Выборочная совокупность текста интересует лингвиста как математическая модель, с помощью которой он может оценить вероятностные характеристики всей генеральной совокупности и раскрыть закономерности нормы языка.
Переход от статистической модели выборки текста к вероятностным характеристикам норм языка связан с решением трёх задач:
- по характеристикам 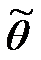 вариационного ряда необходимо численно оценить скрытые от прямого наблюдения параметры
вариационного ряда необходимо численно оценить скрытые от прямого наблюдения параметры 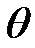 соответствующего распределения генеральной совокупности, то есть параметры, выступающие в качестве вероятностных характеристик нормы языка и его разновидностей;
соответствующего распределения генеральной совокупности, то есть параметры, выступающие в качестве вероятностных характеристик нормы языка и его разновидностей;
- по данным вариационного ряда следует оценить характер генерального распределения;
- имея в своём распоряжении 1 и 2 необходимо решить важнейшую технологическую задачу лингвистического исследования, состоящую в определении того, какой объём исследуемого текста даст достаточно надёжные лингвистические результаты. [Пиотровский, 1977, с 266]
