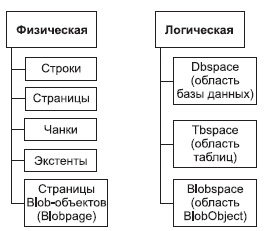
Рис. 5.7. Логическая и физическая схемы структуризации дискового пространства
Методы управления физической моделью БД
Для ускорения обработки данных разработчики СУБД реализуют свои способы построения физической модели. Для каждой СУБД способы построения физических моделей однозначно определено и пользователь СУБД не имеет возможности влиять на способ построения физической модели. Физическая организация современных баз данных является, в большинстве случаев, коммерческой тайной для большинства поставщиков коммерческих СУБД. Не существует никаких стандартов, поэтому в общем случае каждый поставщик создает свою уникальную структуру и пытается обосновать ее наилучшие качества по сравнению со своими конкурентами. Физическая организация является в настоящий момент наиболее динамичной частью СУБД.
К физической модели предъявляются следующие требования:
· высокая скорость доступа к данным;
· простота обновления данных.
· небольшой объем дополнительно используемой (вторичной) памяти.
При распределении дискового пространства рассматриваются (рис. 5.7) две схемы структуризации: физическая, которая определяет хранимые данные, и логическая, которая определяет некоторые логические структуры, связанные с концептуальной моделью данных
Чанк (chank) – представляет собой часть диска, физическое пространство на диске, которое ассоциировано одному процессу (online процессу обработки данных).
Чанком может быть назначено неструктурированное устройство, часть этого устройства, блочно-ориентированное устройство или просто файл UNIX.
Чанк характеризуется маршрутным именем, смещением (от физического начала устройства до начальной точки на устройстве, которая используется как чанк), размером, заданным в Кбайтах или Мбайтах.
При использовании блочных устройств и файлов величина смещения считается равной нулю.
Логические единицы образуются совокупностью экстентов, то есть таблица моделируется совокупностью экстентов.
Экстент –это непрерывная область дисковой памяти.
Для моделирования каждой таблицы используется 2 типа экстентов: первый и последующие.
Первый экстент задается при создании нового объекта типа таблица, его размер задается при создании. EXTENTSIZE – размер первого экстента, NEXT SIZE — размер каждого следующего экстента.
Минимальный размер экстента в каждой системе свой, но в большинстве случаев он равен 4 страницам, максимальный – 2 Гбайтам.
Новый экстент создается после заполнения предыдущего и связывается с ним специальной ссылкой, которая располагается на последней странице экстента. В ряде систем экстенты называются сегментами, но фактически эти понятия эквиваленты.
При динамическом заполнении БД данными применяется специальный механизм адаптивного определения размера экстентов. Внутри экстента идет учет свободных станиц. Между экстентами, которые располагаются друг за другом без промежутков, производится своеобразная операция конкатенации, которая просто увеличивает размер первого экстента. При этом используется механизм удвоения размера экстента:если число выделяемых экстентов для процесса растет в пропорции, кратной 16, то размер экстента удваивается каждые 16 экстентов.
Например, если размер текущего экстента 16 Кбайт, то после заполнения 16 экстентов данного размера размер следующего будет увеличен до 32 Кбайт.
Экстенты состоят из четырех типов страниц: страницы данных, страницы индексов, битовые страницы и страницы blob-объектов. Blob –это сокращение Binary Larg Object, и соответствует оно неструктурированным данным. В ранних СУБД такие данные относились к типу Mcodeo. В современных СУБД к этому типу относятся неструктурированные большие текстовые данные, картинки, просто наборы машинных кодов. Для СУБД важно знать, что этот объект надо хранить целиком, что размеры этих объектов от записи к записи могут резко отличаться и этот размер в общем случае неограничен.
Основной единицей осуществления операций обмена (ввода-вывода) является страница данных. Все данные хранятся постранично. При табличном хранении данные на одной странице являются однородными, то есть станица может хранить только данные или только индексы.
Все страницы данных имеют одинаковую (рис. 5.8) структуру.
Слот – это 4-байтовое слово, 2 байта соответствуют смещению строки на странице и 2 байта — длина строки. Слоты характеризуют размещение строк данных на странице. На одной странице хранится не более 255 строк. В базе данных каждая строка имеет уникальный идентификатор в рамках всей базы данных, часто называемый RowID — номер строки, он имеет размер 4 байта и состоит из номера страницы и номера строки на странице. Под номер страницы отводится 3 байта, поэтому при такой идентификации возможна адресация к 16 777 215 страницам.
При упорядочении строк на страницах не происходит физического перемещения строк, все манипуляции происходят со слотами. При переполнении страниц создается специальный вид страниц, называемых страницами остатка. Строки, не уместившиеся на основной странице, связываются (линкуются) со своим продолжением на страницах остатка с помощью ссылок-указателей "вперед" (то есть на продолжение), которые содержат номер страницы и номер слота на странице.
Страницы индексов организованы в виде B-деревьев. Страницы blob предназначены для хранения слабоструктурированной информации, содержащей тексты большого объема, графическую информацию, двоичные коды. Эти данные рассматриваются как потоки байтов произвольного размера, в страницах данных делаются ссылки на эти страницы.
Битовые страницы служат для трассировки других типов страниц. В зависимости от трассируемых страниц битовые страницы строятся по 2-битовой или 4-битовой схеме. 4-битовые страницы служат для хранения сведений о столбцах типа Varchar, Byte, Text, для остальных типов данных используются 2-битовые страницы.
Битовая структура трассирует 32 страницы. Каждая битовая структура представлена двумя 4-байтными словами. Каждая i-я позиция описывает одну i-ю страницу. Сочетание разрядов в i-х позициях двух слов обозначает состояние данной страницы: ее тип и занятость.
При обработке данных СУБД организует специальные структуры в оперативной памяти, называемые разделяемой памятью, и специальные структуры во внешней памяти, называемые журналами транзакций. Разделяемая память служит для кэширования данных при работе с внешней памятью с целью сокращения времени доступа, кроме того, разделяемая память служит для эффективной поддержки режимов одновременной параллельной работы пользователей с базой данных.
Как правило, СУБД располагает своими собственными буферами оперативной памяти ЭВМ для ускорения процессов работы с данными.
Выделяют три основных режима работы приложений, связанных с использованием баз данных.
Режим 1. Получить все данные (последовательная обработка).
Режим 2. Получить уникальные (например, одна запись) данные, для чего используют прямой доступ (хеширование, идентификаторы), индексный метод (первичный ключ), произвольный доступ, последовательный доступ (бинарное B-дерево, B+-дерево).
Режим 3. Получить некоторые (группу записей) данные, для чего применяют вторичные ключи, мультисписок, инвертированный метод, двусвязное дерево.
В БД содержатся не только пользовательские данные, но и большой объем специальных данных. Поэтому в составе БД можно выделить следующие виды данных:
· Пользовательские данные, которые отражают информационные потребности конечных пользователей (именно проектирование моделей этих данных обсуждалось ранее);
· Управляющие данные – метаданные
· Вспомогательные данные.
Для ускорения процесса поиска и упорядочения данных создаются вспомогательные индексные файлы, которые хранят специальные данные – индексы. В качестве индексов могут выступать отдельные поля, прежде всего ключи. Индексный файл меньше по размеру, и потому скорость поиска увеличивается. «Платой» за это является необходимость использования дополнительной, вторичной память. В зависимости от способа построения различают плотный и разреженные индексы. Индекс может быть многоуровневым (B+-деревья). Часто в качестве индексов используют числа.
Основными методами хранения и поиска данных в БД являются:
· последовательный,
· прямой,
· индексно-последовательный
· индексно-прямой.
Для их сравнительной оценки использую различные критерии:
· Эффективность хранения – величина, обратная среднему числу байтов вторичной памяти, необходимому для хранения одного байта исходной памяти.
· Эффективность доступа – величина, обратная среднему числу физических обращений, необходимых для осуществления логического доступа.
При использовании индексно-прямого и индексно-последовательного методов доступа различают основной и индексный файл.
Физически последовательный метод. Записи хранятся в логической последовательности, файл имеет постоянный размер, указатели могут отсутствовать. Данные хранятся в главном файле, а обновление требует создания нового главного файла с упорядочением, для чего используется вспомогательный файл. Эффективность использования памяти близка к ста процентам, эффективность доступа низка.
Метод удобен для режима 1, однако быстродействие в режиме 2 мало: для его повышения необходимо использовать бинарный поиск (B- и B+-деревья). Время включения и удаления записей значительно.
Индексно-последовательный метод.Индексный файл упорядочен по первичному ключу (главному атрибуту физической записи). Индекс является разреженным, индексный файл (рис. 5.9) содержит ссылки не на каждую запись, а на группу записей Последовательная организация индексного файла допускает, в свою очередь, его индексацию (многоуровневая индексация). Процедура добавления возможна в двух видах.
1. Новая запись запоминается в отдельном файле (области), называемом областью переполнения. Блок этой области связывается в цепочку с блоком, которому логически принадлежит запись. Запись вводится в основной файл.
2. Если места в блоке основного файла нет, запись делится пополам и в индексном файле создается новый блок.
Наличие индексного файла большого размера снижает эффективность доступа. В большой БД основным параметром становится скорость выборки первичных и вторичных ключей. При большой интенсивности обновления данных следует периодически проводить реорганизацию БД. Эффективность хранения зависит от размера и изменяемости БД, а эффективность доступа - от числа уровней индексации, распределения памяти для хранения индекса, числа записей в БД, уровня переполнения.
При произвольных методах записи физически располагаются произвольно.