Ничто не сравнится с массивом, если нам нужно хранить статические табличные данные. Инициализация во время компиляции делает задачу конструирования таких массивов простой и легкой. В программе для распознания слов, слишком часто употребляемых в плохой прозе, мы можем написать:
char *flab[] = {
"actually",
"just",
"quite",
"really",
NULL
};
Функция поиска должна знать, сколько в массиве элементов. Один из способов сообщить ей это — передать длину массива в виде аргумента; второй способ, использованный здесь, — поместить в конце массива элемент-маркер NULL:
/* lookup: последовательный поиск слова в массиве */
int lookup(char *word, char *array[])
{
int i;
for (i = 0; array[i] != NULL; i++)
if (strcmp(word, array[i]) ==-
0) return i;
return -1;
}
В С и C++ для передачи в качестве параметра массив строк можно описать как char *array[] или char **array. Эти две формы эквивалентны, но в первой сразу видно, как будет использоваться параметр.
Предлагаемый поисковый алгоритм называется последовательным, поиском, потому что он просматривает по очереди все элементы, сравнивая их с искомым. Когда данных немного, последовательный поиск работает достаточно быстро. Есть стандартные библиотечные функции, которые выполняют последовательный поиск для определенных типов данных. Например, в языках С и C++ функции st rch г и st rst r ищут первое вхождение заданного символа или подстроки в строку, в Java у класса String есть метод indexOf, а обобщенные функции поиска в C++ find применимы к большинству типов данных. Если такая функция существует для нужного вам типа данных, то используйте ее.
Последовательный поиск достаточно прост, но время его работы прямо пропорционально количеству данных, которые нужно просмотреть; удвоение количества элементов приведет к удвоению времени на поиск, если искомого элемента в массиве нет. Это линейное соотношение (время выполнения является линейной функцией от размера данных), поэтому такой метод также называется линейным поиском.
Вот пример массива более реалистичного размера из программы, выполняющей синтаксический разбор текста, написанного на HTML, где определены имена более чем сотни отдельных символов:
typedef struct Nameval Nameval; struct Nameval {
char *name;
int value;
/* символы HTML, например AElig - лигатура1 А и Е.
*/ /* значения в кодировке
Unicode/18010646 */ Nameval htmlchars[] = {
"AElig", ОхООсб, /* лигатура А и Е
"Aacute", OxOOd, /* А с акцентом
"Acirc", OxOOc2, /* А с кружочком
/*...*/
"zeta", ОхОЗЬб, /* греческая дзета */
};
Для объемистого массива вроде этого более эффективно было бы использовать двоичный поиск. Алгоритм двоичного поиска является систематизированной версией поиска слова в словаре. Проверяем средний элемент. Если это значение больше, чем нужное, то ищем далее в первой части; в противном случае ищем во второй части. Повторяем до тех пор, пока не найдем нужный элемент или не убедимся, что его в массиве нет.
Для двоичного поиска таблица должна быть отсортирована, как в данном случае (в любом случае это полезно; люди тоже быстрее находят требуемое в отсортированных таблицах), а также должно быть известно, сколько элементов в таблице. Здесь может помочь макрофункция NELEMS из первой главы:
printf("Ta6лица HTML содержит %d слов\n", NELEMS(htmlchars));
Функция двоичного поиска для этой таблицы могла бы выглядеть так:
для определения индекса, под которым символ 1/2 (одна вторая) стоит в массиве htmlchars.
Двоичный поиск отбрасывает за каждый шаг половину данных, поэтому количество шагов пропорционально тому, сколько раз мы можем поделить п на 2, пока у нас не останется один элемент. Без учета округления это число равно Iog2 п. Если у нас в массиве 100"0 элементов, то линейный поиск займет до 1000 шагов, в то время как двоичный — только около 10; при миллионе элементов линейный поиск займет миллион шагов, а двоичный — 20. Очевидно, чем больше число элементов, тем больше преимущество двоичного поиска. Начиная с некоторого зависящего от реализации размера данных, двоичный поиск работает быстрее, чем линейный.
Двоичный поиск работает только в том случае, если элементы отсортированы. Если по одному и тому же набору данных планируется неоднократный повторный поиск, то выгоднее один раз отсортировать данные, а затем использовать двоичный поиск. Если набор данных известен заранее, то он может быть отсортирован при написании программы и проинициализирован во время компиляции. Иначе придется сортировать его во время выполнения программы.
Один из самых лучших алгоритмов сортировки — быстрая сортировка (quicksort), которая была придумана в 1960 году Чарльзом Хоаром (С. A. R. Ноаге). Быстрая сортировка — замечательный пример того, как можно избежать лишних вычислений. Она работает при помощи разделения массива на большие и маленькие элементы:
выбрать один элемент массива ("разделитель"):
разбить оставшиеся элементы на две группы:
"маленькие", то есть меньшие, чем разделитель,
"большие", то есть большие или равные разделителю,
рекурсивно отсортировать обе группы.
Когда этот процесс закончится, то массив будет отсортирован. Быстрая сортировка работает быстро, потому что, как только мы узнаем, что элемент меньше, чем разделитель, нам уже не нужно его сравнивать с большими элементами; аналогично, большие элементы не сравниваются с маленькими. Поэтому данный алгоритм существенно быстрее, чем такие простые методы сортировки, как сортировка вставкой или пузырьком, когда каждый элемент сравнивается напрямую со всеми остальными.
Алгоритм быстрой сортировки практичен и эффективен; он хорошо изучен, и существует множество его вариаций. Версия, которую мы здесь представим, является одной из самых простых реализаций, но, конечно, далеко не самой быстрой.
Наша функция quicksort сортирует массив целых чисел:
/* quicksort: сортирует v[0]..v[n-1]
по возрастанию */ void quicksоrtClrrt
v[], int n)
> {
int i, last;
if (n <= 1) /* ничего не делать */
return;
swap(v, 0, rand() % n); /* поместить
разделитель в v[0] */ last = 0;
for (i = 1; i < n; i++) /* разделить */
if (v[i] < v[0])
swap(v, ++last, i);
swap(v, 0, last); /* сохранить разделитель */
quicksort(v, last); /* рекурсивно
отсортировать */ quicksort(v+last+1, n-last-1);
/* каждую часть */ }
Операция swap, которая меняет местами два элемента, встречается в quicksort трижды, поэтому лучше всего вынести ее в отдельную функцию:
/* swap:
поменять местами v[i] и v[j] */
void swap(int v[], int i, int j)
{
int temp;
temp = v[i]; v[i] = v[j]; v[j] = temp;
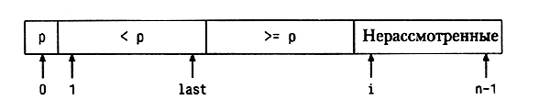
При разделении прежде всего случайным образом выбирается элемент-разделитель, который временно переставляется в начало массива, затем просматриваются остальные. Элементы, меньшие разделителя ("маленькие" элементы), перемещаются ближе к началу массива (на позицию last), а "большие" элементы — в сторону конца массива (на позицию i). В начале процесса, сразу после перемещения разделителя в начало, last = 0 и элементы с i = 1 по n-1 еще не исследованы:
В начале 1-й итерации элементы с первого по last строго меньше разделителя, элементы с last+1 no i-1 больше или равны разделителю, а элементы с i по п-1 еще не рассмотрены. Пока не выполнилось первый раз условие v[i] >='v[0], алгоритм будет переставлять элемент v[i] сам с собой; это, конечно, занимает дополнительное время, но не столь страшно.
Когда все элементы просмотрены, нулевой элемент переставляется на позицию last, чтобы разделитель занял свою окончательную позицию; тогда порядок элементов будет правильным. Теперь массив выглядит так:
Та же самая операция применяется к левой и правой частям массива; после окончания этого процесса весь массив будет отсортирован.
Насколько быстро работает быстрая сортировка? В наилучшем случае
первый проход делит массив из п элементов на две группы примерно по п/2 элементов;
второй проход разделяет две группы по п/2 элементов на 4 группы, в каждой из которых примерно по п/4 элементов;
на следующем проходе четыре группы по п/4 делятся на восемь групп по (примерно) п/8 элементов;
и т. д.
Данный процесс продолжается примерно Iog2 n раз, поэтому общее время работы в лучшем случае пропорционально п + 2 X и/2 + 4 х и/4 + + 8 X п/8 ... (Iog2 и слагаемых), что равно п log? п. В среднем алгоритм работает совсем не намного дольше. Обычно принято использовать именно двоичные логарифмы, поэтому мы можем сказать, что быстрая сортировка работает пропорционально n long.
Эта демонстрационная реализация быстрой сортировки наиболее прозрачна, но у нее есть одна слабина. Если каждый выбор разделителя разбивает массив на две примерно одинаковые группы, то наш анализ корректен, однако если разделение слишком часто происходит неровно, то время работы будет расти скорее как п1. В нашей реализации в качестве разделителя берется случайный элемент, чтобы уменьшить шанс того, что плохие входные данные приведут к слишком большому количеству неровных разбиений массива. Но если все входные значения одинаковы, то наша реализация за каждый проход будет отделять только один элемент, поэтому время работы будет расти как п2.
Поведение некоторых алгоритмов сильно зависит от входных данных. Неправильный или неудачный ввод может заставить в среднем хороший алгоритм работать крайне медленно или использовать огромное количество памяти. В случае быстрой сортировки, хотя простые реализации вроде нашей иногда могут работать медленно, более продуманные реализации способны уменьшить шанс патологического поведения почти до нуля.