Все рассмотренные выше градиентные методы поиска экстремума функций нескольких переменных работают в предположении, что целевая функция имеет единственный экстремум. Задача отыскания глобального экстремума многоэкстремальной функции, т. е. функции, имеющей несколько максимумов или минимумов, значительно сложнее. Применение любого из изложенных методов позволяет в этом случае отыскать лишь какой-либо один из локальных экстремумов целевой функции, который не обязательно совпадает с глобальным экстремумом. Это утверждение иллюстрируется на рис. 1.12, где изображены линии уровня функции двух переменных, имеющей два максимума в точках А и В.
Рис.1.12
Предположим, что экстремум отыскивают одним из градиентных методов. Если движение начнется из точки , то будет найден максимум в точке А. Если же исходной точкой будет точка , то поиск закончится в точке В. Стрелки, выходящие из точек и 02, указывают направления градиента функции в этих точках. Это указывает на возможность модернизации рассмотренных методов поиска с тем, чтобы приспособить их для отыскания глобального экстремума многоэкстремальных функций. Для этого можно рекомендовать повторение процедуры поиска несколько раз из различных исходных точек. Полученные значения локальных экстремумов сравниваются между собой, и из них выбирается наибольшее (при поиске глобального максимума). Для выбора положений исходных точек может использоваться как случайная, так и детерминированная процедура.
Существует другой метод, позволяющий отыскать глобальный экстремум целевой функции с заданной точностью — метод глобального перебора, или сканирования. Предположим, что для каждого из аргументов целевой функции у = задан диапазон его изменения: В пространстве переменных системе этих неравенств соответствует многомерный параллелепипед, являющийся областью допустимых значений аргументов целевой функции. Для случая функции двух переменных
у = имеем прямоугольник (рис. 2.12).
Рис.2.12
Диапазон [ ] изменения каждой переменной разбивается на достаточно большое число равных отрезков. Это число выбирают, исходя из заданной точности отыскания точки экстремума. В результате в области допустимых значений выделяется конечное число точек. Для каждой из них вычисляется значение целевой функции, а из полученного множества этих значений выбирается максимальное (или минимальное).
Являясь наиболее простым и универсальным, метод глобального перебора одновременно, является и самым трудоемким методом решения задач нелинейного программирования
Практически он применим только при числе переменных целевой функции не больше 3—4 из-за того, что его трудоемкость быстро возрастает с ростом размерности задачи. В самом деле, пусть заданная точность решения задачи будет достигнута, если на каждом отрезке [ ] взять 10 равноотстоящих точек. Тогда для отыскания экстремума функции двух переменных надо вычислить ее значения в 100 точках, являющихся узлами полученной сетки. Для функции трех переменных потребуется уже 10 =1000 ее вычислений и т. д. Если переменных 5, то целевую функцию нужно рассчитывать уже 205 раз.
Для отыскания глобального экстремума можно использовать и методы случайного поиска, модернизировав их так, чтобы наряду с малыми шагами, посредством которых обеспечивается приближение к некоторому локальному экстремуму, иногда допускались и большие шаги, переводящие систему в область притяжения другого локального экстремума.
При решении задач с учетом ограничений для каждой точки пространства поиска, необходимо ,сначала, последовательно проверить выполняемость всех ограничений. Если хотя бы одно из них не выполняется, то это означает, что данная точка в пространстве поиска находится вне пределов области допустимых решений можно сразу перейти к следующей точке. И только в том случае, когда все ограничения вычисляется значение целевой функции.
Как правило, метод глобального перебора реализуется с использованием компъютера.
Рассмотри, сначала, алгоритма метода глобально перебора для отыскания максимума функции одной переменной. Блок –схема этого алгоритма показана на рис.3.12. Будем считать, для определенности, что требуется найти решение оптимизационной задачи, математическая модель которой имеет вид:
На первом этапе (блок 1) осуществляется ввод информации, необходимой для решения задачи: вводится целевая функция , ограничение , границы
и на котором происходит поиск максимума, а так же значение шага с которым будет происходить перебор точек внутри отрезка
.
Зарезервируем в памяти ЭВМ ячейку, в которой будем хранить одно единственное, наибольшее по всем предыдущем шагам значение целевой функции. Обозначим соответствующую переменную через М. В начале работы программы в эту ячейку запишем «0» (блок 2). То есть присвоим М значение равное «0»: М=0 (= символ присваивания).
Рис.3.12
Вычисление значений ограничения и целевой функции начинаем с левого конца отрезка на котором осуществляется поиск максимума. Для этого присваиваем (блок3) переменной Х значение равное :Х= .
Далее, (блок 4) вычисляем значение ограничения и производим (блок 5) сравнение полученного результата с правой частью ограничения ( )
Допустим, что условие
выполняется , то есть мы находимся в пределах области допустимых решений. В этом случае вычислительный процесс происходит по стрелке «Да» и мы переходим к выполнению блока 6.
Если условие ( ) не выполняется, целевая функция не вычисляется и сразу переходим к блоку 10 .
В блоке 7 происходит вычисление значения целевой функции, после чего (блок 8) происходит сравнение полученного значения целевой функции с переменной М. Так как переменная М (за исключением первой итерации) всегда равна наибольшему по всем предыдущим итерациям значению целевой функции, условие
будет выполняться только в том случае, если значение целевой функции в
данной точке Х будет больше, чем во всех предыдущих. В этом случае (блок 9) переменной М присваивается новое значение М=W, и она снова становится равной наибольшему среди всех рассмотренных значений целевой функции. В блоке 9 переменной присваивается текущее значение переменной X: . Таким образом переменная показывает, какому значении Х соответствует текущее максимальное значение целевой функции.
В следующем ( 10 блоке) происходит переход к новой точке вычисления (переменной присваивается новое значение, которое на величину шага большн предыдущего и производится проверка (блок11) условия , которое обеспечивает поиск максимума только в пределах заданного диапазона изменения переменной Х. Если условие выполняется, возвращаются к блоку 4, рассчитывают значение ограничения и происходит циклический повтор выполнения блоков каждый раз для нового значения Х. Так продолжается до тех пор, пока значение Х не станет больше верхней границы ( 200 ), после чего вычисления заканчиваются.
Рассмотрим алгоритм глобального перебора для решения задач нелинейного программирования с 2-мя переменными. Пусть требуется решить следующую задачу:
Схема алгоритма, основанного на идее перебора значений переменных , приведена на рис. 4.12.
Предварительно выбраны величины шагов по и , обеспечивающие удовлетворительную точность решения задачи. Обозначим их и пусть ; . Вначале (блок 1) переменные и полагают равными их исходным значениям: Переменная М в имеет тот же смысл и выполняет те же функции, что и в алгоритме поиска экстремума функции одной переменной (см. рис. 3.12) Поэтому вначале ее следует положить равной любому числу, заведомо меньшему максимального значения целевой функции. Поскольку в данной задаче целевая функция неотрицательна, можно положить М=0, что и сделано в блоке 1. Далее проверяется, удовлетворяет ли исходная точка { Х=; Х= ограничению решаемой задачи: С этой целью в блоке 2 вычисляется значение функции из этого ограничения, а полученное числовое значение присваивается переменной z. В блоке проверки условия 3, имеющем на схеме вид ромба, проверяется выполнение записанного внутри него соотношения (в данном случае неравенства z<9). Если это неравенство оказалось справедливым, т. е. рассматриваемая точка удовлетворяет данному ограничению, то осуществляется переход по стрелке «Да» к блоку 4, где вычисляется значение целевой функции в той же точке { }. Оно присваивается переменной у. Невыполнение условия в блоке 3 означает, что эта точка не
Рис.4.13
принадлежит области допустимых значений. Поэтому не имеет смысла вычислять в ней значение целевой функции, а следует сразу же перейти к следующей точке. Это и реализовано переходом к блоку 8. Соответствующее ему действие означает, что к зафиксированному ранее значению переменной добавляется число 0,1. Значит, при первом обращении к блоку 8 примет значение и таким образом будет исследоваться точка { }. Обратимся к операциям в блоке 5, выполняемым вслед за операциями в блоке 4. Здесь анализируется выполнение неравенства у>М, т. е. проверяется, будет ли только что найденное значение целевой функции больше М. При первом обращении к этому блоку М= = 0 (блок 1), поэтому неравенство у>М в этом случае наверняка будет выполнено и, следовательно, произойдет переход к блоку 6. Выполняемое здесь присваивание М:=у означает, что переменная М примет теперь значение, равное значению целевой функции в анализируемой точке. Согласно блоку 7, значения аргументов X и Х присваиваются новым переменным и , которые тем самым будут хранить значения переменных и х ,соответствующие значению целевой функции, равному М. Далее выполняется переход к следующей точке с большим значением (блок 8) и проверяется, не превысит ли это значение максимальной для него величины =4 (блок 9). Если оказалось, что < 4, то осуществляется возврат к блоку 2, т. е. все описанные выше процедуры, начиная с проверки выполнения ограничения <9, выполняются для новой точки { }. Отметим, что при втором и последующих обращениях к блоку 5 уже возможны разные случаи. До тех пор, пока значение целевой функции в очередной точке больше чем в предыдущей, неравенство у>М будет выполняться и согласно блоку 6 переменная М будет каждый раз принимать значение, равное очередному возрастающему значению целевой функции У( . Если же в некоторой точке ее величина окажется меньше, чем в предыдущей точке (или равна ей), то вследствие невыполнения неравенства у>М присваивание М:=у не будет сделано (блоки 6 и 7 обходятся). Благодаря этому переменная М сохраняет значение, равное максимальному значению целевой функции по всем предыдущим точкам, принадлежащим области допустимых решений, а переменные а и равны значениям аргументов х и в точке максимума.
Вернемся к блоку 9 и рассмотрим случай, когда записанное в нем условие не выполняется. Это означает, что для данного значения Х=25 перебор по х следует завершить и возобновить его вновь, начиная с =2, уже для следующего значения . Поэтому в блоке 10 реализовано присваивание 1: = 2, а согласно блоку 11 значение х увеличивается на величину ее шага. После этого осуществляется возврат к блоку 2, т. е. анализируется очередная точка. Невыполнение неравенства < в блоке 12 свидетельствует о необходимости завершить перебор. В этом случае согласно блоку 13 выводится найденное оптимальное решение: значение М, равное максимальному значению целевой функции по всем точкам из области допустимых решений, и значения переменных а и , равные аргументам и в точке оптимума. Этим завершается работа алгоритма. Реализация его на ЭВМ позволила получить следующие результаты: а= ; М .
Лекция 13
Общие сведения о задачах календарного планирования
В задачах календарного планирования решается вопрос об оптимальной последовательности выполнения тех или иных операций. В технологии деревообработки, в частности в мебельном производстве, это чаще всего относится к порядку запуска в обработку различных деталей. В лесопилении актуальна задача определения оптимальных размеров и порядка запуска в распиловку партий пиловочного сырья с различными размерно- качественными характеристиками. При этом сортиментный план производства пиломатериалов должен быть выполнен с наименьшими затратами.
Задачи календарного планирования изучаются теорией расписаний. Здесь термин «расписание» соответствует понятию календарного плана, т. е. последовательности проведения некоторых операций. Эти задачи оказались весьма сложными с математической точки зрения, поэтому точные решения получены лишь для самых простых случаев. Формально задачи календарного планирования можно свести к, задачам целочисленного программирования, но сам по себе этот прием не слишком облегчает их решение.

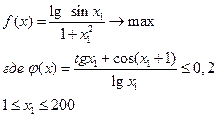 На первом этапе (блок 1) осуществляется ввод информации, необходимой для решения задачи: вводится целевая функция , ограничение , границы
На первом этапе (блок 1) осуществляется ввод информации, необходимой для решения задачи: вводится целевая функция , ограничение , границы