Ортогональные преобразования в диадных (или иначе говоря, двузначных знакопеременных) базисах определены для данных, представленных векторами длиной N= 2M. К таким преобразованиям относятся преобразования Адамара, Пэли, Уолша, Трахтмана, Качмарджа и ряд других [6,11,21]. Матрица ядра любого из подобных преобразований содержит целочисленные коэффициенты из множества {-1; +1}. Очевидно, что при выполнении подобных преобразований существенно сокращается объем вычислений за счет исключения умножения в каждой базовой операции.
Матрица ядра преобразования Уолша - Адамара для N =2m может быть описана как результат кронекеровского произведения m матриц ДЭФ E2 размера 2х2 [6,12]:
, (6.14)
где символ Ä - операция кронекеровского умножения векторов, в результате чего порождается матрица блочной структуры. Заметим, что операция кронекеровского умножения двух матриц и состоит в получении блочной матрицы, блоками которой является умноженная на соответствующий элемент правой матрицы левая матрица, т.е.:
аналогично можно получить и для N = 8:
Матрица ядра Адамара обладает следующими свойствами:
1) цикличностью aN+k = ak; aN-k = a-k
2) мультипликативностью ak+l = ak * al
3) симметричностью AN = ANT
В задачах ЦОС используются и другие, подобные Адамару, преобразования - Пэли, Уолша, Трахтмана и других. Ядра (матрицы) этих преобразований могут быть получены на основе матрицы ядра преобразования Адамара при определенном переупорядочении их строк. Поэтому перед рассмотрением указанных преобразований рассмотрим правила переупорядочения матриц, применяемые для формирования ядер таких преобразований.
Переупорядочим элементы векторатаким образом, чтобы первые элементы вектора были бы чётными, а вторые - нечётными. Повторим эту процедуру до тех пор, умножая каждый раз длину соответствующего вектора вдвое, пока длина подвектора не станет равной 2. В результате получится переупорядоченный вектор, элементы которого упорядочены по закону так называемой двоичной инверсии.
В частности, для N=8 такое переупорядочение будет выполняться следующим образом:
Вектор можно получить из X, если задать следующее правило формирования индекса текущего элемента вектора из индекса элемента исходного вектора X:
1) записывается двоичный код текущего индекса i;
2) двоичный код записывается в обратном порядке как рефлексивный или отраженный код (т.е. начиная с младших разрядов);
3) полученный код определяет индекс текущего элемента вектора ;
4) переводим полученный индекс в десятичную систему.
Для рассмотренного выше случая (N=8) получим:
Процедура перестановки в терминах векторно-матричных операций может быть записана как:
, (6.15)
где - перестановочная матрица. Для случая двоично-инверсной перестановки перестановочная матрица будет иметь вид:
Элементы вектора могут быть также переупорядочены по коду Грея:
В терминах векторно-матричных операций подобная перестановка элементов вектора может быть описана так:
,
где - перестановочная матрица, в частности, для N=8:
Ядро преобразования Пэли можно получить из ядра преобразования Адамара, переупорядочив строки матрицы AN по закону двоичной инверсии, в частности, для N =8 получаем:
В общем случае правило перехода от матрицы Адамара к матрице Пэли может быть представлено как [6]:
(6.16)
Если теперь переупорядочить строки матрицы ядра преобразования Пэли по коду Грея, то получим матрицу ядра преобразования Уолша[8]
Или в общем виде:
(6.18)
Очевидно, что свойства матриц PN и WN аналогичны свойствам матрицы AN. Матрицы ядер преобразования Трахтмана и Качмарджа также могут быть получены на основе матрицы ядра Адамара, но при использовании обратной перестановки по коду Грея.
Заметим, что матрицы преобразований в указанных базисах отличаются порядком строк. Очевидно, что при обработке одного и того же вектора исходных данных в различных базисах вектор результата будет содержать одинаковые по своей величине элементы, отличаясь для каждого преобразования лишь порядком их следования. Поэтому для всех подобных преобразований можно использовать одну и ту же матрицу ядра ( например, AN), а для получения вектора F с нужным для каждого преобразования порядком следования элементов, переупорядочить элементы исходного вектора . Так, для преобразования Пэли необходима двоично-инверсная перестановка, а для преобразования Уолша - двоично-инверсная перестановка и затем перестановка по коду Грея.
Если проанализировать все рассмотренные во второй главе преобразования, то можно придти к выводу, что их сущность состоит в разложении исходной функции на ряд чётных и нечётных составляющих, которые задаются строками матриц EN, HN, AN, WNи PN. Так, для матриц EN и HN это набор гармонических функций cos[…] и sin[..], а для AN, WNи PN - наборы прямоугольных знакопеременных функций.
Тем самым, в зависимости от вида исходной функции, в её составе будут определены отдельные компоненты (и их частотное значение), которые задаются строками матрицы ядра преобразования. Очевидно, что разложение по ортогональным функциям, задаваемым строками матрицы EN ,позволяет определить частотный состав исходной функции (сигнала), что имеет вполне понятный физический смысл.
Точно также при разложении по функциям, задаваемым строками матриц AN, WNи PN, можно определить, какой вклад вносит та или иная знакопеременная функция в состав исходного сигнала.
Очевидно, что исходный сигнал может быть разложен по различным ортогональным составляющим. При этом вклад таких составляющих в исходный сигнал будет различен для разных матриц ортогональных преобразований.
Согласно теореме Коруэна-Лоева [21], может быть определено оптимальное разложение исходной функции по набору ортогональных функций в смысле наименьшего числа отличных от нуля компонент такого разложения.
На практике для сигналов гармонической природы удобно использовать различные гармонические функции, т.е. для определения частотного состава сигнала выполнить преобразование Фурье или Хартли (ДПФ или БПФ). Действительно, для моногармонического сигнала лишь одна компонента разложения по строкам матрицы EN будет отлична от “0” (при условии, что f0 кратно kπ).
Для сигналов, описываемых знакопеременными функциями, близким к оптимальному является разложение по знакопеременным функциям типа Уолша, Адамара. Поэтому в задачах кодирования и распознавания речи, где для представления сигналов широко используется метод широтно-импульсной модуляции, удобно выполнять разложение по ортогональным функциям, задаваемым строками матриц AN, WN или PN.

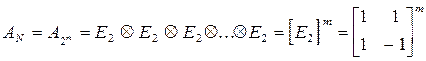 , (6.14)
, (6.14)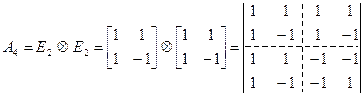
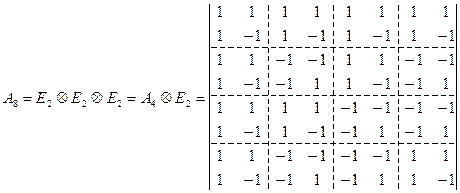
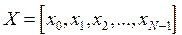 таким образом, чтобы первые элементы вектора были бы чётными, а вторые - нечётными. Повторим эту процедуру до тех пор, умножая каждый раз длину соответствующего вектора вдвое, пока длина подвектора не станет равной 2. В результате получится переупорядоченный вектор, элементы которого упорядочены по закону так называемой двоичной инверсии.
таким образом, чтобы первые элементы вектора были бы чётными, а вторые - нечётными. Повторим эту процедуру до тех пор, умножая каждый раз длину соответствующего вектора вдвое, пока длина подвектора не станет равной 2. В результате получится переупорядоченный вектор, элементы которого упорядочены по закону так называемой двоичной инверсии.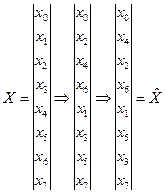
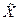 можно получить из X, если задать следующее правило формирования индекса текущего элемента вектора
можно получить из X, если задать следующее правило формирования индекса текущего элемента вектора 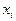 исходного вектора X:
исходного вектора X: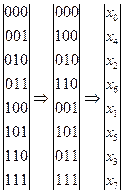
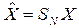 , (6.15)
, (6.15)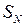 - перестановочная матрица. Для случая двоично-инверсной перестановки перестановочная матрица будет иметь вид:
- перестановочная матрица. Для случая двоично-инверсной перестановки перестановочная матрица будет иметь вид: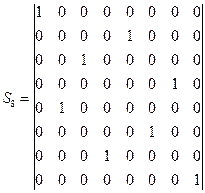
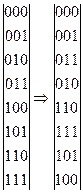
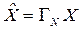 ,
,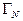 - перестановочная матрица, в частности, для N=8:
- перестановочная матрица, в частности, для N=8: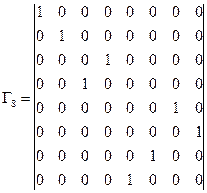
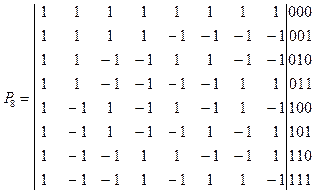
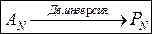 (6.16)
(6.16)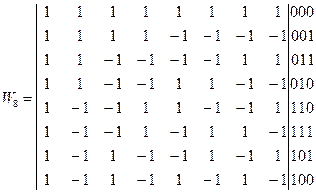
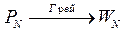 (6.18)
(6.18)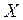 в различных базисах вектор результата будет содержать одинаковые по своей величине элементы, отличаясь для каждого преобразования лишь порядком их следования. Поэтому для всех подобных преобразований можно использовать одну и ту же матрицу ядра ( например, AN), а для получения вектора F с нужным для каждого преобразования порядком следования элементов, переупорядочить элементы исходного вектора
в различных базисах вектор результата будет содержать одинаковые по своей величине элементы, отличаясь для каждого преобразования лишь порядком их следования. Поэтому для всех подобных преобразований можно использовать одну и ту же матрицу ядра ( например, AN), а для получения вектора F с нужным для каждого преобразования порядком следования элементов, переупорядочить элементы исходного вектора 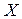 . Так, для преобразования Пэли необходима двоично-инверсная перестановка, а для преобразования Уолша - двоично-инверсная перестановка и затем перестановка по коду Грея.
. Так, для преобразования Пэли необходима двоично-инверсная перестановка, а для преобразования Уолша - двоично-инверсная перестановка и затем перестановка по коду Грея.