Программа Queue_Test останавливается, когда будет достигнут определенный размер массива, используемого для хранения очереди.
В циклической очереди используется массив, в котором хранятся элементы очереди как циклический список, а не линейный.
Индексы сохранения qnext и извлечения qindex циклически возвращаются к началу массива (0). В такую очередь можно поместить любое количество элементов (если они не только помещаются, но и извлекаются из очереди).
Если qindex на 1 больше qnext - очередь заполнена и запись новых элементов невозможна, пока не будут прочитаны элементы, хранящиеся в очереди в данный момент. Если qindex=qnext - очередь пуста. В остальных случаях существует место для помещения по крайней мере еще одного элемента.
Программа создания циклической очереди на языке "Паскаль"
// FIFO First In - First Out Очередь
// Queue
Programm Queue_Test;
var
q:array[0..30] of Integer;
qnext,qindex,qlength:Integer;
procedure qstore(i:Integer);
begin
if (qnext+1)<>qlength then
begin
q[qnext]:=i;
qnext:=qnext+1;
if qnext=qlength then
qnext:=0 {Циклический переход}
end
else
writeln('Мест нет')
end;function qretrieve():Integer;
begin
if qindex=qlength then
qindex:=0; {Циклический переход}
if qindex=qnext then
begin
writeln('Очередь пуста');
qretrieve:=0;
end
else
begin
qretrieve:=q[qindex];
qindex:=qindex+1
end;
end;begin Содержимое очереди
qlength:=30;
qnext:=0;
qindex:=0;
qstore(1); 1
qstore(2); 1 2
qstore(3); 1 2 3
qretrieve(); {возвращает 1} 2 3
qstore(4); 2 3 4
qretrieve(); {возвращает 2} 3 4
qretrieve(); {возвращает 3} 4
qretrieve(); {возвращает 4} Очередь пуста
end.
Стек - разновидность очереди (а значит и разновидность списка), но с другим правилом доступа - L I F O (Last In and First Out - последним пришел и первым ушел). Ещё один термин (редко используемый) для обозначения этой структуры данных - магазин.
В стеке доступна единственная позиция - та, в которой находится последний введённый элемент - вершина. Иногда позицию, от которой стек начал заполняться данными, называют дном стека (хотя особого применения этот термин не имеет, поскольку дно стека, в котором содержится хотя бы один элемент данных, недоступно. Одно из немногих рациональных применений термина "дно" - признак пустого стека, когда дно и вершина совпадают).
Для стека, как и для очереди, характерны две операции - сохранение и извлечение, но применяются они к одной и той же позиции. Операция извлечения удаляет элемент из списка и уничтожает его содержимое. Произвольный доступ к элементам стека не допускается.
Области применения стеков такие же, как и у очередей:
Системные - передача процедурам и функциям аргументов по значению;
сохранение и восстановление содержимого регистров общего назначения процессора при вызове процедур (прологи и эпилоги функций).
Прикладные - стековая (магазинная) память, например в языке программирования Forth; вспомогательные структуры данных (например, при поиске в графе).
Примеры стеков. Второе название стека - магазин, - приводит к механическому примеру стека - магазин стрелкового оружия. Ещё один простой пример - стакан.
Стеки, также как и очереди, могут реализовываться при помощи одномерных массивов или связных списков.
Ниже приведёны примеры процедур занесения и извлечения данных для стека на основе массива на языках Паскаль и Си++.
Программа работы со стеком на языке Паскаль
Programm Stack_Test;
const
N=30;
var
stack:array[0..N] of char;
slen,pos:integer;
procedure push(i:char);
begin
if pos<slen then
begin
stack[pos]:=i;
pos:=pos+1
end
else
writeln('Стек полон.');
end;
function pop():char;
begin
if pos=0 then
begin
writeln('Стек пуст.');
pop:=0
end
else
begin
pos:=pos-1;
pop:=stack[pos]
end;
end;
Pos - индекс следующей открытой позиции - вершины стека. Если Pos больше индекса последнего сохранения, значит стек заполнен; если Pos=0 - стек пуст.
begin Содержимое стека
slen:=N;
pos:=0;
push('A'); A
push('B'); B A
push('C'); C B A
pop(); {Возвращает C} B A
push('D'); D B A
pop(); {Возвращает D} B A
pop(); {Возвращает B} A
pop(); {Возвращает A} Стек пуст
end.
Аналогичная программа на языке Си++
#include <iostream>
using namespace std;
const int N=30;
char stack[N];
int pos=0,slen=N;
// Занесение элемента в стек.
void Push(char i)
{
if(pos==slen)
{
cout<<"Стек полон!\n";
return;
}
stack[pos]=i;
pos++;
}
// Извлечение элемента из стека.
char Pop()
{
if(pos==0)
{
cout<<"Стек пуст.\n";
return 0;
}
pos--;
return stack[pos];
}
void main() Содержимое
{
Push(‘A’); A
Push(‘B’); B A
Push(‘C’); C B A
cout>>Pop()>>endl; // Возвр. C B A
Push(‘F’); F B A
cout>>Pop()>>'\n'; // Возвр. F B A
cout>>Pop()>>endl; // Возвр. B A
}
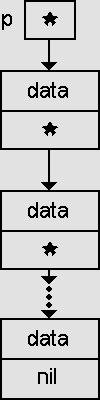
Представим стек, как динамическую цепочку звеньев, т.е. связный список. Первое звено - вершина. Так как доступна только вершина, то в таком списке главное звено становится излишним. Стек как единый объект представляет указатель, значение его - адрес вершины стека. Каждое звено цепочки содержит указатель на следующее звено, "дно" стека - элемент, занесенный первым, имеет этот указатель равным nil.
Программа работы с динамическим стеком на языке Паскаль
Programm Stack_Test;
Стек, как структура данных, задается набором типов.
type (* Секция описания типов *)
stype=real;
next=^elem;
elem=record (* Запись *)
dr:next;
data:stype
end;
stack=next;
var
p:stack;
procedure push(var st:stack; newl:stype);
var
q:next;
begin
new(q);
q^.data:=newl; (* новое звено *)
q^.dr:=st;
st:=q; (* новое звено - вершина *)
end;
Наличие у процедуры аргумента push(var st:stack, ... ) позволяет работать с несколькими стеками.
function pop(var st:stack):stype;
var
q:next;
begin
if st=nil then
writeln('Стек пуст.')
else
begin
pop:=st^.data;
q:=st;
st:=st^.dr;
dispose(q)
end;
end;
var P: stack;
Если стек пуст, то значение указателя P равно nil. К началу использования стека его нужно сделать пустым при помощи оператора p := nil;
begin
p := nil;
push(p,43);
writeln(pop(p):3:9);
push(p,54);
writeln(pop(p):3:9);
readln;
end.
Аналогичные процедуры на языке Си++
typedef float stype; /* Необязательное переименование типа float (может использоваться любой тип) в имя stype */
struct elem
{
elem* dr; // указатель на другой такой же элемент
stype data; // хранимые в стеке данные
};
void Push(elem*& st,stype newel)
{
elem* q=new elem;
q->data=newel; // Новое звено
q->dr=st;
st=q; // Новое звено становится вершиной стека.
}
stype Pop(elem*& st)
{
stype a;
elem *q;
if(st==NULL)
{
cout<<"Стек пуст.\n";
return;
}
a=st->data;
q=st;
st=st->dr;
delete q;
return a;
}
Понятие "списки" включает в себя самые разные структуры данных. Это могут быть и массивы, в том числе массивы записей, и специальные динамические структуры данных, и даже деревья. Общим для них является то, что они содержат набор записей одного вида, ограниченный по размеру или неограниченный, упорядоченный или неупорядоченный. Данные, хранящиеся в этих записях, обычно логически связаны между собой, например, фамилии студентов одной группы и т.п. В тексте программы такая связь может выражаться в том, что все такие элементы хранятся в одном и том же массиве как непрерывном блоке памяти. Но кроме общего имени массива (и адреса его начала) между этими элементами никакой другой физической связи нет, и на физическом уровне подобные списки могут быть названы "несвязными" (или, что (почти) то же самое, "несвязанными"). Т.е. внутри них нет связей (их элементы не связаны друг с другом физически).
Типичным примером несвязного (физически) списка является массив. В этой главе мы рассмотрим те самые "специальные динамические структуры данных", которые и получили название связных списков.
Вспомним общие черты очередей и стеков:
Строгие правила доступа к данным;
Операции извлечения (считывания) данных являются разрушающими.
Связные списки свободны от этих ограничений. Они допускают гибкие методы доступа; извлечение (чтение) элемента из списка не приводит к удалению его из списка и потере данных. Для фактического удаления элемента из связного списка требуется специальная процедура.
Связные списки представляют собой (как уже было сказано) динамические (фактически, линейные!) структуры данных (динамические цепочки звеньев), в которых однотипные элементы (звенья) каким-либо образом связаны между собой, обычно на физическом уровне. Связь между элементами можно осуществить за счёт хранения в одном элементе адреса другого такого же элемента (того же типа). Т.е. каждый информационный элемент содержит внутри себя указатель на собственный тип. Учитывая, что кроме этого указателя должны присутствовать полезные данные, тип информационного элемента оказывается записью. Например, для простейшего вида списка этот тип может быть следующим (на языках Си/Си++):
struct Link1
{
int data;
Link1* next;
};
Классификация связных списков. По числу связей (и одновременно, направлению) списки бывают односвязными (однонаправленными), двусвязными (двунаправленными) и многосвязными.
По способу организации связей (или по архитектуре) списки могут быть линейными и кольцевыми (циклическими). (Если список не является ни линейным, ни кольцевым, то остаётся единственный вариант - ветвящийся список, фактически являющийся одной из древовидных структур данных.)
По степени упорядоченности хранимых данных списки могут быть упорядоченными и неупорядоченными. Такое разделение иногда бывает удобно на практике, но для поддержания упорядоченности списков приходится прибегать к специальным мерам.
Для списков, по сравнению с очередями и стеками, имеется значительно больше операций, которые включают в себя:
- добавление нового звена списка (вставка звена);
- удаление звена;
- просмотр (или прохождение) списка;
- поиск данных в списке;
- создание ведущего (заглавного) звена (при необходимости);
- сортировка списка;
- обращение (реверсирование) списка, т.е. перестановка всех его звеньев в обратном порядке.
Рассмотрим основные из этих операций для каждого вида списка отдельно, вместе с особенностями этих видов списков.