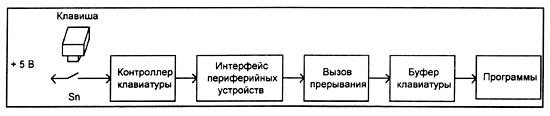
При нажатии любой клавиши контроллер клавиатуры (специализированный микропроцессор) вырабатывает два скан-кода, соответствующих позиции этой клавиши, которые передаются в компьютер. Первый скан-код вырабатывается, когда нажимается клавиша, а второй — при ее отпускании. Чтобы отличить второй скан-код, он предваряется посылкой байта со значением F0h.
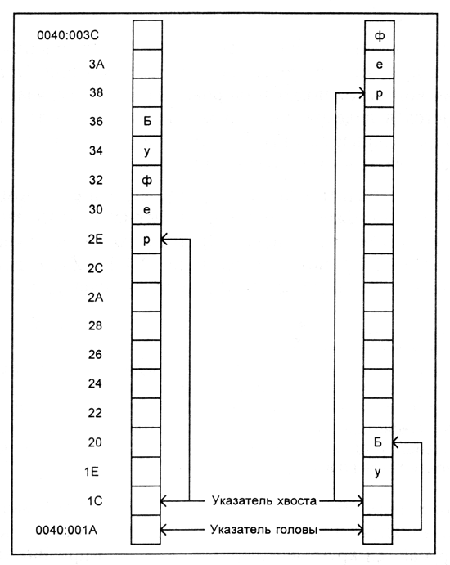
При получении байта от клавиатуры чипсет системной платы формирует сигнал аппаратного прерывания IRQ1. Появление такого прерывания однозначно требует от процессора начать выполнение подпрограммы BIOS, отвечающей за обработку сигналов клавиатуры. Если полученный байт является скан-кодом нажатой или отпущенной клавиши, то его значение будет записано в буфер клавиатуры, который занимает 32 байта и имеет начальный адрес 0040:001А. Служебные коды, которые может вырабатывать контроллер клавиатуры, передаются для обработки другим подпрограммам BIOS.
В буфере клавиатуры для кода клавиши отводится по 2 байта, т. е. он рассчитан на 16 символов. Чтобы можно было вводить неограниченное количество символов, буфер клавиатуры работает по принципу FIFO ("первым вошел -- первым ушел").
После того как скан-код клавиши помещен в буфер клавиатуры, его может прочитать любая программа однозадачной операционной системы, например MS-DOS. В многозадачной операционной системе Windows служебные подпрограммы отлеживают, чтобы символы от клавиатуры получала активная в момент ввода символа программа.
ASCII
ASCII (англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией.
ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. Изначально разработанная как 7-битная, с широким распространением 8-битного байта ASCII стала восприниматься как половина 8-битной. В компьютерах обычно используют расширения ASCII с задействованной второй половиной байта
Наложение символов
Благодаря символу BS (возврат на шаг) на принтере можно печатать один символ поверх другого. В ASCII было предусмотрено добавление таким образом диакритики к буквам, например:
a BS '→á
a BS `→à
a BS ^→â
o BS /→ø
c BS ,→ç
n BS ~ → ñ
Национальные варианты ASCII
Стандарт ISO 646 (ECMA-6) предусматривает возможность размещения национальных символов на месте @ [ \ ] ^ ` { | } ~. В дополнение к этому, на месте # может быть размещён £, а на месте $ — ¤. Такая система хорошо подходит для европейских языков, где нужны лишь несколько дополнительных символов. Вариант ASCII без национальных символов называется US-ASCII, или «International Reference Version».
Для некоторых языков с нелатинской письменностью (русского, греческого, арабского, иврита) существовали более радикальные модификации ASCII. Одним из вариантов был отказ от строчных латинских букв — на их месте размещались национальные символы (для русского и греческого — только заглавные буквы). Другой вариант — переключение между US-ASCII и национальным вариантом «на лету» с помощью символов SO (Shift Out) и SI (Shift In) — в этом случае в национальном варианте можно полностью устранить латинские буквы и занять всё пространство под свои символы. См. также КОИ-7.
Впоследствии оказалось удобнее использовать 8-битные кодировки (кодовые страницы), где нижнюю половину кодовой таблицы (0—127) занимают символы US-ASCII, а верхнюю (128—255) — дополнительные символы, включая набор национальных символов. Таким образом, верхняя половина таблицы ASCII до повсеместного внедрения Юникода активно использовалась для представления локализированных символов, букв местного языка. Отсутствие единого стандарта размещения кириллических символов в таблице ASCII доставляло множество проблем с кодировками (КОИ-8, Windows-1251 и другие). Другие языки с нелатинской письменностью тоже страдали из-за наличия нескольких разных кодировок.
В Юникоде первые 128 символов тоже совпадают с соответствующими символами US-ASCII.
Кодировка
.0
.1
.2
.3
.4
.5
.6
.7
.8
.9
.A
.B
.C
.D
.E
.F
0.
NUL
SOH
STX
ETX
EOT
ENQ
ACK
BEL
BS
TAB
LF
VT
FF
CR
SO
SI
1.
DLE
DC1
DC2
DC3
DC4
NAK
SYN
ETB
CAN
EM
SUB
ESC
FS
GS
RS
US
2.
!
"
#
$
%
&
'
(
)
*
+
,
—
.
/
3.
:
;
<
=
>
4.
@
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
5.
P
Q
R
S
T
U
V
W
X
Y
Z
[
\
]
^
_
6.
`
a
b
c
d
e
f
j
h
i
j
k
l
m
n
o
7.
p
q
r
s
t
u
v
w
x
y
z
{
|
}
~
DEL
Символ 0x5e в первой версии стандарта ASCII (1963) соответствовал стрелке вверх, а символ 0x5f — стрелке влево. Стандарт ECMA-6 (1965) заменил их на знак вставки (используемый также в роли циркумфлекса) и нижнюю черту (подчёркивание) соответственно.
Структурные свойства таблицы
Цифры 0—9 представляются своими двоичными значениями (например, 5=01012), перед которыми стоит 00112. Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева 00112 к каждому двоично-десятичному полубайту.
Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в 2-ичной системе счисления, перед которыми стоит 1002 (для букв верхнего регистра) или 1102 (для букв нижнего регистра).