Таким образом, для удаления записи потребуется в среднем R/2N+1 доступов, если запись существует в файле. Если же ее нет, то выполнится N/R доступов. Для дальнейшего использования освободившегося пространства последняя запись последнего блока может быть помещена на место удаленной записи. Это добавит по одной операции чтения и записи.
Таким образом, основное время при выполнении всех операций затрачивается на поиск записи, следовательно, необходимо ускорить именно поиск. Это может быть достигнуто за счет другой организации файла.
Хэшированные файлы.
Основная идея хэшированных файлов состоит в том, что записи разбиваются на бакеты, согласно значению ключа. Бакет – не блок, а совокупность записей с одним значением hash-функции.
Для каждого файла, организованного подобным образом, должна быть выбрана hash-функция h(v). В качестве параметра функция получает значение ключа, а на выходе она должна выдавать значение целого типа в диапазоне от нуля до B-1, где В – планируемое количество бакетов в файле.
Каждый бакет состоит из некоторого числа блоков, внутри бакета блоки организованы в виде кучи. При этом должен существовать массив указателей, индексированный от 0 до В-1. Этот массив называется каталогом бакетов. Для хранения каталогов бакетов может быть использован нулевой блок файла. Каждый итый элемент массива является указателем на первый блок итого бакета.
Основная проблема построения хэшированного файла – выбор hash-функции. Главное требование – функция должна принимать все возможные значения с приблизительно равной вероятностью. Простейший вид: h(v)=v mod B.
Пусть размер записи таков, что в блок помещаются 3 записи. Будем считать, что в файле должно быть 4 бакета. Тогда в качестве hash-функции выберем остаток от деления номера сотрудника на 4.
Для поиска записи с ключом v вычисляем значение h(v), считываем соответствующий заголовок бакета, а затем проверяем блоки, начиная с того, который хранится первым в указателе.
Если на каком-либо шаге рассматриваемый блок имеет нулевой указатель, а запись все еще не найдена, то нет необходимости рассматривать остальные блоки файла, так как они не соответствуют хеш-функции указанного ключа.
Все операции на хешированных файлах производятся в В раз быстрее, чем на файлах, организованных в виде кучи (В – число бакетов).
Индексированные файлы.
Основная идея заключается в построении для файла, содержащего записи одной таблицы, дополнительного файла индекса. Индекс состоит из пар: значение ключа, адрес данных. Данные в индексе всегда упорядоченные.
Индексы бывают двух видов: первичные (разряженные) и вторичные (плотные).
Первичный индекс для отношения может быть только один, так как он задает физический порядок записи в файле. В теории от первичного индекса требуется уникальность значения полей, по которым он построен. На практике же это необязательное условие.
Вторичных индексов для отношения может быть много. Они не требуют уникальности значений и не изменяют физического порядка следования записей в файле.
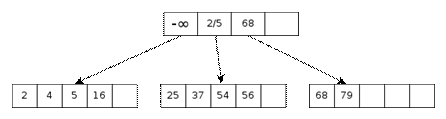
Разреженные индексы.
Такие индексы состоят из пар вида: адрес блока, минимальное значение ключа в блоке. При этом минимальное значение будет принадлежать самой первой записи в блоке, так как разреженные индексы предполагают физическое упорядочивание файла. При создании разряженного индекса в блоках главного файла обычно оставляется пустое место для ускорения последующей вставки.
Самое первое значение в индексе заменяется на «-∞», чтобы не обрабатывать в алгоритме поиска частный случай.
Пусть v1 – значение ключа искомой записи, тогда в индексе ищем запись (v2,b), такую, что v2 <= v1, и либо v2- последняя запись в индексе, либо следующие записи имеют вид (v3,b) (при этом v3>v1). В этом случае говорят, что v2 покрывает v1.
Таким образом, находится блок, в котором должна содержаться запись со значением ключа v1. Согласно адресу, извлекаем блок, искомая запись должна содержаться либо в этом блоке, либо она отсутствует в файле.
Следовательно, в целом скорость поиска зависит от скорости поиска в индексном файле. Применяются три основных вида поиска:
- линейный поиск (если файл индекса не упорядочен). Последовательно перебираются все блоки и все записи индекса. Даже при такой организации получается выигрыш: если в главном файле имеется R записей в блоке, то по сравнению с организацией его в виде кучи, поиск будет проходить в R раз быстрее,
- двоичный поиск подразумевает не нарушаемое упорядочивание записей не только в главном файле, но и в индексе. Выигрыш получается за счет ускорения поиска по индексу,
- интерполирующий поиск. В этом случае кроме упорядочивания записей в индексе важную роль играет знание статистики распределения значений ключей. При работе этого метода должна существовать функция f(v1, v2, v3), она возвращает в качестве результата блок, в котором может находиться запись со значением ключа, равным v1, если известно, что v1 находится между v2 и v3. Поиск также продолжается, пока не останется один блок, который и считывается в оперативную память. Затем в нем перебором ищется покрывающая v1 запись.
Операции удаления, вставки и модификации не должны нарушать порядка следования записей ни в главном, ни в индексном файлах.
Эффективность поиска в таких файлах дополняется еще и физическим порядком записей главного файла, то есть не тратится время на перемещение головки чтения к следующей записи, так как она располагается в непосредственной близости.
Вторичные индексы.
Индексный файл при такой организации состоит из пар вида <значение ключа, адрес записи>, то есть в индексе содержится информация о каждой записи главного файла. Поэтому они называются плотными индексами.
Дополнительная выгода при поиске может заключаться в том, что все необходимые вычисления можно выполнить на файле индекса, а из главного файла извлечь только нужные записи.
Для индексных файлов существует дополнительное усовершенствование - построение B-дерева. Его можно представить как иерархию индексов (дерево строится до тех пор, пока индекс не будет содержать только один блок). Эффективность такой организации заключается в том, что при поиске нужно будет прочитать только по одному блоку каждого уровня индекса.
Выбор индексов.
Для одной таблицы можно построить только один разреженный индекс и сколько угодно плотных. Однако следует учитывать, что наличие индексов замедляет операции модификации данных.
В общем случае индексы повышают эффективность поиска, но замедляют операции вставки, удаления и модификации. Поэтому, если в системе данные чаще всего извлекаются, то следует увеличивать число индексов. Если же критична скорость операции модификации, то количество индексов нужно сокращать.
Синтаксис создания индексов смотри выше.
При создании отношения обычно автоматически создается первичный индекс по первичному ключу. Рекомендуется строить индексы по полям внешнего ключа, а также по тем полям, по которым наиболее часто производится выборка и сортировка.
Перед построением или перестройкой индексов целесообразно проанализировать статистику обращений к таблице, используя вспомогательные возможности СУБД.
Управление транзакциями.
Транзакция – действие или последовательность действий, выполняемых одним пользователем или прикладной программой, осуществляющих доступ к БД или изменение содержимого БД, и расцениваемых СУБД как единое целое. Иначе, это логическая единица работы или единица восстановления, то есть транзакция подразумевает, что все действия в ее рамках будут либо все выполнены, либо все отвергнуты.
Транзакция для пользователя – набор операций select, insert, update, delete. Для СУБД даже одна команда пользователя может быть транзакцией из некоторых операций. Например, изменение зарплаты сотруднику с определенным табельным номером.
Любая транзакция должна всегда переводить базу данных из одного согласованного состояния в другое согласованное состояние, хотя допускается, что согласованность базы данных будет нарушаться в ходе выполнения транзакции.
Согласованное состояние – состояние данных, отвечающее всем определенным для баз данных правилам целостности.
Пример: пусть студент обучается на специальности некоторое время, он получил оценки согласно плану этой специальности. При переводе студента на другую специальности транзакция будет состоять из следующих действий:
- найти предметы, которые должен был изучить студент, согласно плану новой специальности,
- для каждого этого предмета найти оценку переводимого студента и перезачесть ее,
- все остальные оценки удалить,
И до и после выполнения транзакции база данных находится в согласованном состоянии: все студенты имеют оценки согласно плану обучения по специальности. Но в ходе выполнения транзакции часть оценок студента не относится к специальности, на которой он обучается.
Любая транзакция завершается любым из двух возможных способов:
- в случае успешного ее завершения результаты транзакции фиксируются (commit) и база данных переходит в новое согласованное состояние,
- если при выполнении транзакции возникли ошибки или сбои, она отменяется и в базе данных должно быть восстановлено то согласованное состояние, в котором она находилась до начала прерванной транзакции (roll back - откат).
Зафиксированная транзакция не может быть отменена. Если зафиксированная транзакция была ошибочной, то необходимо выполнить другую транзакцию, возвращающую базу данных в предыдущее, согласованное состояние.
В большинстве языков манипулирования данными существуют такие команды, которые были описаны выше.
Существуют свойства, которым должна обладать транзакция:
- атомарность – представляет собой неделимую единицу работы,
- согласованность,
- изолированность – все транзакции выполняются независимо одна от другой, то есть результаты незавершенной транзакции не должны быть доступны другим транзакциям,
- продолжительность – результаты успешно завершенной транзакции должны сохраняться в базе данных постоянно и не должны быть утеряны в результате последующих сбоев.
Управление параллельностью.
Процесс организации одновременного выполнения в базе данных различных транзакций, гарантирующей исключение их взаимного влияние друг на друга. Проблем управления параллельностью не существовало бы, если бы:
1) можно было бы осуществлять последовательный доступ пользователей к данным,
2) несколько пользователей читали и изменяли бы непересекающиеся множества элементов данных.
Проблемы возникают только при модификации транзакцией элемента, который читается или модифицируется другой транзакцией, например:
Время
Т1
Т2
Значение элемента f
t1
Begin tran
t2
Begin tran
Read f
t3
Read f
F:=f+100
t4
F:=f-10
Write f
t5
Write f
commit
t6
commit
Аномалия потерянного обновления – несмотря на то, что вторая транзакция зафиксировала результат, он все равно был потерян.
Значение элемента f равно 90, а если бы транзакции выполнялись последовательно, то значение элемента f было бы равно 190 – наблюдаем явное влияние транзакций друг на друга.
Один из способов решения проблемы параллельного доступа – блокировки.
Блокировка.
Блокировка – механизм, реализованный в СУБД, который позволяет одной транзакции отклонить попытки других транзакций выполнить конфликтные действия с указанным элементом.
Блокировки хранятся в СУБД в таблице в виде (<элемент блокировки>, <тип блокировки>, <транзакция>).
В качестве элементов блокировки могут выступать: кортежи, поля, отношения, а также блоки или страницы, или база данных в целом.
Большие элементы уменьшают пространство, занимаемое таблицей блокировок, и время на ее обработку. Маленькие элементы позволяют большему числу транзакций работать одновременно.
Большинство СУБД по умолчанию выполняют постраничную блокировку, настольные СУБД чаще всего блокируют целые отношения.
Блокировки бывают на чтение и на запись. Блокировка на чтение означает, что другая транзакция сможет считать этот элемент, но не сможет его изменить. Одновременно другие транзакции также могут установить блокировку чтения на этот же элемент, такие блокировки называют разделяемыми.
Блокировка на запись элемента данных может устанавливаться только одной транзакцией. При этом никакая другая транзакция не может получить доступ к элементу ни по чтению, ни по записи. Такие блокировки называют эксклюзивными.
Обработка данных с использованием механизма блокировок ведется следующим образом:
1) Если транзакции необходимо получить доступ к элементу, она сначала должна выполнить его блокировку.
2) Если элемент никем не заблокирован, устанавливается блокировка запрашиваемого вида и транзакция получает доступ к элементу.
3) Если элемент уже заблокирован, то выполняется анализ существующей и запрашиваемой блокировки. Если они обе на чтение, то на элемент устанавливается еще одна блокировка, и транзакция получает доступ на чтение. В противном случае транзакция переходит в состояние ожидания, которое будет продолжаться до тех пор, пока с элемента не будут сняты существующие блокировки.
4) Транзакция удерживает блокировку элемента до тех пор, пока она явным образом не освободит элемент. Это происходит либо в ходе выполнения транзакции явно, либо по ее окончании, как успешном, так и не успешном.
Использование в транзакциях блокировок само по себе не гарантирует отсутствие влияний транзакций друг на друга.
Т1
Т2
Begin tran
Begin tran
writeLock X
Read X
X=X+100
Write X
Unlock X
writeLock X
Read X
X=X*1.1
Write X
Unlock X
writeLock Y
Read Y
Y=Y*1.1
Write Y
Unlock Y
Commit
Writelock Y
Read Y
Y=Y+100
Write Y
Commit
Если просчитать значения элементов при последовательном выполнении транзакций, то они будут другими. Проблема неупорядоченности осталась из-за того, что первая транзакция сняла блокировку с элемента, а затем установила блокировку на другой элемент.
Это было сделано вроде бы для повышения производительности, однако в результате получили некорректную работу транзакций.
Двухфазный протокол.
Для обеспечения корректности работы используют протоколы, регламентирующие правила на установку и снятие блокировки. Самый известный из таких протоколов – протокол двухфазной блокировки.
Транзакция следует этому протоколу, если в ней все операции блокировки предшествуют первой операции разблокировки. Таким образом, транзакция делится на две фазы:
- фаза нарастания, в которой выполняются все необходимые блокировки, не освобождая ни одного элемента;
- фаза сжатия (фиксация), в которой освобождаются элементы и не устанавливается ни одна блокировка.
СУБД при выполнении транзакций следуют двухфазному протоколу, но если программист сам начнет управлять блокировками, например, для повышения производительности, то необходимо следовать данному протоколу.
Взаимная блокировка (тупик).
Возникает в случае, когда две или более транзакции находятся во взаимном ожидании освобождения элементов, удерживаемыми каждой из них.
Т1
Т2
Begin tran
Writelock x
Begin tran
Read x
Writelock y
Writelock y
Read y
wait
Writelock x
Wait
Таким образом, ни одна из транзакций не может быть закончена. СУБД борются с тупиками следующим образом: во время работы параллельных транзакций через определенные промежутки времени выполняется поиск тупиков.
Для их поиска строится граф ожиданий. Вершины графа соответствуют транзакциям, выполняемым в данный момент времени, ребро Ti->Tj строится в случае, когда Ti ожидает освобождения элемента, занятого Tj. Взаимная блокировка имеет место в том случае, когда граф ожидания содержит цикл.
При обнаружении тупика одна из транзакций должна быть отменена. Возникает вопрос выбора такой транзакции, то есть снятие той, которая решит проблему с минимальными затратами ресурсов.
В идеальном случае после снятия транзакции выхода из тупика, СУБД должна повторить снятую транзакцию. На практике deadlock появляется на клиенте и он сам должен перезапустить транзакцию.
Уровни изоляции транзакции.
При параллельной работе нескольких транзакций для повышения производительности для транзакций можно установить уровень изоляции, то есть возможность оперировать промежуточными данными других транзакций (устанавливается программистом).
Уровень изоляции – степень влияния изменений транзакции на параллельные транзакции.
Общепринятыми являются следующие уровни изоляции:
Read uncommitted – позволяет читать изменения, внесенные незаконченными транзакциями, то есть он позволяет читать «грязные» данные. При таком подходе возможны нарушения некоторых правил целостности, а также возможно появление «фантомных строк», то есть кортежей, которые были внесены транзакцией 1, затем считаны транзакцией 2, затем отменены вместе с транзакцией 1, но не перечитаны транзакцией 2. Используется в основном для отслеживания изменений длительных транзакций и для чтения редко изменяемых данных.
Read committed – чтение и изменение только завершенных транзакций. Здесь отсутствуют все проблемы, связанные с чтением «грязных» данных.
Repeatable Read – при таком уровне изоляции данные, прочитанные транзакцией один раз, никогда не изменяются, даже если фактически они были изменены другими транзакциями. Такой уровень изоляции имеет смысл использовать только для транзакций, читающих данные.
Serializable – запрещено чтение всех данных, измененных с начала транзакции, в том числе и своей транзакции, фантомы невозможны. Идентичен ситуации, когда транзакции выполняются последовательно.
Уровни 3 и 4 используются при повышенных требованиях к изолированности транзакций.
Восстановление базы данных.
Процесс возвращения базы данных в корректное состояние, утраченное в результате сбоя или отказа системы. Причины возможных отказов:
- аварийное прекращение работы системы, вызванное ошибкой оборудования или ПО, которое привело к разрушению оперативной памяти,
- отказ носителей информации,
- ошибки прикладных программ, например, логические ошибки в программах, послужившие причинами сбоев при выполнении некоторых транзакций,
- стихийные бедствия,
- непреднамеренное или преднамеренное разрушение данных пользователями системы или при внешней атаке.
Обычно СУБД имеют следующие функции восстановления:
1) Механизм резервного копирования (backup). Позволяет создавать резервные копии базы данных и ее журнала транзакций без необходимости останавливать систему. Резервная копия используется в случае повреждения физического носителя, содержащего базу данных. В этом случае база данных восстанавливается с резервной копии в том состоянии, в котором находилась на момент ее создания (все изменения, сделанные после, будут потеряны).
Резервное копирование может выполняться как в целом для базы данных, так и в инкрементном режиме (создаются разностные копии), то есть в backup помещаются изменения, произошедшие с базой данных с момента последнего резервного копирования. Это уменьшает требуемое для резервных копий пространство, но удлиняет процесс восстановления. Кроме того, при потере одной из разностных копий дальнейшее восстановление становится невозможным. Существует возможность создавать резервные копии как для целой базы данных, так и для отдельных таблиц.
2) Журнал – отдельный файл, который содержит информацию о ходе выполнения транзакций в базе данных. Для каждой операции, выполненной в базе данных, журнал может содержать следующую информацию:
- идентификатор транзакции,
- тип записи (начало транзакции, операция вставки, удаления, модификации, отмена транзакции или ее фиксация),
- идентификатор элемента данных, вовлеченного в операцию,
- копия элемента данных до начала операции,
- копия элемента данных по окончанию операции,
- служебная информация (указатель на следующую и предыдущую операцию этой транзакции).
Журнал транзакции является основой реализации механизма транзакции.
3) Создание контрольных точек (check point). Помещаемая в журнал информация предназначена для использования в процесс восстановления после отказа. Одно из основных затруднений при использовании журнала транзакции состоит в том, что при отказе может отсутствовать какая-либо информация о том, насколько далеко следует сделать откат в файле журнала, чтобы начать повторное выполнение завершенных транзакций.
Для ограничения повторного выполнения используются контрольные точки.
Контрольная точка – запись в журнале транзакции, отмечающая момент синхронизации между журналом и базой данных, то есть момент, когда все блоки базы данных из оперативной памяти записаны на диск. Таким образом, восстановление должно идти с последней контрольной точки.
Журналы баз данных имеют тенденцию к быстрому увеличению размеров, поэтому возникает необходимость их усечения. Для того, чтобы сохранилась возможность восстановления, усечение должно быть произведено до последней контрольной точки. Однако журналы могут использоваться не только для восстановления, но и для аудита, то есть для отслеживания обращений к базе данных. В этом случае информация будет потеряна.