Распределенные базы данных - это базы данных, содержимое которых располагается в нескольких абонентских системах информационной сети . Они управляются с помощью программных средств Системы Управления Распределенной Базой Данных (СУРБД) . Задачей СУРБД является обеспечение функционирования распределенной базы данных . СУРБД должна действовать так, чтобы у пользователей возникла иллюзия того, что они работают с Базой Данных (БД) , расположенной в одной абонентской системе. Использование СУРБД , по сравнению с группой невзаимосвязанных баз данных, позволяет сокращать затраты на передачу данных в информационной сети . СУРБД так распределяет файлы по сети, что в каждой системе хранятся те данные , которые чаще всего используются именно в этом месте. В СУРБД осуществляется тиражирование данных . Его сущность заключается в том, что изменение, вносимое в одну часть базы данных, в течение определенного времени отражается и в других частях базы.
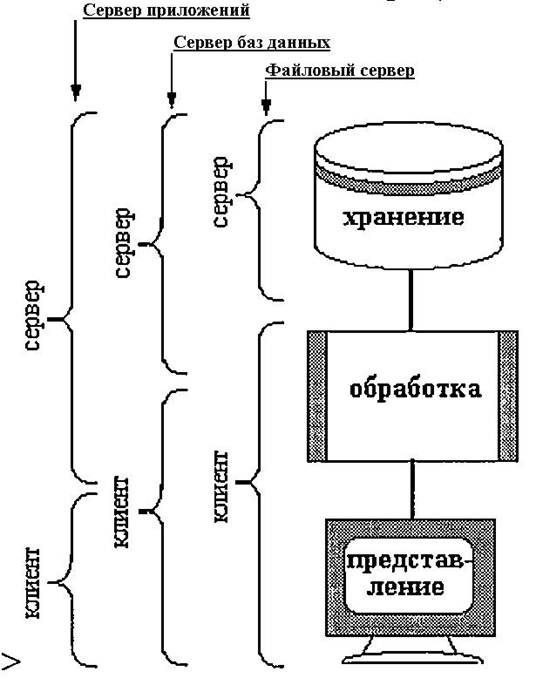
При планировании обработки данных могут рассматриваться три модели: · обработка в одноранговой локальной сети; · централизованная обработка; · обработка в модели клиент/сервер. При любой обработке имеются три основных уровня манипулирования данными: · хранение данных; · выполнение приложений, т.е. выборка и обработка данных для нужд прикладной задачи; · представление данных и результатов обработки конечному пользователю. При обработке в одноранговой сети все три уровня, как правило, выполняются на одном - персональном - рабочем месте. В современных технологиях применения вычислительной техники персональная обработка информации, когда все данные и средства их обработки сосредоточены в пределах одного рабочего места, и обмен данными между рабочими местами не происходит или выполняется эпизодически (например, средствами электронной почты), постепенно уходит в прошлое. Современные информационные, управленческие, офисные системы в большей или меньшей степени ориентируются на многопользовательскую обработку, при которой данные доступны (возможно, одновременно доступны) многим пользователям с разных рабочих мест. Соображения эффективности и надежности требуют централизации процессов хранения и обработки данных. И централизованная обработка, и модель клиент/сервер в равной мере используют преимущества централизации. Различие между этими двумя моделями состоит в том, что при централизованной обработке представление информации конечному пользователю также выполняется средствами центральной вычислительной системы - на ее терминалах (неинтеллектуальных), подключенных к вычислительной системе через порты/каналы ввода-вывода. В модели же клиент/сервер терминалы, представляющие информацию, являются интеллектуальными - самостоятельными вычислительными системами (обычно персональными компьютерами) и связаны с сервером через сетевые средства. Хотя централизованная обработка обеспечивает большую эффективность в сопровождении системы и в скорости обмена, предпочтительной все же представляется модель клиент/сервер, к числу достоинств которой следует отнести прежде всего гибкость - возможность строить клиентские рабочие места на разных платформах и в разных операционных средах и, таким образом, гибко приспосабливать возможности интеллектуального терминала к стоящим перед данным рабочим местом задачам. При перемещении большей части функций манипулирования данными на высокопроизводительный и высоконадежный сервер могут быть обеспечены следующие преимущества: · экономия вычислительных ресурсов всей системы в целом; · экономия ресурсов средств коммуникаций; · обеспечение работы всех пользователей с одной и той же копией данных; · предотвращение фатальных конфликтов между клиентами при обращении их к одним и тем же данным; · обеспечение надежного администрирования базы данных, в т.ч. резервного копирования и разграничения доступа к данным. Распределение функций манипулирования данными между клиентом и сервером может быть различным, как показано на рисунке 1. Вариант файлового сервера предполагает, что сервер выполняет только хранение данных. При необходимости вся единица хранения данных (файл) пересылается клиенту, и всю дальнейшую работу с данными (в том числе и выборку) выполняет клиент. Этот вариант требует значительных ресурсов как вычислительных (так как на каждом рабочем месте должна размещаться копия обрабатываемых данных и все средства их обработки), так и коммуникационных (так как по сети передаются файлы целиком). Кроме того, этот вариант либо ограничивает одновременный доступ клиентов блокировкой файлов, либо приводит к неидентичности копий информации у разных клиентов. В предельном случае вариант файлового сервера сводится к персональной обработке данных, пусть и в среде локальной сети.
Рис. 1.
Вариант сервера базы данных предполагает, что на сервер возлагается выполнение одной из самых трудоемких функций логики приложения - выборки из базы данных только тех записей, которые необходимы для решения конкретной задачи. В этом случае экономятся ресурсы вычислительной системы и обеспечивается действительно многопользовательский доступ. Вместе с тем, в зависимости от сложности оставшейся части логики приложения, объем клиентской части ресурсов может все еще оставаться достаточно большим. Вариант сервера базы данных особенно эффективен в системах со специализированными рабочими местами, так как позволяет подобрать аппаратные и операционные среды рабочих мест в наиболее точном соответствии с решаемыми задачами. Вариант сервера приложений предполагает, что вся или почти вся логика приложений выполняется на сервере, а в клиентскую часть передаются лишь результаты обработки. Клиентская часть, таким образом, ответственна только за представление результатов конечному пользователю. Такой вариант предъявляет повышенные требования к ресурсам сервера, но объемы ресурсов клиентов могут быть минимальны. Такой вариант позволяет также легко организовать гетерогенную систему, в которой разные клиенты будут работать в разных операционных средах, так как объем программного обеспечения, который нужно переписать, чтобы адаптировать клиента к новой среде, относительно невелик - это только часть, зависимая от средств визуализации на данном рабочем месте. В предельном случае модель сервера приложений, однако, сводится к централизованной обработке.