При решении многих задач требуется установить и оценить зависимость между переменными величинами, которые могут быть и случайными.
Закономерности:
1. Случайные величины могут быть связаны строгой функциональной зависимостью.
2. Зависимое переменное Y может быть случайной величиной, даже если переменные таковыми не являются, поскольку значение Y определяется не только значениями , которые исследователь выделил, но и многими другими неучтенными факторами, а также ошибками измерений. Это означает, что связь
( - случайная составляющая), является не функциональной, а стохастической. Изменения переменных влияет на значение переменного Y через изменение закона распределения случайной величины Y.
Если же изменение приводит к изменению среднего значения Y( ), то связь называется корреляционной.
3. Некоторые переменные могут иметь количественный характер, а некоторые качественный.
4. Нас может интересовать либо зависимость переменных , либо взаимозависимость между переменными (не обязательно между всеми).
Перечисленные особенности приводят к различным постановкам задач статистического исследования зависимостей, которые можно упрощенно классифицировать следующем образом:
· задачи корреляционного анализа – задачи исследования наличия взаимосвязей между отдельными группами переменных;
· задачи регрессионного анализа- задачи, связанные с проверкой гипотезы о наличие приближенной количественной зависимости между переменной Y и одним или несколькими переменными , которые носят количественный характер.
· задачи дисперсионного анализа - это задачи, в которых переменные носят качественный или именованный характер, а исследуется и устанавливается степень их влияния на переменное Y.
§ 2. Элементы теории корреляции. Анализ парных связей.
Рассмотрим задачу о выборке показателя стохастической связи между двумя случайными величинами X и Y.
Пусть система имеет двумерный нормальный закон распределения.
Условная плотность распределения случайной величины Y при условии что , обозначается ,
также является плотностью нормального распределения с параметрами:
- условное математическое ожидание;
- условная дисперсия;
При значение X=x, которые связаны с параметрами исходного распределения следующим образом:
;
.
В этом случае линия регрессии является прямой, а условная дисперсия не зависит от х.
Если закон распределения системы случайных величин (Х , Y) отличен от нормального, то характер изменения условного математического ожидания может быть и нелинейным.
Эта функция называется функцией регрессии.
Рассмотрим отклонение возможных значений случайной величины Y от её среднего значения .
(1) (2)
(1)- отклонение функции регрессии в точке х от математического ожидания .
(2)- отклонение возможного значения y, от значения функции регрессии в точке х.
Можно доказать, что рассеяние случайной величины Y относительно её математическое ожидание есть сумма двух слагаемых:
(1)
Из этого равенства следует, что связь между Y и X тем теснее, чем больше вклад в дисперсию вносит слагаемое .
В качестве такой характеристики принимается отношение ( )называемое корреляционным отношением переменной :
(2)
Из равенства (2) следует, что .
Если , т.е , это означает, что X и Y связанны функциональной зависимостью.
Если , то линия регрессии - горизонтальная прямая , т.е условное математическое ожидание не меняется в зависимости от Х.
Аналогично определяется и корреляционное отношение переменного Х по переменному Y.
Замечание.
Для выяснения степени тесноты связи необходимо рассматривать оба корреляционных отношения и .
Раннее мы рассмотрели, что связь между величинами можно измерить с помощью линейного коэффициента корреляции.
или
Для системы нормально распределенных случайных величин
справедливо следующее равенство:
(3)
В общем случае показатели и связаны неравенствами:
(4)
При этом возможны следующие варианты:
· , если переменные Х и Y независимы, но обратное (в общем случае) неверно;
· ,тогда и только тогда, если у Х и Y имеется строгая линейная зависимость.
· , когда имеется строгая нелинейная функциональная зависимость Y от Х.
· , когда регрессия строго линейна, но нет функциональной зависимости.
· указывает на то, что нет строгой функциональной зависимости, а некоторая нелинейная кривая регрессия приближает зависимость лучше, чем любая прямая линия.
В качестве показателя стохастической связи между двумя случайными количественными переменными Х и Y следует выбрать корреляционное отношение или , если закон распределения системы двухмерной случайной величины (Х , Y) неизвестен.
Если же есть основание считать, что система (Х,Y) имеет нормальный закон распределения, то вместо корреляционного отношения следует использовать коэффициент корреляции.
§ 3. Оценка показателя связи по выборочным данным. Корреляционное поле.
После выбора показателя стохастической связи задача корреляционного анализа состоит в нахождении его оценки(точечнойи интервальной), а также в проверке статистической гипотезыо значимом отличии его от нуля на основе экспериментальных данных.
Пусть в результате эксперимента для системы (X,Y) получена выборка значений .
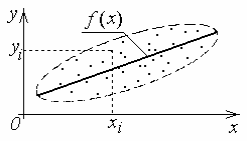
При изучении корреляционной зависимости двух случайных величин (X,Y) по выборкеобщую картину их взаимной изменчивости можно получить, изобразив на координатной плоскости все точки. Это изображение называют корреляционным полем.
(1)
Уже по виду корреляционного поля часто можно сделать вывод о наличии и характере связи между случайными величинами Y и X. Так на рисунке (1) выборочные точки лежат внутри некоторого эллипса (эллипса рассеяния) с осями, параллельными координатным. Следовательно, с изменением, например, X величина Y не будет менять своего условного распределения, т.е. Х и Y , по-видимому, некоррелированы.
(2)
На рисунке (2) видно, что условное математическое ожидание имеет линейный характер изменения, и значит, следует ожидать, что коэффициент корреляции близок к единице.
(3)
На рисунке (3) расположение точек говорит о наличии нелинейного характера изменения и, следовательно, коэффициент корреляции может оказаться близким к нулю, а корреляционное отношение – близким к единице.
§ 4. Анализ коэффициента корреляции.
4.1 Точечная оценка коэффициента корреляции.
Пусть экспериментальные данные представлены в не сгруппированном виде. Тогда в качестве точечной оценки коэффициента корреляции берут его выборочное значение :
4.2 Интервальная оценка коэффициента корреляции и проверка значимости.
При построении доверительного интерваладля коэффициента корреляции и проверки его значимости будем предполагать, что генеральная совокупностьимеет двумерный нормальный закон распределения. В этом случае оценка коэффициента корреляции имеет асимптотически нормальный закон распределения с математическим ожиданием
и дисперсией .
Используя общий метод построения доверительного интервала, основанный на нормальном законе распределения соответствующей оценки при доверительной вероятностиγ=1−α, можно получить следующие значения для нижней и верхней границ интервальной оценки:
Где:
- точечная оценка коэффициента корреляции;
- квантиль стандартного нормального распределения уровня .
Этими оценками можно пользоваться при достаточно больших объемах выборки (не менее 500). При малых объемах выборки можно использовать построение доверительного интервала для , основанное на преобразовании Р.Фишера:
Или
.
Оказывается, что случайная величина уже при небольших значениях приблизительно распределена по нормальному закону с параметрами
, .
Это приводит к представлению
, .
где:
,
.
При проверке статистической гипотезы (т.е. гипотезы о том, что нормально распределенные случайные величины X и Y независимы) используют критерий:
;
Эта случайная величина имеет распределение Стьюдента с n-2 степенями свободы. Если окажется, что
При рассмотрении многомерных случайных величин рассматривались условные законы распределения и их числовые характеристики: математическое ожидание, дисперсия и различные моменты. Оценками этих величин служат их выборочные аналоги. Наиболее важными являются условные математические ожидания, вычисленные по выборке – условные средние.
Условное среднее – среднее арифметическое значений случайной величины Y, наблюдавшихся при фиксированном значении случайной величины X= x.
Условное среднее – среднее арифметическое значений случайной величины X, наблюдавшихся при фиксированном значении случайной величины Y = y.
Напомним определение уравнения регрессии:
условное математическое ожидание является функцией x.
Эта функция f (x)называется функцией регрессииY на X, а ее график – линией регрессии.
Выборочный аналог этого уравнения, , называется выборочным уравнением регрессииY на X, функция – выборочной функцией регрессииY на X, ее график – выборочной линией регрессииY на X.
Аналогично определяются выборочные характеристики и для регрессии X на Y.
§ 6. Корреляционная таблица. Выборочные линии регрессии.
Пусть в результате эксперимента для системы (Х,Y) получена выборка значений .
Если значения х и y повторяются, то их группируют
Здесь и – наблюдаемые значения X и Y, а – частота появления пары значений .
Чаще всего в этом случае данные организуют в виде корреляционной таблицы:
X
Y
…
…
…
…
…
….
….
…
…
Группируя данные по значениям или :
по данным корреляционной таблицы можно составить законы распределения составляющих (последняя строка и последний столбец таблицы) и их средние по выборки и .
и .
Для наглядности данные таблицы изображают графически. Каждую пару (xi,yj)изображают точкой в системе координат (ХОY). Частоту , с которой данная пара встречается в таблице, изображают соответствующим числом близко расположенных точек либо пишут число возле одной точки. Построенное таким образом в системе координат изображение корреляционной таблицы называют полем корреляции. Также возможно изображать данные таблицы кругами, центр которых находится в точке (xi,yj), а диаметр (или площадь) пропорционален .
Точка в системе координат (ХОY) с координатами называется центром рассеивания.
Можно также составить условные законы распределения, например Y при Х= или Х при Y= .
….
…..
Зная условные законы распределения, можно найти условные средние:
и т.п. Построим в системе координат (ХОY) точки
и соединим их отрезками прямых. Полученную ломаную называют
выборочной линией регрессии Y на X.
Если распределения случайных величин X и (или) Y заданы интервальнымвариационным рядом, то удобно перейти к вспомогательным переменным, значения которых совпадают с серединами интервалов.
Кроме того, если варианты(значения вариационного ряда) являются равноотстоящими, т.е., образуют арифметическую прогрессию с разностью h, бывает удобно перейти к условным вариантам:
,
где C ложный нуль(новое начало отсчета),
h – шаг,т.е. разность между двумя соседними первоначальными вариантами (новая единица масштаба).
Если в качестве ложного нуля взята какая-то из вариант , то условные варианты- целые числа, что упрощает вычисления
Так как объем выборки конечен, то о линии регрессии можно судить лишь по форме опытной линии регрессии. Задача о нахождении теоретической линии регрессии сводится к выравниванию статистических распределений, например, методом наименьших квадратов.

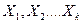 таковыми не являются, поскольку значение Y определяется не только значениями
таковыми не являются, поскольку значение Y определяется не только значениями 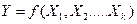

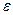 - случайная составляющая), является не функциональной, а стохастической. Изменения переменных
- случайная составляющая), является не функциональной, а стохастической. Изменения переменных 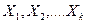 влияет на значение переменного Y через изменение закона распределения случайной величины Y.
влияет на значение переменного Y через изменение закона распределения случайной величины Y.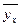 ), то связь называется корреляционной.
), то связь называется корреляционной. имеет двумерный нормальный закон распределения.
имеет двумерный нормальный закон распределения. , обозначается
, обозначается 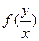 ,
,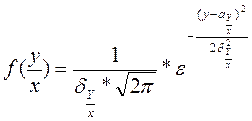
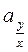 - условное математическое ожидание;
- условное математическое ожидание;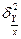 - условная дисперсия;
- условная дисперсия;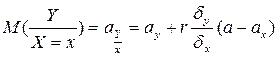 ;
;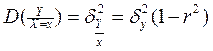 .
.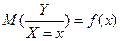 может быть и нелинейным.
может быть и нелинейным. .
.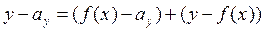
 .
.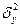 случайной величины Y относительно её математическое ожидание есть сумма двух слагаемых:
случайной величины Y относительно её математическое ожидание есть сумма двух слагаемых:
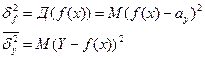
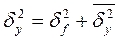 (1)
(1)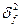 .
.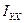 )называемое корреляционным отношением переменной
)называемое корреляционным отношением переменной 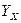 :
: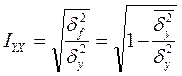 (2)
(2)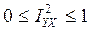 .
.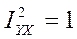 , т.е
, т.е 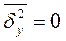 , это означает, что X и Y связанны функциональной зависимостью.
, это означает, что X и Y связанны функциональной зависимостью. , то линия регрессии - горизонтальная прямая , т.е условное математическое ожидание не меняется в зависимости от Х.
, то линия регрессии - горизонтальная прямая , т.е условное математическое ожидание не меняется в зависимости от Х. переменного Х по переменному Y.
переменного Х по переменному Y.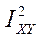 и
и  .
.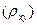 или
или 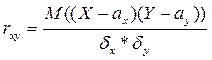
 справедливо следующее равенство:
справедливо следующее равенство: (3)
(3)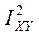 и
и 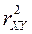 связаны неравенствами:
связаны неравенствами: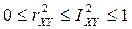 (4)
(4)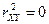 , если переменные Х и Y независимы, но обратное (в общем случае) неверно;
, если переменные Х и Y независимы, но обратное (в общем случае) неверно;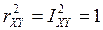 ,тогда и только тогда, если у Х и Y имеется строгая линейная зависимость.
,тогда и только тогда, если у Х и Y имеется строгая линейная зависимость.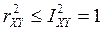 , когда имеется строгая нелинейная функциональная зависимость Y от Х.
, когда имеется строгая нелинейная функциональная зависимость Y от Х.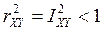 , когда регрессия
, когда регрессия 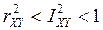 указывает на то, что нет строгой функциональной зависимости, а некоторая нелинейная кривая регрессия приближает зависимость лучше, чем любая прямая линия.
указывает на то, что нет строгой функциональной зависимости, а некоторая нелинейная кривая регрессия приближает зависимость лучше, чем любая прямая линия.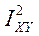 или
или  , если закон распределения системы двухмерной случайной величины (Х , Y) неизвестен.
, если закон распределения системы двухмерной случайной величины (Х , Y) неизвестен.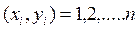 .
.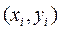 общую картину их взаимной изменчивости можно получить, изобразив на координатной плоскости все точки. Это изображение называют корреляционным полем.
общую картину их взаимной изменчивости можно получить, изобразив на координатной плоскости все точки. Это изображение называют корреляционным полем. (1)
(1) (2)
(2)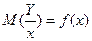 имеет линейный характер изменения, и значит, следует ожидать, что коэффициент корреляции
имеет линейный характер изменения, и значит, следует ожидать, что коэффициент корреляции 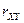 близок к единице.
близок к единице.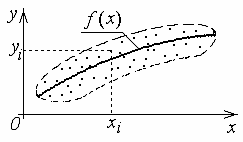 (3)
(3) говорит о наличии нелинейного характера изменения
говорит о наличии нелинейного характера изменения  и, следовательно, коэффициент корреляции может оказаться близким к нулю, а корреляционное отношение
и, следовательно, коэффициент корреляции может оказаться близким к нулю, а корреляционное отношение 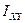 – близким к единице.
– близким к единице.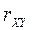 берут его выборочное значение
берут его выборочное значение 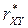 :
: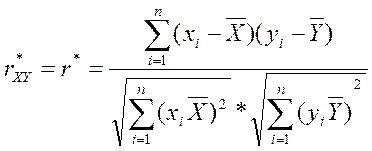
 и дисперсией
и дисперсией 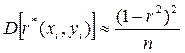 .
.
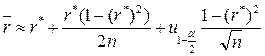

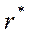 - точечная оценка коэффициента корреляции;
- точечная оценка коэффициента корреляции;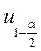 - квантиль стандартного нормального распределения уровня
- квантиль стандартного нормального распределения уровня 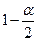 .
.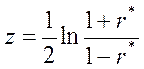
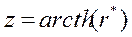 .
.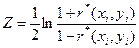 уже при небольших значениях приблизительно распределена по нормальному закону с параметрами
уже при небольших значениях приблизительно распределена по нормальному закону с параметрами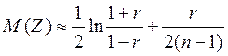 ,
,  .
.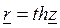 ,
, 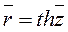 .
. ,
,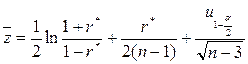 .
.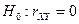 (т.е. гипотезы о том, что нормально распределенные случайные величины X и Y независимы) используют критерий:
(т.е. гипотезы о том, что нормально распределенные случайные величины X и Y независимы) используют критерий: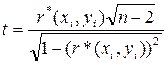 ;
;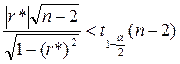
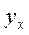 – среднее арифметическое значений случайной величины Y, наблюдавшихся при фиксированном значении случайной величины X= x.
– среднее арифметическое значений случайной величины Y, наблюдавшихся при фиксированном значении случайной величины X= x.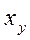 – среднее арифметическое значений случайной величины X, наблюдавшихся при фиксированном значении случайной величины Y = y.
– среднее арифметическое значений случайной величины X, наблюдавшихся при фиксированном значении случайной величины Y = y. является функцией x.
является функцией x.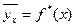 , называется выборочным уравнением регрессииY на X, функция
, называется выборочным уравнением регрессииY на X, функция  – выборочной функцией регрессииY на X, ее график – выборочной линией регрессииY на X.
– выборочной функцией регрессииY на X, ее график – выборочной линией регрессииY на X. .
.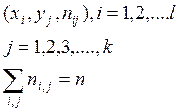
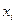 и
и 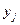 – наблюдаемые значения X и Y, а
– наблюдаемые значения X и Y, а 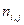 – частота появления пары значений
– частота появления пары значений 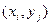 .
.
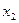
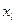
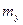
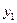


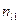


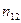
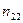
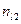


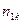

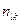

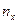
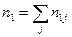
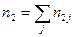
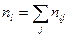
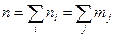
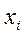 или
или 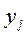 :
: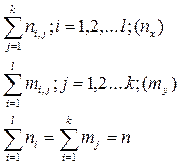
 и
и  .
.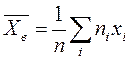 и
и 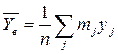 .
.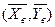 называется центром рассеивания.
называется центром рассеивания.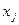 или Х при Y=
или Х при Y= 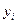 .
.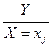

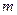
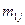


 и т.п. Построим в системе координат (ХОY) точки
и т.п. Построим в системе координат (ХОY) точки и соединим их отрезками прямых. Полученную ломаную называют
и соединим их отрезками прямых. Полученную ломаную называют ,
,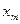 , то условные варианты- целые числа, что упрощает вычисления
, то условные варианты- целые числа, что упрощает вычисления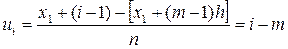
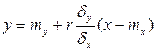 - прямая среднеквадратической регрессии Y на X,
- прямая среднеквадратической регрессии Y на X,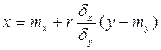 - прямая среднеквадратической регрессии X на Y.
- прямая среднеквадратической регрессии X на Y.