Поиск данных по ключу в форматированных файлах и таблицах.Поле форматированного файла или таблицы называется ключевым илиключом, если значения его являются уникальными, т.е. не повторяются и не могут повторяться. Если ключевых полей несколько, то один из них объявляется какпервичный ключ.
В некоторых случаях полей, значения которых заведомо не повторяются, может и не быть. Тогда в качестве ключа используют несколько полей сразу - составной ключ. Хотя с теоретической точки зрения, разницы между составными и простыми ключами нет, на практике использовать составной ключ труднее. Иногда создают ключ искусственно. Такой ключ принимает целочисленные значения и называетсясчётчик.
Для нахождения записи по заданному значению ключевого поля будем перебирать записи одну за другой, сравнивая значения ключей с заданным. Если записи с указанным ключом не существует, придётся перебрать все записи, прежде чем факт отсутствия будет обнаружен. Если запись присутствует, то число операций до её обнаружения будет случайной величиной v и можно вычислять различные её характеристики (среднее , дисперсию и т.д.).
Рассмотрим наиболее простую задачу: вычисление среднего числа операций до нахождения требуемой записи - . Пусть искомая запись находится с равной вероятностью на любом месте в файле. Тогда вероятность найти нужную запись на i-ом месте будет равна 1/N, где N - число записей в файле. Среднее значение числа операций сравнения, необходимых для нахождения записи, будет составлять
Среднее время поиска будет пропорционально средней длине файла, при поиске имеющейся в файле записи, и будет пропорционально длине файла при её отсутствии. Поскольку длина файла обычно велика, время поиска будет чрезмерно долгим. Для ускорения поиска предлагаются различные методы. Все они связаны с определённой структуризацией файла.
Самый простой способ такой структуризации - упорядочение записей файла по возрастанию ключа. В этом случае время поиска имеющейся записи не изменится, но время поиска несуществующей записи в среднем уменьшится в два раза.
Следующий по сложности метод ускорения поиска заключается в разбиении файла на секции равной длины и создание справочника секций, в который мы включаем ключи записей старшие в каждой секции.
Сначала ищем в справочнике и находим требуемую секцию. Затем просматриваем указанную секцию. Предположим, нам нужно найти запись с ключом 38. Просматривая справочник, установим, что запись находится во второй секции. Обращаясь ко второй секции, найдём саму запись.
Время поиска в справочнике пропорционально величине m/2, где m - есть длина справочника, т.е. число секций. Время поиска в секции составит величину, пропорциональную половине длины секции, т.е. N/2m. Общее время поиска определим из формулы m/2 + N/2m.
Заменим дискретную величину m на непрерывно - меняющуюся величину х. Получим функцию f(x)=х/2+N/2*x. Найдём минимум этой функции. Для этого найдём её производную: f’(x)=1/2-N/2*x2. Теперь приравняем производную нулю и найдём корень получившегося уравнения. Это будет . Кроме того, заметим, что f(0) = , и функция непрерывна при 0<x< . Следовательно, исследуемая функция имеет единственный минимум в точке хо.
Таким образом, в качестве оптимальной длины сегмента следует выбрать длину, близкую к величине корня квадратного из длины файла. Например, если файл состоит из 10000 записей, то следует выбрать 100 секций по 100 записей в каждой. Тогда среднее время поиска будет пропорционально величине 100, что существенно меньше, чем при последовательном просмотре (5000).
Если справочник слишком большой, можно разбить на секции и его, создавая, таким образом, мастер-справочник. В этом случае поиск будет трёхступенчатым.
Наиболее эффективендихотомический метод поиска.Вэтом случае файл должен быть помещён полностью в ОП, что можно сделать не во всех случаях. При поиске мы разбиваем файл на две равные части и сравниваем заданное значение ключа с старшим ключом первой половины или младшим ключом второй половины файла. Этим путём, мы можем определить: в какой половине нужно продолжить поиск.
После каждого сравнения длина зоны поиска уменьшается в два раза. Поиск закончится не позднее, чем зона неопределённости станет равной 1. Это случится на k-м шагу, где N/2k<1, т.е. k>log2(N). Таким образом, число сравнений не превосходит min{k: k>log2(N)}. Такой поиск называется логарифмическим. Для N = 10000 будем иметь log(10000) = 4*log(10)<16, что много меньше, чем в предыдущих случаях.
Обычно файл не статичен, постоянно подвергается изменениям — добавлениям новых записей, удалением и изменениям старых записей. Дополнительные требования к структуре файла, например, упорядоченность его записей, должны быть при этом сохранены. Это усложняет процедуры обновления файла.
Упорядоченность файла по поисковому полю, даёт значительный выигрыш при групповом поиске, т.е. при поиске по группе заданных ключей. Если упорядочить все эти ключи, то время поиска всех требуемых записей не будет превосходить длины файла, вне зависимости от числа требований.
Поиск по неключевым полям.Все способы эффективного поиска в файле основываются на упорядочивании файла по значениям поля. Отсортировать файл сразу по нескольким полям одновременно нельзя. Поэтому эффективный поиск по вторичным полям непосредственно в файле невозможен. Для поиска по вторичным полям создаются справочники, содержащие значения поля поиска и ссылки на те записи файла, соответствующее поле которых принимает указанные значения.
Файл, имеющий подобные справочники, называетсяиндексированным, а поле, по которому происходит индексирование, называетсяиндексом.
Справочники позволяют значительно ускорить поиск нужных записей. В тоже время поддержка файла (добавление новых записей, удаление и изменение имеющихся записей) становится более трудоёмкой. Это связано с необходимостью корректировать не только сам файл, но и его справочники.
Поиск по нескольким полям. Очень часто необходимо искать записи одновременно по значениям нескольких полей.
При построении теории поиска сначала определяютэлементарные запросы. Элементарным запросом называют предложение вида: <имя поля> = <допустимое значение поля>. Поисковый запрос, использующий это предложение, является простым. Он подразумевает нахождение тех записей, которые имеют соответствующее значение указанного поля.
Сложные запросы образуются из элементарных с помощью логических связок «И» и «ИЛИ» (часто используются их английские эквиваленты «AND» и «OR») и круглых скобок.
С формальной точки зрения, считается, что элементарные запросы есть функции, определённые на множестве значений данного поля и принимающие два значения: ИСТИНА и ЛОЖЬ. Логические связки имеют два аргумента и являются двухместной функцией. Эти, функции задаются следующей таблицей:
1 аргумент
2 аргумент
И
ИЛИ
ЛОЖЬ
ЛОЖЬ
ЛОЖЬ
ЛОЖЬ
ИСТИНА
ЛОЖЬ
ЛОЖЬ
ИСТИНА
ЛОЖЬ
ИСТИНА
ЛОЖЬ
ИСТИНА
ИСТИНА
ИСТИНА
ИСТИНА
ИСТИНА
Таким образом, запрос представляется как логическая функция, определённая на множестве записей. Если функция на данной записи принимает значение ИСТИНА, то эта запись соответствует запросу, а в противном случае не соответствует.
Кроме указанных двуместных функций, часто используется одноместная функция НЕ, смысл которой очевиден. Строго говоря, существуют всего 24 = 16 двуместных логических функций и 22 = 4 одноместных, но они используются редко.
Довольно часто требуется не вся запись, а только часть её полей. В этом случае требуемые поля указывают явно перед запросом.
Полученный в результате обработки запроса список можно использовать для повторного поиска в том же или другом файле. Для этого вводится конструкция <имя поля> в (in) <список>.
Поиск в неструктурированных данных.Далеко не все данные могут быть структурированы настолько, чтобы их можно было записывать в виде форматированного файла. Государственные законы, статьи газет и журналов, исторические хроники - примеры таких данных. Для их поиска предлагается выделять в каждом тексте набор ключевых слов, характеризующих данный текст. Затем составляются (автоматически) словари, в которых записываются ключевые слова с указателями на тот документ, в котором они ключевые.
Здесь возникают проблема выбора ключевых слов. Удобнее всего выбирать ключевые слова автору. Однако при этом нет никакой гарантии, что список слов не будет постоянно расти и обновляться за счёт появления слов, мало известных читателям. Для создания комфортных условий поиска требуется использовать некоторый фиксированный набор общеупотребительных терминов. Это условие практически не всегда выполнимо.
Поскольку авторы выделяют ключевые слова далеко не всегда, созданы программы автоматического формирования ключевых слов данного документа. Первые опыты такого рода основывались на частотном анализе текстов и брались наиболее часто встречающиеся слова. Эту идею пришлось оставить. В настоящее время здесь применяются более изощрённые способы, использующие терминологические словари и т.п.
Поиск по ключевым полям обычно проходит в несколько этапов. Первый запрос может оказаться неудачным, поскольку ему соответствует (релевантно) слишком много текстов или не соответствует ни одного. В первом случае нужно указать дополнительные условия поиска, а во втором - ослабить исходные требования. Вариация поисковых запросов требует определённых навыков.
Принципы классификации. Иногда приходится совершать поиск в объединение произвольных объектов: книг, минералов, животных, растений, профессий и т.п. Для организации эффективного поиска в подобных совокупностях применяют классификацию объектов поиска.
Существует два типа классификации: фасетный и иерархический.
Для создания фасетной классификации требуется выделить набор свойств, которые в совокупности характеризовали бы объекты поиска с достаточной полнотой. Полнота характеристики определяется ролью объектов, которые они играют в культуре: общечеловеческой или профессиональной.
Характеризуя компьютеры, мы укажем следующие общеупотребительные характеристики: быстродействие; объём оперативной памяти; объём жёсткого диска; тип процессора, и др.
Добавим к сказанному, что для, эффективного поиска, обычно требуют, чтобы множество значений выделяемых признаков было конечным.
Для классификации подобных объектов предлагается иерархический метод классификации. Применяя этот метод, мы разбиваем классифицируемую совокупность объектов на классы первого уровня, затем классы первого уровня разбиваем на классы второго уровня и т.д. При каждом разбиении используем определённый признак, набор признаков или принцип. Шведский учёный XIX века Карл Линей предложил эффективные, иерархические классификации для животных, растений и минералов. Аналогичные системы классификации создавались для книг (УДК, ББК). То обстоятельство, что таких методов несколько, должно настораживать. Наличие нескольких конкурирующих способов говорит об их несовершенстве.
Принцип библиотечной классификации достаточно прост и связан с классификацией знаний. Мы делим все книги по отраслям знаний: математика, физика, экономика, юриспруденция, медицина и т.д. Математику делим по более мелким разделам - направлениям: алгебра, геометрия, анализ, логика, основы математики и история развития. Дальнейшее разделение соответствует устоявшемуся делению в математике. Алгебру делим на линейную алгебру, теорию групп, колец, алгебр, полей и т.п.
Однако это деление несовершенно, поскольку при попытке применить эту достаточно простую и прозрачную схему возникают проблемы отнесения книг к тому или иному разделу. Типичным примером могла бы послужить книга «Информационные системы в экономике». Неясно - отнести ли её к экономике (что и делается практически) или к информационным системам. При традиционном подходе все книги по; применению информационных систем останутся вне поля зрения специалистов по информации.
Причина возникновения трудности классификации связана с различием между методом и областью его использования. Имеются и другие трудности классификации книг. Чтобы их преодолеть вводятся различные добавочные и уточняющие правила, которыми и различаются разные системы книжной классификации. Классификация становится столь сложной, что возникает потребность в специалистах по библиотечной классификации. Действует специальный государственный орган надзора за классификацией книг - «Книжная палата».
Другой государственный орган классификации - «Комитет по стандартизации» занимается классификацией профессий, населённых пунктов, предприятий, изделий производства и т.п.
Для поиска объектов одной классификации недостаточно. Для этого вводится кодирование объектов, основанное на классификации. Кодирование - важная идея информационных технологий.
Конечное множество попарно различных символов назовём алфавитом.
Алфавит может содержать специальные символы - разделители, а может их не содержать. Соответственно можно говорить об алфавитах с разделителями и без разделителей. Последовательность символов алфавита, не содержащую разделителей, назовём словом.
Язык - это любое множество слов. Русский или английский языки называются естественными языками. Человеческая память способна вмещать огромное количество слов своего родного и иноземных языков. Существуютформальные языки. Слова формального языка формируют с помощью конечной последовательности определённых правил (алгоритмов). Формальные языки играют важную роль в информатике.
Текст - это последовательность слов. Для разделения слов используются разделители, если они есть в алфавите. Если алфавит не содержит разделителей, прибегают к особым приёмам разделения слов в тексте.
Самым простым является использование слов фиксированной длины. Более сложным способом разделения является ис-
пользование описателей текста. Этот метод может быть эффективным, если все фразы языка имеют одинаковую структуру. Наконец, можно использовать так называемое свойство префиксности. Это свойство будет рассмотрено позднее, при изучении алгоритмов сжатия текста, где оно находит применение.
При техническом применении формальные языки часто называют кодами. Слова такого языка называюткодослово.Множество кодослов (язык) -код. Кодирование - взаимно однозначное отображение множества объектов в код. При кодировании каждому объекту ставится в соответствие одно и только одно кодослово.
При кодировании объектов, множество которых классифицируется с помощью фасетного метода, поступают просто. Каждому множеству всевозможных значений отдельного признака - фасета, ставится в однозначное соответствие множество слов фиксированной длины над некоторым алфавитом. Для этого составляем словарь: значение признака - кодослово. Чтобы обеспечить однозначность соответствия необходимо, чтобы число значений данного признака было не больше, чем число кодослов.
Если число символов алфавита обозначим n, а длину слов m, то число кодослов фиксированной длины m составит nm, Следовательно, мы должны выбрать длину m такой, чтобы величина nm превосходила число значений соответствующего признака.
После того, как множества значений каждого признака будут кодированы, сопоставим объекту набор кодослов, где каждое кодослово представляет значение некоторого признака-фасета.
Для однозначного выделения слов их текста при этом достаточно задать длины всех кодослов(сигнатуру кода):m1, m2, ..., mr, где r - число признаков фасет.
При иерархической классификации метод кодирования аналогичен. Однако длины кодослов для, объектов могут иметь различную длину, поскольку число уровней иерархии может быть для них различно.
Измерение количества информации. Информационная ёмкость любого конечногомножестваполагается равной двоичному логарифму от числа элементов этого множества. При этом информационная ёмкость множества, состоящего из двух элементов, принимается за единицу измерения ёмкости и называетсябит.
Это определение связано с задачей кодирования элементов данного множества. Такое кодирование необходимо для представления элементов множества в памяти компьютера или при передаче информации о них по линиям связи.
Как было ранее установлено, множество Е может быть закодировано с помощью двоичных кодослов фиксированной длины, если длина кодослов n удовлетворяет неравенству т.е. . Естественно в целях экономии записи при кодировании использовать минимальную длину кодосло-ва, т.е. . Хотя эта граница не всегда достижима, можно показать, что существует способ приблизиться к ней как угодно близко.
Всё сказанное позволяет рассматриватьинформационную ёмкость множества как минимальную длину кодослов, требуемых для кодирования этого множества.
Информационная ёмкость показателя, который принимает конечное число значений, полагается равной информационной ёмкости множества его значений.
Информационная ёмкость показателя равна минимальной длине двоичной последовательности, необходимой для правильного представления в памяти компьютера значений этого показателя.
Для практического вычисления информационной ёмкости, вспомним, что любое целое число представимо в виде произведения простых чисел. Второй важный для нас математический факт - логарифм произведения равен сумме логарифмов сомножителей. Следовательно, для вычисления значения логарифма достаточно представить данное нам целое число как произведение простых его делителей и представить логарифм от него как сумму логарифмов простых чисел. Теперь достаточно воспользоваться таблицей логарифмов от простых чисел. Например, log20=21og2+log5=2+log5.
Показатели могут быть информационно зависимыми или независимыми. Показатели зависимы, если от значения одного из них зависит диапазон изменения другого показателя.
Очевидно, что суммарная информационная ёмкость зависимых показателей меньше, чем независимых. Для оценки информационной ёмкости зависимых показателей введём понятие«условная информационная ёмкость».
Пусть x1 и x2 два зависимых показателя. Обозначим ni число значений, которые принимает показатель х2 при условии, что x1=i. В приведённом выше примере n1 = 11, n2 = 16, n3 = 21. Условную информационную ёмкость показателя x2, при условии, что x1 = i, положим равной log(ni). В качестве оценки информационной ёмкости показателя х2 можно взять среднеарифметическое условных значений , где m число значений первого показателя.
Заметим, что безусловную информационную ёмкость показателя x2 можно определить как log(n), где n общее число значений этого показателя. В указанном выше примере безусловная информационная ёмкость равна log(31).
Можно обосновать, используя выпуклость логарифма, что средняя ёмкость не превосходит безусловную.
Документ можно рассматривать как совокупность показателей, входящих в него. Например, накладная на поступивший товар содержит такие показатели, как номер накладной, название поставщика, наименование товара, единицы его измерения, количество. Информационной ёмкостью документа назовём двоичный логарифм от числа всевозможных значений, которые могут принимать показатели.
Практическое вычисление информационной ёмкости документа может быть затруднено. Можно оценить эту величину большей величиной, равной сумме информационных ёмкостей всех его показателей.
Зная информационную ёмкость потока документов, поступающего в компьютер, мы можем определить объём памяти, который необходимо выделить для их размещения. Мы можем определить также время, необходимое для пересылки соответствующих данных по каналам связи.

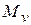 , дисперсию
, дисперсию 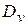 и т.д.).
и т.д.).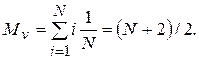
 . Кроме того, заметим, что f(0) =
. Кроме того, заметим, что f(0) =  , и функция
, и функция 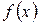 непрерывна при 0<x<
непрерывна при 0<x<  т.е.
т.е. 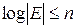 . Естественно в целях экономии записи при кодировании использовать минимальную длину кодосло-ва, т.е.
. Естественно в целях экономии записи при кодировании использовать минимальную длину кодосло-ва, т.е. 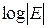 . Хотя эта граница не всегда достижима, можно показать, что существует способ приблизиться к ней как угодно близко.
. Хотя эта граница не всегда достижима, можно показать, что существует способ приблизиться к ней как угодно близко.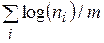 , где m число значений первого показателя.
, где m число значений первого показателя.