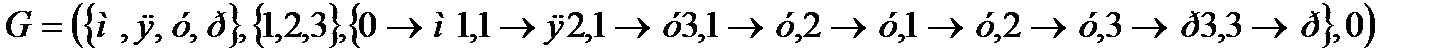Эти программы получают в качестве входа последовательность команд для построения исходной программы. Такой редактор не только выполняет обычные для текстового редактора функции по созданию и модификации текста, но и анализирует текст программы, помещая в исходную программу соответствующую иерархическую структуру. Тем самым он выполняет дополнительные задачи, облегчающие подготовку программы. Например, редактор может проверять корректность введенного текста, автоматически добавлять структурные элементы (так, если пользователь введет while, редактор добавит соответствующее ему ключевое слово do и предложит ввести условие между ними) или переходить от ключевого слова begin или левой скобки к соответствующему end или правой скобке. Более того, выход такого редактора зачастую подобен выходу после фазы анализа компиляции.
Программы форматированного вывода на печать
С помощью этих инструментов программа анализируется и распечатывается таким образом, чтобы ее структура была максимально ясной. Например, комментарии могут быть выделены специальным шрифтом, а операторы – выведены с отступами, указывающими уровень вложенности в иерархической структуре операторов.
Статические проверяющие программы
Данные инструменты считывают программы, анализируют их и пытаются найти потенциальные ошибки без запуска программы. Например, статическая проверяющая программа может определить невыполнение какой-то части исходной программы или использование некоторой переменной до ее объявления.
Интерпретаторы
Вместо создания целевой программы в результате трансляции интерпретатор выполняет операции, указанные в исходной программе. Интерпретаторы часто используются для командных языков, поскольку каждый их оператор представляет собой вызов сложной программы, такой как редактор или компилятор.
Традиционно предназначением компилятора считается трансляция исходного языка типа Pascal или C++ в ассемблер или машинный язык. Однако имеются и другие применения технологии компиляции. Так, анализирующая часть в каждом из приведенных ниже примеров подобна анализатору обычного компилятора.
· Форматирование текста. Программа форматирования текста получает на вход поток символов, большинство из которых представляет выводимый текст, но многие из символов означают абзацы, рисунки или математические структуры, например, верхние или нижние индексы.
· «Кремниевые» компиляторы (Silicon Compilers). Такой компилятор имеет исходный язык, схожий с обычным языком программирования. Однако переменные языка представляют не положения в памяти, а логические сигналы (0 или 1) или группы сигналов в коммутируемых линиях.
· Интерпретаторы запросов. Данные интерпретаторы транслируют предикаты, содержащие операторы отношений и логические операторы, в команды поиска в базе данных записей, удовлетворяющих данному предикату. Сейчас, с появлением языка структурированных запросов SQL эта задача даже не просто подобна анализу компилятора, а является таковой.
При создании целевой программы, кроме компилятора, может потребоваться и ряд других программ. Исходная программа может быть разделена на модули, хранимые в отдельных файлах. Задача сбора исходной программы иногда поручается отдельной программе – препроцессору, который может также раскрывать в тексте исходной программы сокращения, называемые макросами.
В C++, например, существуют так называемые директивы препроцессора, которые начинаются с символа #. Например, #include, которая указывает, что надо подключить модуль, директива #define и другие.
На следующем рисунке показана типичная «компиляция». Целевая программа, создаваемая компилятором, может потребовать дополнительной обработки перед запуском. Компилятор создает ассемблерный кода, который переводится ассемблером в машинный код, а затем связывается («линкуется») совместно с некоторыми библиотечными программами в реально запускаемый на машине код.
Препроцессор
Исходная программа
Компилятор
Ассемблер
Перемещаемый машинный код
Загрузчик/редактор связей
Абсолютный машинный код
Библиотека,
объектные файл
Целевая ассемблерная программа
Формальные грамматики
Алфавит – конечное непустое множество символов.
begin x:=1 end;
Для языка begin – это один символ. x, :=,1,end,; - тоже символы языка.
A – алфавит. A* - множество всех цепочек над данным алфавитом (т.е. составленных из символов алфавита).
Язык можно описать, например, описав все возможные предложения (цепочки) языка.
A = {0,1} - алфавит
L = {01,1,11} – язык.
Цепочка принадлежит языку, если она принадлежит множеству L. Т.е. в данном примере 01 – это предложение языка, а 0 – нет.
Но для реальных языков, которые, как правило, являются бесконечными (т.е. множество предложений бесконечно), такой способ не подходит. Поэтому необходим другой способ описания языка и способ определения принадлежности цепочки языку.
Для этого нужно описать синтаксис языка.
Синтаксис – это совокупность правил описания правильных структур языка.
Для описания синтаксиса языка используются грамматики.
Грамматика естественным образом описывает иерархическую структуру множества конструкций языка программирования. Например, инструкция if-else в C++ имеет вид
if (выражение) инструкцияelseинструкция
Используя переменную expr для обозначения выражения и переменную stmt для обозначения инструкции можно записать это структурное правило так:
stmt à if (expr) stmt else stmt
Символ à можно понимать как «может иметь вид». Такое правило называется продукцией (production) или правилом.
Грамматикой называется четверка (A,V,P, s), где
A – алфавит терминальных символов.
V – алфавит нетерминальных символов.
P – множество продукций (правил).
s – начальный символ.
G=(A, V, P, s)
Правила записываются в следующем виде:
, где
Т.е. левая часть правила не должна быть просто совокупностью терминальных символов.
Нетерминальные символы будем записывать малыми латинскими буквами, а цепочки символов – малыми греческими буквами. Пустую цепочку обозначают символом e.
Пусть есть цепочки и . - выводится из , тогда и только тогда, когда
.
Если цепочка выводится за несколько шагов, то над знаком вывода ставится *. .
Язык L, порождаемый грамматикой G = (A,V, P, s) – это множество цепочек , которое выводится из начального символа
Грамматика в таком случае называется порождающей.
Пример:
С помощью этой грамматики можно вывести 0
Можно вывести 0100
Грамматик для языка можно построить много.
Две грамматики называются эквивалентными, если они порождают один и тот же язык.
Например, если просто переобозначить символы (например вместо u писать v), получится эквивалентная грамматика.
Левая часть правил в таких грамматиках – всегда один символ
Пример:
4) Регулярные грамматики
Бывают праволинейные – с правилами вида.
Бывают леволинейные – с правилами вида.
Левая часть правил в таких грамматиках – всегда один символ, а в правой части не может быть более одного нетерминала.
Пример:
Регулярные выражения
Идентификатор в паскале представляет собой букву, за которой следует нуль или несколько букв или цифр. Множество идентификаторов можно определить с помощью следующего регулярного выражения:
letter(letter|digit)*
Регулярное выражение строится из более простых регулярных выражений с использованием набора правил. Каждое регулярное выражение r обозначает или задает язык L(r).
Рекурсивное определение регулярного выражения над алфавитом A:
1) e (пустая строка) представляет собой регулярное выражение, обозначающее {e}, т.е. множество содержащее пустую строку.
2) Если , то a – регулярное выражение, обозначающее {a}, т.е. множество содержащее строку a.
3) Если r и s – регулярные выражения, обозначающее языки L(r) и L(s), то
· (r)* - регулярное выражение, обозначающее . Т.е. регулярное выражение можно повторять 0 или более раз.
· (r) – регулярное выражение, обозначающее L(r).
Язык, задаваемый регулярным выражением, называется регулярным множеством.
Излишние скобки в регулярном выражении могут быть устранены, если принять следующие соглашения:
· Унарный оператор * имеет высший приоритет и левоассоциативен.
· Конкатенация имеет второй по значимости приоритет и левоассоциативна.
· | (объединение) имеет низший приоритет и левоассоциативно.
При этих соглашениях (a)|((b)*(c) эквивалентно a|b*c.
Алгебраические свойства регулярных выражений
Аксиома
Описание
r|s=s|r
Оператор | коммутативен
r|(s|t)=(r|s)|t
Оператор | ассоциативен
(rs)t=r(st)
Конкатенация ассоциативна
r (s|t)=rs|rt
(s|t)r=sr|tr
Конкатенация дистрибутивна над |
er=r
re=r
e является единичным элементом по отношению к конкатенации
r*=(r|e)*
Связь между * и e
r**=r*
Оператор * идемпотентен
Для удобства записи регулярным выражениям можно давать имена и определять регулярные выражения с использованием этих имен. Например:
letter ® A | B | …| Z | a | b |…| z
digit ® 0 | 1 | … | 9
id ® letter(letter|digit)*
id описывает идентификатор, который может содержать буквы и цифры и должен начинаться с буквы.
Такие записи называются регулярными определениями.
Конечные автоматы
Распознавателем (recognizer) языка называется программа, которая получает на вход строку x и отвечает “да”, если x – предложение языка, или в противном случае “нет”.
Для регулярных выражений используется частный случай распознавателя – конечный автомат (КА). Конечные автоматы бывают недетерминированные и детерминированные.
Недетерминированным конечным автоматом (НКА, nondeterministic finite automation, NFA) называется пятерка (S, A, m, s0, F ) из:
1. Множества состояний S;
2. Множества входных символов A.
3. Функции перехода m, которая отображает пары состояние-символ на множество состояний.
4.
5. Состояния s0, известного как стартовое (начальное).
6. Множества состояний F, известных как допускающие (конечные);
Пример:
Автомат распознающий язык м((яу)|(ур*)). Т.е. слова мяу, му, мур, мурр и т.д.
S = {0, 1, 2, 3, 4, 5}
A = {м, я, у, р}
m:
(0, м) ® 1
(0, м) ® 2
(1, я) ® 3
(2, e) ® 3
(2, у) ® 4
(3, у) ® 5
(4, р) ® 4
s0 = 0
F = {4, 5}
Для конечного автомата можно построить так называемый граф переходов, вершинами которого являются состояния, а дуги задают функцию перехода. Конечные состояния обозначаются двойным кругом.
Для автомата из примера граф переходов будет выглядеть так:
у
start
м
м
я
у
р
e
Конечный автомат допускает или принимает (accept) входную строку x (а эта строка является допустимой) тогда и только тогда, когда в графе переходов существует некоторый путь от начального состояния к какому-либо из конечных, такой что метки дуг этого пути соответствуют строке x.
Автомат работает следующим образом. Работа начинается в стартовом состоянии. Затем автомат на каждом шаге читает символ и переходит в новое состояние (в зависимости от прочитанного символа и текущего символа). Затем читает следующий символ и опять переходит в новое состояние. И так до тех пор, пока не перейдет в конечное состояние. Недетерминированный конечный автомат может переходить в новое состояние и не читая символ (читая пустой символ e). Такой шаг называется e-переходом. Если встретился символ, для которого в данном состоянии нет дуги, и состояние не конечное, то автомат выдает ошибку (это означает, что строка недопустима, т.е. не принадлежит задаваемому автоматом языку).
В данном примере, проверяя строку «муррр», автомат пройдет через следующую последовательность состояний: .
Детерминированный конечный автомат (ДКА, deterministic finite automation, DFA) – специальный случай недетерминированного конечного автомата, в котором
· отсутствуют состояния, имеющие e-переходы
· для каждого состояния s и входного символа a существует не более одной дуги, исходящей из s и помеченной как a.
Для любого недетерминированного автомата можно построить эквивалентный детерминированный автомат. Существует формальный алгоритм приведения недетерминированного автомата к детерминированному, однако он не будет приведен в данной лекции.
start
у
у
м
р
я
Для примера с языком {мяу, му, мур, мурр, …} эквивалентный детерминированный автомат будет выглядеть так:
Cвязь между конечными автоматами, регулярными выражениями и регулярными грамматиками
Для любого регулярного автомата можно построить регулярную грамматику, порождающую тот же язык и наоборот. Для любого регулярного выражения можно построить конечный автомат. Обратное неверно.
Это можно изобразить следующим рисунком
Регулярная грамматика
Регулярное выражение
Конечный
автомат
Для предыдущего примера регулярная грамматика будет выглядеть так:
Применение конечных автоматов для создания интерпретаторов
Разбирая предложения языка и переходя из состояния в состояние, конечный автомат может выполнять дополнительные действия. Таким образом, с помощью конечных автоматов можно создавать интерпретаторы, которые будут выполнять команды, описанные на некотором языке.
Рассмотрим в качестве примера простой калькулятор, который умеет складывать и вычитать целые числа.
S = {f, p, m, e}
f – чтения первого аргумента
p – чтение слагаемого
m – чтение вычитаемого
e – знак = - окончание вычислений
A = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, +, -, =}
F = {e}
Набор правил опишем графом переходов конечного автомата.
e
p
start
m
+
0..9
f
-
=
=
=
-
+
0..9
0..9
class CCalculator
{
// Состояние
enum State {sFirstArg, sPlus, sMinus, sEqual};
State m_State;
public int Calculate(string a_Script, out string a_ErrorMessage)
{
// Начальное состояние
m_State = State.sFirstArg;
// Строки, в которой будут сохраняться прочитанные числа
int zResult = 0;
string zArg = "";
int i = 0; // Текущая позиция в строке
while ((m_State != State.sEqual) && (i < a_Script.Length))
{
switch (m_State)
{
// Чтение первого аргумента
case State.sFirstArg:
{
// Читаем цифры числа
if ((a_Script[i] >= '0') && (a_Script[i] <= '9'))
{
zArg += a_Script[i];
}
// Если встретили + или -,
// запоминаем считанное число
else if (a_Script[i] == '+')
{
if (zArg == "") zResult = 0;
else zResult = int.Parse(zArg);
zArg = "";
m_State = State.sPlus;
}
else if (a_Script[i] == '-')
{
if (zArg == "") zResult = 0;
else zResult = int.Parse(zArg);
zArg = "";
m_State = State.sMinus;
}
else if (a_Script[i] == '=')
{
if (zArg != "") zResult = int.Parse(zArg);
zArg = "";
m_State = State.sEqual;
}
else
{
a_ErrorMessage =
"Ошибка на позиции " + i.ToString() + ": недопустимый символ";
return 0;
}
break;
}
// Чтение слагаемого
case State.sPlus:
{
if ((a_Script[i] >= '0') && (a_Script[i] <= '9'))
{
zArg += a_Script[i];
}
else if (a_Script[i] == '+')
{
if (zArg != "") zResult += int.Parse(zArg);
zArg = "";
m_State = State.sPlus;
}
else if (a_Script[i] == '-')
{
if (zArg != "") zResult += int.Parse(zArg);
zArg = "";
m_State = State.sMinus;
}
else if (a_Script[i] == '=')
{
if (zArg != "") zResult += int.Parse(zArg);
zArg = "";
m_State = State.sEqual;
}
else
{
a_ErrorMessage =
"Ошибка на позиции " + i.ToString() + ": недопустимый символ";
return 0;
}
break;
}
// Чтение вычитаемого
case State.sMinus:
{
if ((a_Script[i] >= '0') && (a_Script[i] <= '9'))
{
zArg += a_Script[i];
}
else if (a_Script[i] == '+')
{
if (zArg != "") zResult -= int.Parse(zArg);
zArg = "";
m_State = State.sPlus;
}
else if (a_Script[i] == '-')
{
if (zArg != "") zResult -= int.Parse(zArg);
zArg = "";
m_State = State.sMinus;
}
else if (a_Script[i] == '=')
{
if (zArg != "") zResult -= int.Parse(zArg);
zArg = "";
m_State = State.sEqual;
}
else
{
a_ErrorMessage =
"Ошибка на позиции " + i.ToString() + ": недопустимый символ";
return 0;
}
break;
}
}
i++;
}
if (m_State == State.sEqual)
{
if (i == a_Script.Length)
{
a_ErrorMessage = "";
return zResult;
}
else
{
a_ErrorMessage =
"Ошибка на позиции " + i.ToString() + " символы после знака =";
return 0;
}
}
a_ErrorMessage = "Ошибка: Скрипт не закончен";
return 0;
}
}
Конечные автоматы и ООП
Каждый объект находится в одном из состояний (которое определяется его атрибутами) и обладает поведением, которое зависит от его состояния. В общем случае, у объекта может быть очень большое (и даже бесконечное) количество состояний, т.к. оно равно множеству всех допустимых атрибутов. Однако иногда бывает удобно явно выделить состояние объекта в отдельный атрибут (это состояние может соответсвовать и диапазону значений атрибутов) и реализовать в нем конечный автомат, определяющий логику перехода между состояниями.
Явное выделение состояний и конечного автомата позволяет более четко описать алгоритм работы объекта. Это, в свою очередь, позволяет избежать ошибок, возникающих, когда какое-то из состояний не учтено, например, попыток использовать объект, который не инициализирован. Также конечный автомат позволяет достаточно легко менять поведение объекта. Если функция перехода из состояние в состояние описана вне программы (в файле или базе данных), то поведение программы можно менять, не меняя ее текст.
Конечный автомат удобно использовать для описания логики пользовательского интерфейса. Нажимая кнопки и выполняя другие действия, пользователь переводит интерфейс из состояния в состояние. В зависимости от текущего состояния интерфейсные элементы (кнопки, поля ввода и др.) включаются и выключаются. Включение и выключение интерфейсных элементов удобно вынести в отдельный метод формы – так называемый активатор (enabler). Это более удобно и надежно, чем раскидывать включение и выключение кнопок в разные обработчики событий. Благодаря явному выделению автомата можно отследить все возможные действия пользователя (которые могут происходить в разной последовательности) и обеспечить корректную реакцию на них.
Конечные автоматы используются в разных областях, когда нужно формально описать некоторое поведение: в компьютерных играх для описания поведения персонажей, в драйверах различных устройств, в прикладных системах (при обработе заказов клиентов, в системах документооборота и т.д.).
[1] Сборка (assembly) – это программная единица в C# - exe или dll-файл. При подключении dll-сборки к проекту в .NET можно использовать то, что не объявлено как internal.
Вопрос 1. Понятие экономического анализа и история его развития. Классификация экономического анализа.
Все экономические дисциплины являются общественными науками, то есть изучают практическую деятельность человека. Особое место в системе экономических наук занимает экономический анализ.
Analyzis – от греческого слова “разделяю”, “расчленяю”. В широком смысле слова анализ - способ познания предметов и явлений окружающей среды, основанный на расчленении целого на составные части и изучении их во всём многообразии связей и зависимостей (пример: медицинские, технические анализы).
Экономический анализ базируется на абстракции и логике исследований. Чтобы проводить такой анализ, человек должен обладать абстрактным воображением, логическим мышлением и логической памятью.
Экономический анализ – система специальных знаний, связанных с исследованием тенденций хозяйственного развития, научным обоснованием планов, управленческих решений, контролем за их выполнением, оценкой достигнутых результатов, поиском измерения и обоснования величины хозяйственных резервов, повышением эффективности производства и разработкой мероприятий по их использованию.
Экономический анализ имеет два уровня:
1. макроэкономический (общетеоретический) анализ,
2. Экономический анализ микроуровня, то есть на уровне предприятия.
Элементы экономического анализа появились в бухгалтерском учёте, в статистике, финансах, в балансоведении. Но практическая деятельность человека в начале 20 века потребовала выделить теоретические и практические вопросы АХД в отдельную науку. В 30-е годы курс АХД стал читаться в ВУЗах СССР. Тогда же появились первые учебники. Авторы – Вейцман, Баканов. В развитие этой науки внесли вклад Стражев, Шеремет и др.
Перспективы развития АХД зависят от объективных и субъективных причин.
Объективные причины:
- развитие смежных наук (математики, статистики, бухгалтерского учёта и т.д.)
- развитие и запросы практики, производства
- развитие рыночных отношений в экономике государства
Субъективные причины: развитие или сохранение командно- административной системы является тормозом для развития науки экономический анализ.
В целом экономический анализ как наука представляет собой систему специальных знаний, связанных с исследованием тенденций хозяйственного развития, научным обоснованием планов, управленческих решений, контролем за их выполнением, оценкой достигнутых результатов, поиском, измерением и обоснованием величины хозяйственных резервов повышения эффективности деятельности и разработкой мероприятий по их использованию.
По отраслевому признаку
1. отраслевой (растениеводство, животноводство)
2. межотраслевой (на стыке отраслей – кормопроизводство, внесение органических удобрений)

 , где
, где 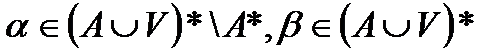
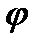 и
и 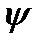 .
.  -
-  выводится из
выводится из 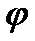 , тогда и только тогда, когда
, тогда и только тогда, когда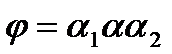

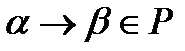 .
. .
.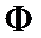 , которое выводится из начального символа
, которое выводится из начального символа
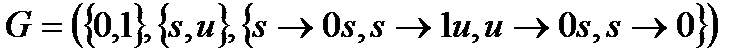
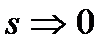

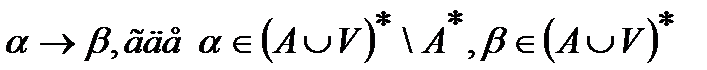


 в ней не может быть.
в ней не может быть.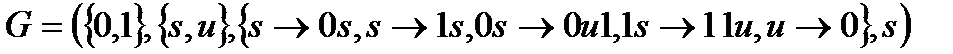

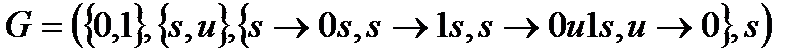
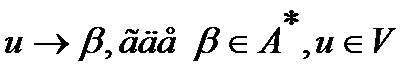
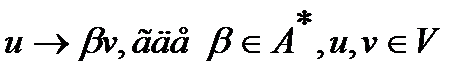


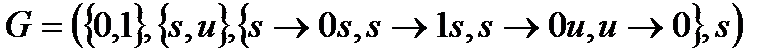
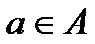 , то a – регулярное выражение, обозначающее {a}, т.е. множество содержащее строку a.
, то a – регулярное выражение, обозначающее {a}, т.е. множество содержащее строку a.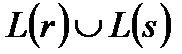 . | - обозначает «или».
. | - обозначает «или».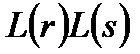 . Конкатенация строк.
. Конкатенация строк.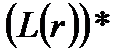 . Т.е. регулярное выражение можно повторять 0 или более раз.
. Т.е. регулярное выражение можно повторять 0 или более раз.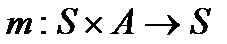
 .
.