Эта фаза в современной информатике выполняется компьютером и часто включает хранение данных с использованием внешней памяти. Вследствие принципа программного управления обработка информации осуществляется в соответствии с программой, предварительно размещенной в памяти компьютера.
3.1. Хранение информации
Хранение информации (данных) не является самостоятельной фазой в информационном процессе, а входит в состав фазы обработки. Однако, в силу важности организации хранения, данный материал вынесен в отдельный раздел.
Различают структурированные данные, в которых отражаются отдельные факты предметной области (это основная форма представления данных в СУБД), и неструктурированные, произвольные по форме, включающие и тексты, и графику, и прочие данные. Эта форма представления данных широко используется, например, в Интернет-технологиях, а сами данные предоставляются пользователю в виде отклика поисковыми системами.
Организация того или иного вида хранения данных (структурированных или неструктурированных) связана с обеспечением доступа к самим данным. Под доступом понимается возможность выделения элемента данных (или множества элементов) среди других элементов по каким-либо признакам с целью выполнения некоторых действий над элементом. При этом под элементом понимается как запись файла (в случае структурированных данных), так и сам файл (в случае неструктурированных данных).
Для данных любого вида доступ осуществляется с помощью специальных данных, которые называются ключевыми (ключами). Для структурированных данных такие ключи входят в состав записей файлов в качестве отдельных полей записей. Для неструктурированных поисковые слова или выражения входят, как правило, в искомый текст. С помощью ключей выполняется идентификация требуемых элементов в информационном массиве (массиве хранения данных).
Дальнейшее изложение фазы хранения информации относится к структурированным данным.
Модели структурированных данных и технологии их обработки основаны на одном из трех способов организации хранения данных: в виде линейного списка (или табличном),иерархическом (или древовидном), сетевом.
А) Линейные списки
Линейный список (далее – список) – это множество элементов хранения (далее – элементов) с заданным отношением строгого порядка, определяющим следование элементов в множестве. Требование строгого порядка вызвано тем, что с каждым элементом линейного списка при хранении связан конкретный физический адрес. Примером линейного списка может быть состав студентов учебной группы или расписание экзаменов во время сессии. В зависимости от места нахождения списка (внутренняя или внешняя память компьютера) он может быть организован как одномерный массив (в первом случае) или как файл (во втором случае). Тогда элементом списка может быть элемент массива или запись файла.
Элемент списка может иметь структуру. В таком случае он состоит из отдельных полей (это составляющие элемента). Например, элемент списка, соответствующего составу учебной группы, может состоять из следующих полей: фамилия, имя, отчество студента, номер зачетной книжки, домашний адрес:
Таблица 1
№ п/п
Фамилия
Имя
Отчество
Номер зачетной книжки
Домашний адрес
Строков
Иван
Иванович
ул. Красная, 9 - 2
Скворцов
Олег
Иванович
пр. Мира, 45 - 3
Соколов
Юрий
Кузьмич
ул. Леонова, 23 - 98
Поле, определяющее местонахождение элемента (или элементов) списка, называется ключевым полем, или попросту ключом. Ключ обычно используется для выполнения всех возможных действий над данными.
Ключ, определяющий только один элемент в списке, называется первичным. Ключ, определяющий несколько элементов, называется вторичным.
Если в качестве ключа выступает одно поле, такой ключ называется простым. Если используются несколько полей в качестве ключа, такой ключ называется составным.
Например, если в учебной группе нет однофамильцев (см. таблицу 1), в роли первичного ключа выступает фамилия студента (это одновременно и простой ключ), поскольку конкретная фамилия позволяет определить местонахождение элемента списка с остальной информацией по указанному студенту. Если есть однофамильцы, в роли первичного ключа может использоваться фамилия в совокупности с именем, а если и этого недостаточно, то еще и с отчеством (это пример составного ключа). Если же в группе есть полные тезки, то даже составной ключ не решит задачи. В этом случае надо искать другие поля (или вводить их искусственно) элемента для однозначной идентификации элемента в списке. Например, таким полем может быть номер зачетной книжки (см. таблицу 1).
В роли вторичного ключа может выступать имя студента, поскольку, как правило, в учебной группе найдется несколько студентов с одинаковыми именами (это пример простого вторичного ключа), или его отчество (как в нашем примере). Применение совокупности имени и отчества в качестве вторичного ключа также возможно – это пример составного вторичного ключа.
Различают два основных способа организации хранения элементов списка: в отсортированном и в неотсортированном виде. Причем возможна сортировка как по первичному, так и по вторичному ключу. Так, таблица 2 – это отсортированный по возрастанию первичного ключа (в данном случае – фамилии студента) исходный список из таблицы 1:
Таблица 2
№ п/п
Фамилия
Имя
Отчество
Номер зачетной книжки
Домашний адрес
Скворцов
Олег
Иванович
пр. Мира, 45 - 3
Соколов
Юрий
Кузьмич
ул. Леонова, 23 - 98
Строков
Иван
Иванович
ул. Красная, 9 - 2
Наиболее интересным с точки зрения практического использования линейного списка является вопрос организации доступа к его элементам. Как отмечалось ранее, доступ выполняется по запросу, в котором в обязательном порядке указывается ключ требуемого элемента (элементов). В роли ключа для структурированных данных выступает тройка <название поля><сравнение><значение поля>, где название поля – это указание на составляющую элемента, значение поля – это значение составляющей элемента. Например, Скворцов из таблицы 2, а сравнение означает некоторую операцию сравнения, например, «=» или «>».
Б) Иерархические структуры
Дерево (или иерархическая структура) – это конечное множество Т элементов, такое, что выполняются следующие условия:
1. имеется один специально выделенный элемент, называемый корнем дерева;
2. остальные элементы (кроме корня) содержатся в m ≥ 0 попарно не пересекающихся множествах Т1, ....Тm, каждое из которых в свою очередь является деревом. Деревья Т1, ....Тm являются поддеревьями данного дерева.
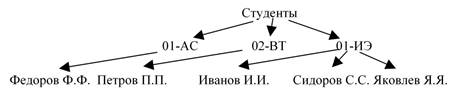
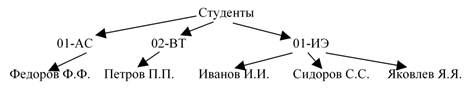
Пример дерева показан на рисунке 5:
Рисунок 5
Данное дерево представляет состав студентов, например, некоторого факультета, с указанием учебных групп, в которых они числятся. Формально, в соответствии с данным выше определением, в этом дереве можно выделить следующие компоненты:
1. исходное множество Т = {Студенты, 01-АС, 02-ВТ, 01-ИЭ, Федоров Ф.Ф., Петров П.П., Иванов И.И., Сидоров С.С., Яковлев Я.Я.};
2. в качестве корня выступает элемент Студенты;
3. непересекающиеся множества в составе:
· Т1 = {01-АС, Федоров Ф.Ф.};
· T2 = {02-ВТ, Петров П.П.};
· Т3 = {01-ИЭ, Иванов И.И., Сидоров С.С., Яковлев Я.Я.}.
Очевидно, множества Т1, Т2, Т3 также являются деревьями с корнями, соответственно, 01-АС, 02-ВТ, 01-ИЭ. В силу этого можно говорить о том, что данные деревья имеют в составе поддеревья:
Аналогичным образом, можно рассматривать вершины, соответствующие фамилиям и инициалам студентов, как вырожденные деревья, представленные только корнями. Для них выполняется условие, когда число непересекающихся подмножеств остальных элементов множества Т равно 0: m = 0.
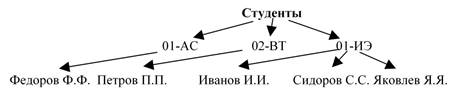
Таким образом, в дереве рисунка 5 можно выделить несколько деревьев (для лучшего понимания они выделены в отдельные рисунки, корни показаны полужирным шрифтом). Поскольку деревья выделялись последовательно, с каждым шагом выделения деревьев свяжем уровень, начиная с нулевого:
а) исходное дерево – нулевого уровня
б) поддеревья первого уровня
в) поддеревья второго уровня
Рисунок 6
По аналогии с терминологией линейных списков, можно интерпретировать шифры учебных групп (т.е. корни поддеревьев данного дерева) как вторичные ключи, определяющие множества элементов – студентов, числящихся в указанных группах. Фамилии и инициалы студентов можно рассматривать как первичные ключи.
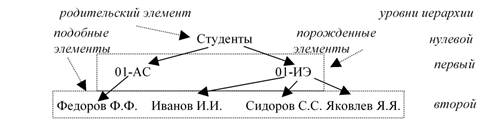
Дадим некоторые определения, которые понадобятся нам в дальнейшем:
1. уровень иерархии – показывает, на каком по счету шаге выделения дерева сформированы данные корни деревьев;
2. подобные элементы – элементы (вершины дерева), расположенные на одном уровне иерархии. Такие элементы, как правило, имеют одинаковую внутреннюю структуру;
3. порожденные элементы – элементы (вершины дерева), расположенные на следующем уровне иерархии;
4. родительские элементы – элементы (вершины дерева), расположенные на предыдущем уровне иерархии.
Введенные понятия прокомментированы на рисунке 7:
Рисунок 7
В) Сетевые структуры
Сеть (или сетевая структура) – это два множества Т и R, между которыми задано отображение Г: Т → R, где Т – множество элементов сети, R – множество бинарных отношений между ними, Г – отображение, показывающее, какие элементы какими отношениями связаны.
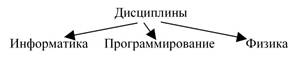
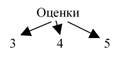
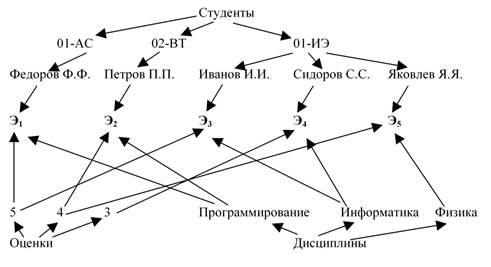
Нестрого сетевые структуры можно определить как несколько иерархических структур, соединенных вершинами максимального уровня иерархии. Например, данные по студентам можно представить совокупностью деревьев рисунков 9, 10 и 11:
Рисунок 9
Рисунок 10
Рисунок 11
Очевидно, все три дерева в совокупности не позволяют показать, какой студент какую оценку по какому экзамену получил, что не обеспечивает корректности отображения информации. Выполним объединение деревьев, введя дополнительный уровень служебных элементов, показывающий недостающую связь. Получим сеть рисунка 12 (служебные элементы обозначены Эi, i = {1,2,3,4,5}, и показаны полужирно):