По своей встречаемости в типичных программах списки занимают второе место после массивов. Многие языки имеют встроенные типы списков, некоторые, такие как Lisp, даже построены на них, но в языке С мы должны конструировать их самостоятельно. В C++ и Java работа со списками поддерживается стандартными библиотеками, но и в этом случае нужно знать их возможности и типичные применения. В данном параграфе мы собираемся обсудить использование списков в С, но уроки из этогр обсуждения можно извлечь и для более широкого применения.
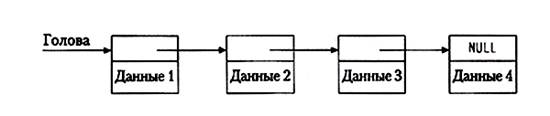
Простым цепным списком (single-linked list) называется последовательность элементов, каждый из которых содержит данные и указатель на следующий элемент. Головой списка является указатель на первый элемент, а конец помечен нулевым указателем. Ниже показан список из четырех элементов:
Есть несколько важных различий между массивами и списками. Во-первых, размер массивов фиксирован, а список всегда имеет именно такой размер, который нужен для хранения содержимого, плюс некоторое дополнительное место для указателей на каждый элемент. Во-вторых, списки можно перестраивать, изменяя несколько указателей, что дешевле, чем копирование блоков, необходимое при использовании массива. Наконец, при удалении или вставке элементов остальные элементы не перемещаются; если мы будем хранить указатели на отдельные элементы в другой структуре данных, то при изменениях в списке они останутся корректными.
Эти различия подсказывают, что если набор данных будет часто меняться, особенно при непредсказуемом количестве элементов, то нужно использовать список; напротив, массив больше подходит для относительно статичных данных.
Фундаментальных операций со списком совсем немного: добавить элемент в начало или конец списка, найти указанный элемент, добавить новый элемент до или после указанного элемента и, возможно, удалить элемент. Простота списков позволяет при необходимости легко добавлять новые операции.
Вместо того чтобы определить специальный тип List, обычно в С начинают определение списка с описания типа для элементов, вроде нашего Nameval, и добавляют в него указатель на следующий элемент:
typedef struct Nameval Nameval;
struct Nameval {
char *name:
int value;
Nameval «next;
/* следующий в списке */ };
Инициализировать непустой список во время компиляции трудно, поэтому списки, не в пример массивам, создаются динамически. Для начала нам нужен способ создания элемента. Наиболее простой подход — выделить под него память специальной функцией, которую мы назвали newitem:
/* newitem: создать новый элемент
по полям name и value */ Nameval
*newitem(char *name, int value)
{
Nameval *newp;
newp = (Nameval *) emalloc(sizeof(Nameval));
newp->name = name; newp->value
= value; newp->next = NULL; return newp; }
Функцию emalloc мы будем использовать и далее во всей книге; она вызывает mall ос, а при ошибке выделения памяти выводит сообщение и завершает программу. Мы представим код этой функции в главе 4, а пока считайте, что эта функция всегда корректно и без сбоев выделяет память.
Простейший и самый быстрый способ собрать список — это добавлять новые элементы в его начало:
/* addfront: добавить элемент newp
в начало списка listp */ Nameval
*addfront
(Nameval *listp, Nameval *newp)
{
newp->next = listp;
return newp; }
При изменении списка у него может измениться первый элемент, что и происходит при вызове addf ront. Функции, изменяющие список, должны возвращать указатель на новый первый элемент, который хранится в переменной, указывающей на список. Функция addfront и другие функции этой группы передают указатель на первый элемент в качестве возвращаемого значения; вот типичное использование таких функций:
Такая конструкция работает, даже если существующий список пуст (NULL), она хороша и тем, что позволяет легко объединять вызовы функций в выражениях. Это более естественно, чем альтернативный вариант — передавать указатель на указатель на голову списка.
Добавление элемента в конец списка — процедура порядка 0(п), поскольку нам нужно пройтись по всему списку до конца:
/* addend: добавить элемент newp
в конец списка listp */
Nameval *addend(Nameval *listp,
Namevai *newp)
{
Nameval *p;
if (listp == NULL)
return newp; for (p = listp; p->next !=
NULL; p = p->next)
p->next = newp; return listp; }
Чтобы сделать addend операцией порядка 0(1), мы могли бы завести отдельный указатель на конец списка. Недостаток этого подхода, кроме того, что нам нужно заботиться о корректности этого указателя, состоит в том, что список теперь уже представлен не одной переменной, а двумя. Мы будем придерживаться более простого стиля.
Для поиска элемента с заданным именем нужно пройтись по указателям next:
/* lookup: последовательный поиск
имени в списке */
Nameval *lookup(Nameval *listp, char *name)
{
for ( ; listp != NULL; listp = listp->next)
if (strcmp(name, listp->name) == 0)
return listp;
return NULL; /* нет совпадений */ }
Поиск занимает время порядка 0(п), и, в принципе, эту оценку не улучшить. Даже если список отсортирован, нам все равно нужно пройтись по нему, чтобы добраться до нужного элемента. Двоичный поиск к спискам неприменим.
Для печати элементов списка мы можем написать функцию, проходящую по списку и печатающую каждый элемент; для вычисления длины списка — функцию, проходящую по нему, увеличивая счетчик, и т. д. Альтернативный подход — написать одну функцию, apply, которая проходит по списку и вызывает другую функцию для каждого элемента. Мы можем сделать функцию apply более гибкой, предоставив ей аргумент, который нужно передавать при каждом вызове функции. Таким образом, у apply три аргумента: сам список, функция, которую нужно применить к каждому элементу списка, и аргумент для этой функции:
/* apply: применить
функцию fn
для каждого элемента списка listp
*/ void apply(Nameval *listp,
void (*fn)(Nameval*, void*), void *arg)
{
for ( ; listp != NULL; listp
= listp->next) (*fn)(listp, arg);
/* вызов функции */ }
Второй аргумент apply — указатель на функцию, которая принимает два параметра и возвращает void. Стандартный, хотя и весьма неуклюжий, синтаксис
* void (*fn)(Nameval*, void*) определяет f n как указатель на функцию с возвращаемым значением типа void, то есть как переменную, содержащую адрес функции, которая возвращает void. Функция имеет два параметра — типа Nameval * (элемент списка) и void * (обобщенный указатель на аргумент для этой функции).
Для использования apply, например для вывода элементов списка, мы можем написать тривиальную функцию, параметр которой будет восприниматься как строка форматирования:
/* printnv: вывод имени и значения
с использованием формата в arg
*/ void printnv(Nameval *p, void *arg) {
char *fmt;
fmt = (char *) arg; printf(fmt,
p->name, p->value); }
тогда вызывать мы ее будем так:
apply(nvlist, printnv, "%s: %x\n");
Для подсчета количества элементов мы определяем функцию, параметром которой будет указатель на увеличиваемый счетчик:
/* inccounter: увеличить счетчик *arg
*/ void inccounter(Nameval
*p, void *arg) {
int *ip;
/*' p не используется
*/ ip = (int *) arg; (*ip)++; }
Вызывается она следующим образом:
int n;
n = 0;
apply(nvlist, inccounter, &n);
printf("B nvlist %d элементов\n",
n);
He каждую операцию над списками удобно выполнять таким образом. Например, при удалении списка надо действовать более аккуратно:
/* freeall:
освободить все
элементы списка listp */
void freeall(Nameval *listp)
{
Nameval *next;
for ( ; listp != NULL; listp = next)
{ next = listp->next; /* считаем, что
память, занятая строкой name,
освобождена где-то в
другом месте */ free(listp);
}
}
Память нельзя использовать после того, как мы ее освободили, поэтому до освобождения элемента, на который указывает listp, указатель listp->next нужно сохранить в локальной переменной next. Если бы цикл, как и раньше, выглядел так:
? for ( ; listp != NULL; listp = listp->next) ?
free(listp); то значение listp->next могло быть затерто вызовом free и код бы не работал.
Заметьте, что функция freeall не освобождает память, выделенную под строку listp->name. Это подразумевает, что поле name каждого элемента типа Nameval было освобождено где-то еще либо память под него не была выделена. Чтобы обеспечить корректное выделение памяти под элементы и ее освобождение, нужно согласование работы newitem и f гее-all; это некий компромисс между гарантиями того, что память будет освобождена, и того, что ничего лишнего освобождено не будет. Именно здесь при неграмотной реализации часто возникают ошибки. В других языках, включая Java, данную проблему за вас решает сборка мусора. К теме управления ресурсами мы еще вернемся в главе 4.
Удаление одного элемента из списка — более сложный процесс, чем добавление:
/* delitem: удалить первое вхождение
"name" в listp */
Nameval *delitem(Nameval *listp, char
*name)
{
Nameval *p, *prev;
prev = NULL;
for (p = listp; p != NULL; p = p->next)
{ if (strcmp(name, p->name) == 0)
{ if (prev == NULL)
listp = p->next; else
prev->next = p->next; f ree(p);
return listp; }
prev = p; } eprintf("delitem: %s в
списке отсутствует",
name);
return NULL;
/* сюда не дойдет */
}
Как и в f reeall, delitem не освобождает память, занятую полем namе.
Функция eprintf выводит сообщение об ошибке и завершает программу, что в лучшем случае неуклюже. Грамотное восстановление после произошедших ошибок может быть весьма трудным и требует долгого обсуждения, которое мы отложим до главы 4, где покажем также реализацию eprintf.
Представленные основные списочные структуры и операции применимы в подавляющем большинстве случаев, которые могут встретиться в ваших программах. Однако есть много альтернатив. Некоторые библиотеки, включая библиотеку стандартных шаблонов (Standard Template Library, STL) в C++, поддерживают двухсвязные списки (double-linked lists: списки с двойными связями), в которых у каждого элемента есть два указателя: один — на последующий, а другой — на предыдущий элемент. Двухсвязные списки требуют больше ресурсов, но поиск последнего элемента и удаление текущего — операции порядка О( 1). Иногда память под указатели списка выделяют отдельно от данных, которые они связывают; такие списки несколько труднее использовать, но зато одни и те же элементы могут встречаться более чем в одном списке одновременно.
Кроме того, что списки годятся для ситуации, когда происходят удаления и вставки элементов в середине, они также хороши для управления данными меняющегося размера, особенно когда доступ к ним происходит по принципу стека: последним вошел, первым вышел (last in, first out — LIFO). Они используют память эффективнее, чем массивы, при наличии нескольких стеков, которые независимо друг от друга растут и уменьшаются. Они также хороши в случае, когда информация внутренне связана в цепочку неизвестного заранее размера, например как последовательность слов в документе. Однако если вам нужны как частые обновления, так и случайный доступ к данным, то разумнее будет использовать не такую непреклонно линейную структуру данных, а что-нибудь вроде дерева или хэш-таблицы.
Упражнение 2-7
Реализуйте некоторые другие операции над списком: копирование, слияние, разделение списка, вставку до или после указанного элемента. Как эти две операции вставки отличаются по сложности? Много ли вы можете использовать из того, что мы написали, и много ли вам надо написать самому?
Упражнение 2-8
Напишите рекурсивную и итеративную версии процедуры reverse, переворачивающей список. Не создавайте новых элементов списка; используйте старые.
Упражнение 2-9
Напишите обобщенный тип List для языка С. Простейший способ — в каждом элементе списка хранить указатель void *, который ссылается на данные. Сделайте то же для C++, используя шаблон (template), и для Java, определив класс, содержащий списки типа Obj ect. Каковы сильные и слабые стороны этих языков с точки зрения данной задачи?
Упражнение 2-10
Придумайте и реализуйте набор тестов для проверки того, что написанные вами процедуры работы со списками корректны. Стратегии тестирования подробнее обсуждаются в главе 6.
Дерево — иерархическая структура данных, хранящая набор элементов. Каждый элемент имеет значение и может указывать на ноль или более других элементов. На каждый элемент указывает только один другой элемент. Единственным исключением является корень дерева, на который не указывает ни один элемент. Входящие в дерево элементы называются его вершинами.
Есть много типов деревьев, которые отражают сложные структуры, например деревья синтаксического разбора (parse trees), хранящие синтаксис предложения или программы, либо генеалогические деревья, описывающие родственные связи. Мы продемонстрируем основные принципы на деревьях двоичного поиска, в которых каждая вершина (node) имеет по две связи. Они наиболее просто реализуются и демонстрируют наиболее важные свойства деревьев. Вершина в двоичном дереве имеет значение и два указателя, left и right, которые показывают на его дочерние вершины. Эти указатели могут быть равны null, если у вершины меньше двух дочерних вершин. Структуру двоичного дерева поиска определяют значения в его вершинах: все дочерние вершины, расположенные левее данной, имеют меньшие значения, а все дочерние вершины правее — большие. Благодаря этому свойству мы можем использовать разновидность двоичного поиска для быстрого поиска значения по дереву или определения, что такого значения нет.
Вариант структуры Nameval для дерева пишется сразу:
typedef struct Namevai
Nameval; struct Nameval {
char *name;
int value;
Nameval *left; /* меньшие */
Nameval * right; /* большие */
};
Комментарии "большие" и "меньшие" относятся к свойствам связей: левые "дети" хранят меньшие значения, правые — большие.
В качестве конкретного примера на приведенном рисунке показано подмножество таблицы символов в виде дерева двоичного поиска для структур Nameval, отсортированных по ASCII-значениям имен символов.
Поскольку в каждой вершине дерева хранится несколько указателей на другие элементы, то многие операции, занимающие время порядка О(п) в списках или массивах, занимают только 0(log n) в деревьях. Наличие нескольких указателей в каждой вершине сокращает время выполнения операций, так как уменьшается количество вершин, которые необходимо посетить, чтобы добраться до нужной.
Дерево двоичного поиска (которое в данном параграфе мы будем называть просто "деревом") достраивается рекурсивным спуском по дереву; на каждом шаге спуска выбирается соответствующая правая или левая ветка, пока не найдется место для вставки новой вершины, которая должна быть корректно инициализированной структурой типа Nameval: имя, значение и два нулевых указателя. Новая вершина добавляется как лист дерева, то есть у него пока отсутствуют дочерние вершины.
/* insert: вставляет вершину
newp в дерево treep,
возвращает treep */
Nameval *insert(Nameval *treep,
Nameval *newp) {
int cmp;
if (treep == NULL)
return newp;
cmp = strcmp(newp->name,~treep->name);
if (cmp == 0)
weprintf("insert: дубликат значения
%s проигнорирован",
newp->name);
else if (cmp < 0)
treep->left = *insert(treep->left, newp);
else
treep->right = insert(treep->right, newp);
return treep; }
Мы ничего еще не сказали о дубликатах — повторах значений. Данная версия insert сообщает о попытке вставки в дерево дубликата (cmp == 0). Процедура вставки в список ничего не сообщала, поскольку для обнаружения дубликата надо было бы искать его по всему списку, в результате чего вставка происходила бы за время О(п), а не за 0(1). С деревьями, однако, эта проверка оставляется на произвол программиста, правда, свойства структуры данных не будут столь четко определены, если будут встречаться дубликаты. В других приложениях может оказаться необходимым допускать дубликаты или, наоборот, обязательно их игнорировать.
Процедура weprintf — это вариант eprintf; она печатает сообщение, начинающееся со слова warning (предупреждение), но, в отличие от eprintf, работу программы не завершает.
Дерево, в котором каждый путь от корня до любого листа имеет примерно одну и ту же длину, называется сбалансированным. Преимущество сбалансированного дерева в том, что поиск элемента в нем занимает время порядка 0(log n), поскольку, как и в двоичном поиске, на каждом шаге отбрасывается половина вариантов.
Если элементы вставляются в дерево в том же порядке, в каком они появляются, то дерево может оказаться несбалансированным или даже весьма плохо сбалансированным. Например, если элементы приходят уже в отсортированном виде, то код каждый раз будет спускаться на еще одну ветку дерева, создавая в результате список из правых ссылок, со всеми "прелестями" производительности списка. Если же элементы поступают в произвольном порядке, то описанная ситуация вряд ли произойдет и дерево будет более или менее сбалансированным.
Трудно реализовать деревья, которые гарантированно сбалансированы; это одна из причин существования большого числа различных видов деревьев. Мы просто обойдем данный вопрос стороной и будем считать, что входные данные достаточно случайны, чтобы дерево было достаточно сбалансированным.
Код для функции поиска похож на функцию insert:
/* lookup: поиск имени name
в дереве treep
*/ Nameval *lookup(Nameval *treep,
char *name) {
int cmp;
if (treep == NULL)
return NULL;
cmp = strcmp(name, treep->name);
if (cmp == 0)
return treep; else if (cmp < 0)
return lookup(treep->left, name); else
return lookup(treep->right, name); }
У нас есть еще пара замечаний по поводу функций lookup и i nse rt. Во-первых, они выглядят поразительно похожими на алгоритм двоичного поиска из начала главы. Это вовсе не случайно, так как они построены на той же идее "разделяй и властвуй", что и двоичный поиск, — основе логарифмических алгоритмов.
Во-вторых, эти процедуры рекурсивны. Если их переписать итеративно, то они будут похожи на двоичный поиск еще больше. На самом деле итеративная версия функции lookup может быть создана в результате элегантной трансформации рекурсивной версии. Если мы еще не нашли элемента, то последнее действие функции заключается в возврате результата, получающегося при вызове себя самой, такая ситуация называется хвостовой рекурсией (tail recursion). Эта конструкция может быть преобразована в итеративную форму, если подправить аргументы и стартовать функцию заново. Наиболее прямой метод — использовать оператор перехода goto, но цикл while выглядит чище:
/* nrlookup: нерекурсивный поиск имени
в дереве treep */ *Nameval
*nrlookup
(Nameval *treep, char *name)
int cmp;
while (treep != NULL) {
cmp = strcmp(name, treep->name);
if (cmp == 0)
return treep; else if (cmp < 0)
treep = treep->left; else
treep = treep->right; }
return NULL;
}
После того как мы научились перемещаться по дереву, остальные стандартные операции реализуются совершенно естественно. Мы можем использовать технологии управления списками, например написать общую процедуру обхода дерева, которая вызывает заданную функцию для каждой вершины. Однако в этом случае нужно сделать выбор: когда выполнять операцию над данной вершиной, а когда обрабатывать оставшееся дерево? Ответ зависит от того, что представляет собой дерево: если оно хранит упорядоченные данные, как в дереве двоичного поиска, то мы сначала посещаем левую часть, а затем уже правую.
Иногда структура дерева отражает какое-то внутреннее упорядочение данных, как в генеалогических деревьях, и порядок обхода листьев будет зависеть от отношений, которые дерево представляет.
Фланговый порядок (in-order) обхода выполняет операцию в данной вершине после просмотра ее левого поддерева и перед просмотром правого:
/* applyinorder: применение
функции fn во время
обхода дерева во фланговом порядке
*/ void applyinorder(Nameval *treep,
void (*fn)(Nameval*, void*), void *arg)
{
if (treep == NULL)
return;
applyinorder(treep->left, fn, arg);
(*fn)(treep, arg);
applyinorder(treep->right, fn, arg);
}
Эта последовательность действий используется, когда вершины должны обходиться в порядке сортировки, например для печати их по порядку, что можно сделать так:
applyinorder(treep, printnv, "%s: %x\n");
Сразу намечается вариант сортировки: вставляем элементы в дерево, выделяем память под массив соответствующего размера, а затем используем фланговый обход для последовательного размещения их в массиве. Восходящий порядок (post-order) обхода вызывает операцию для данной вершины после просмотра вершин-детей:
* applypostorder: применение
функции fn во время
обхода дерева в восходящем порядке
*/ void applypostorder(Nameval *treep,
void (*fn)(Nameval*, void*), void *arg) {
if (treep == NULL)
return;
applypostorder(treep->left, fn, arg);
applypostorder(treep->right, fn, arg);
(*fn)(treep, arg);
}
Восходящий порядок применяется, когда операция для вершины зависит от поддеревьев. Примерами служат вычисление высоты дерева (взять максимум из высот двух поддеревьев и добавить единицу), обработка дерева в графическом пакете (выделить место на странице для каждого поддерева и объединить их в области для данной вершины), а также вычисление общего занимаемого места.
Нисходящий порядок (pre-order) используется редко, так что мы не будем его рассматривать.
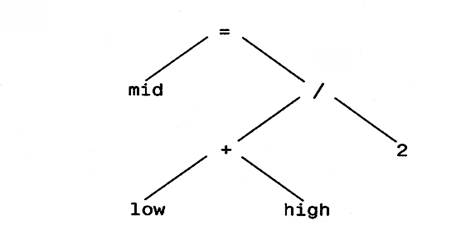
На самом деле деревья двоичного поиска применяются редко, хотя В-деревья, обычно сильно разветвленные, используются для хранения информации на внешних носителях. В каждодневном программировании деревья часто используются для представления структур действий и выражений. Например, действие mid = (low + high) / 2; может быть представлено в виде дерева синтаксического разбора (parse tree), показанного на рисунке ниже. Для вычисления значения дерева нужно обойти его в восходящем порядке и выполнить в каждой вершине соответствующее действие.
Упражнение 2-11
Сравните быстродействие lookup и nrlookup. Насколько рекурсия медленнее итеративной версии?
Упражнение 2-12
спользуйте фланговый обход для создания процедуры сортировки. Какова ее временная сложность? При каких условиях она может работать медленно? Как ее производительность соотносится с нашей процедурой quicksort и с библиотечной версией?
Упражнение 2-13
ридумайте и реализуйте набор тестов, удостоверяющих, что процедуры работы с деревьями корректны.