Алгоритмы последовательного и двоичного поиска — это всего лишь два представителя из большого семейства алгоритмов, осуществляющих поисковый процесс. (Использование для этой цели индексов и механизм перемешивания будет далее рассматриваться.) Аналогично, сортировка методом вставки — это лишь один из многих существующих алгоритмов сортировки. Другими классическими алгоритмами являются сортировка слиянием), выборочная сортировка, сортировка методом пузырька, быстрая сортировка (применяющая к процессу сортировки принцип «разделяй и властвуй») и древовидная сортировка (использующая искусную методику для нахождения элементов, которые следует переместить вверх по списку).
Описание этих алгоритмов вы сможете найти в книгах, указанных в списке дополнительной литературы. Третий том книги Дональда Кнута «Искусство программирования», хотя и сложен для восприятия начинающими, в целом может считаться последним словом в области методик поиска и сортировки. В своем многотомном труде (который со временем может составить семь томов) Кнут собрал невероятное количество информации, относящейся к фундаментальным алгоритмам вычислений, и тем самым внес значительный вклад в библиотеки специалистов в области компьютерных наук и обработки данных.
Давайте вновь рассмотрим задачу поиска заданного элемента в отсортированном списке. Но на этот раз подойдем к этому несколько иначе. Попытаемся использовать процедуру, которой мы обычно следуем при поиске имени в телефонном справочнике. Человек никогда не просматривает справочник последовательно, элемент за элементом или даже страница за страницей. Мы просто открываем его примерно в том месте, где, как мы думаем, может находиться нужное имя. Если повезет, оно окажется именно там, в противном случае поиск придется продолжить. Однако в этой точке мы уже сузим область поиска либо до начальной части справочника, предшествующей нашей текущей позиции, либо до остальной части справочника, следующей за ней.
На рис. 1 этот подход, применяемый к произвольному отсортированному списку, описан с помощью псевдокода. В данном случае мы не знаем примерного места расположения элементов, поэтому инструкции на рисунке предписывают начинать работу с открытия списка на "среднем" элементе. Слово “средний”заключено в кавычки, поскольку вполне возможно, что число элементов в списке будет четным, и тогда среднего элемента в строгом смысле этого слова просто не существует. В этом случае условимся, что среднимсчитается первый элемент второй половины списка.
Рисунок 1 - Принцип двоичного поиска
Если выбранный элемент не является искомым, то программа, приведенная на рис. 1, предлагает два варианта дальнейших действий (поиск или в начальной или конечной половине списка). В каждом из них предусматривается выполнения вторичного поиска, осуществляемого процедурой с именем Search. Следовательно, чтобы завершить нашу программу, необходимо создать подобную процедуру, описывающую, как осуществляется этот вторичный поиск. Заметим, что эта процедура должна быть в состоянии удовлетворить запрос на поиск в пустом списке. Например, если показанной на рис.1 программе будет передан список, состоящий из одного элемента, который не является искомым, то процедура Search будет вызвана для поиска либо в подсписке, находящемся выше этого единственного значения, либо в подсписке, находящемся ниже его, однако оба эти списка пусты.
В качестве искомой процедуры Search можно было бы использовать процедуру последовательного поиска, созданную нами в предыдущем разделе, но это совсем не тот метод, который выбрал бы человек при поиске в телефонном справочнике. Вероятно, он просто применил бы к оставшейся части справочника тут же процедуру, которой только что воспользовался для всего справочника в целом. Другими словами, выбрал бы какой-то элемент, достаточно близкий к середине оставшейся части списка, и использовал его для дальнейшего сужения области поиска.
Подобный подход к процедуре поиска представлен на рис. 2. Здесь демонстрируется способ решения задачи, заключающейся в определении присутствия имени John в списке, приведенном в левой части рисунка. Прежде всего, анализируется средний элемент Harry. Так как имя, которое мы ищем, по алфавиту располагается после данного имени, поиск продолжается в нижней части исходного списка. Средним элементом этой части является имя Larry. Поскольку по алфавиту искомое имя предшествует данному, поиск следует продолжать в верхней части текущего подсписка. Обратившись к среднему элементу этого вторичного подсписка, обнаруживаем искомое имя John иобъявляем поиск успешным. Наша стратегия состоит в последовательном делении анализируемого списка на меньшие по размеру сегменты до тех пор, пока либо будет найдено искомое значение, либо поиск сузится до пустого сегмента.
Рисунок 2 - Применение стратегии двоичного поиска для обнаружения имени John в упорядоченном списке
Можно реализовать эту стратегию с помощью нашего псевдокода, модифицировав приведенную на рис. 1 программу так, чтобы учесть возможность получения пустого списка. Модифицированная соответствующим образом программа на псевдокоде, которой присвоено имя Search, показана на рис. 3. При выполнении этой процедуры и при достижении инструкции "Применить процедуру Search, чтобы ...", мы будем просто применять этот же метод поиска к меньшему списку, который является частью исходного списка. Если этот вторичный поиск завершится успешно, мы вернемся в исходную процедуру, чтобы объявить выполняемый в ней поиск успешным. Если же вторичный поиск окончится неудачей, мы объявим неудачным и исходный поиск.
Рисунок 3 - Алгоритм двоичного поиска, записанный на псевдокоде
Чтобы увидеть, как представленная на рис. 3 процедура выполняет свою задачу, попробуем с ее помощью определить, содержится ли значение Bill в списке имен Alice, Bill, Carol, David, Evelyn, Fred, George. Поиск начинается с выбора в качестве проверяемого элемента имени David (среднего элемента списка). Так как искомое значение (Bill) по алфавиту предшествует проверяемому, следует применить процедуру Search к списку элементов, предшествующих имени David, т.е. к списку Alice, Bill, Carol. Для этого нам потребуется создать вторую копию процедуры Search, предназначенную для решения данной промежуточной задачи.
Теперь мы имеем две выполняющиеся копии нашей процедуры поиска, как показано на рис.4. Дальнейшее выполнение исходной копии процедуры временно приостановлено на следующей инструкции:
Применить процедуру Search, чтобы определить, есть ли в части списка, предшествующей элементу <проверяемый_элемент>, элемент <искомое_значение>
Вторая копия процедуры используется для поиска имени Bill в списке Alice, Bill, Carol. Завершив вторую процедуру двоичного поиска, мы аннулируем ее копию и сообщим полученные в ней результаты исходной копии, после чего выполнение исходной копии будет продолжено с указанного места. Таким образом, вторая копия процедуры функционирует как подчиненная исходной, выполняя задачу, запрошенную исходной копией, а затем исчезая.
Вторичная процедура поиска выбирает имя Bill в качестве проверяемого значения, так как это средний элемент в списке Alice, Bill, Carol. Поскольку он совпадает с искомым значением, поиск объявляется успешным и вторичная процедура завершает свою работу. На этом этапе мы завершили дополнительный поиск, как предписывалось исходной процедурой, поэтому можно продолжить выполнение этой исходной копии, то есть объявить результат дополнительного поиска результатом первоначального поиска. В итоге выполнения всего процесса было совершенно справедливо установлено, что имя Bill присутствует в списке имен Alice, Bill, Carol, David, Evelyn, Fred, George.
Рисунок 4 - Вызов второй копии процедуры из ее исходной копии при поиске записи Bill
Теперь давайте посмотрим, что произойдет, если перед представленной на рис. 3 процедурой поставить задачу определить наличие в списке Alice, Carol, Evelyn, Fred, George элемента David. На этот раз исходная копия процедуры выбирает в качестве проверяемого значения имя Evelyn и определяет, что искомое значение должно находиться в предшествующей части списка. Поэтому она вызывает еще одну копию процедуры для поиска в списке тех элементов, которые стоят перед именем Evelyn, т.е. в двухэлементном списке, состоящем из имен Alice и Carol. Ситуация на этой стадии выполнения алгоритма представлен на рис. 5.
Вторая копия процедуры выберет в качестве проверяемого элемента имя Carol и определит, что искомое значение должно находиться после него. Процедура вызовет третью копию процедуры “Поиск” для поиска требуемого элемента в списке имен, следующих за именем Carol в списке Alice, Carol. Однако этот список пуст и перед третьей копией процедуры стоит задача поиска искомого значения David в пустом списке. Исходная копия процедуры осуществляет поиск требуемого элемента в списке Alice, Carol, Evelyn, Fred, George, выбрав в качестве проверяемого имя Evelyn; вторая копия процедуры занята поиском требуемого элемента в списке Alice, Carol, выбрав в качеству проверяемого элемент Carol; а третья начинает поиск в пустом списке.
Конечно же, третья копия процедуры тут же объявляет свой поиск неудачным и завершается. После этого вторая копия может продолжить свою работу. Она обнаруживает, что запрошенный поиск оказался неуспешным, поэтому также объявляет свой поиск неудачным и завершается. Исходная копия процедуры, ожидавшая поступления сообщения от второй копии, теперь может продолжить свою работу. Так как запрошенный поиск оказался неудачным, она тоже объявляет свой поиск неудачным, после чего завершается. Таким образом, наша программа пришла к правильному заключению, что имя David не содержится в списке имен Alice, Carol, Evelyn, Fred, George.
Рисунок 5 - Вызов второй копии процедуры из ее исходной копии при поиске записи David
Если еще раз просмотреть приведенные выше примеры, можно увидеть, что в процессе, осуществляемом представленным на рис. 3 алгоритмом, необходимо многократно разделять рассматриваемый список на две примерно равные части, после чего область дальнейшего поиска ограничивается лишь одной из этих частей. Именно это повторяющееся деление на два послужило причиной того, что данный алгоритм был назван двоичным поиском.


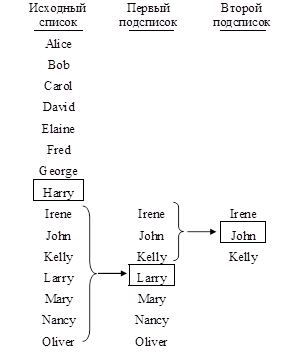
 Рисунок 3 - Алгоритм двоичного поиска, записанный на псевдокоде
Рисунок 3 - Алгоритм двоичного поиска, записанный на псевдокоде
