На содержательном уровне структур данных исследуются конкретные объекты обработки, их свойства и отношения между объектами. На этом уровне важны не только значения, но и смысл данных.
На логическом или абстрактном (логические структуры) уровне структура данных считается машинно-независимым логическим понятием, и выделяются следующие задачи: определение массивов данных как объектов исследования, выделение состава массива, определение структуры данных по заданным требованиям, разработка количественных методов оценки эффективности различных видов структур данных.
Физический уровень (физическая структура). На этом уровне рассматриваются память ЭВМ и представление в ней значений (ячейки, разряды ячеек, их адреса и взаимное расположение значений.), т.е. отображение данных в памяти ЭВМ. В общем случае между логической и соответствующей ей физической структурами существует различие, степень которого зависит от самой структуры и особенностей той физической среды, в которой она должна быть отражена.
Структуры данных можно классифицировать по нескольким различным признакам. Рассмотрим два варианта классификации. По одному их них структуры данных разделяются на несколько категорий (до 7). Рассмотрим эти категории с примерами, соответствующими каждой категории.
Наиболее простым и понятным критерием классификации является сложность структур данных.
По уровню сложности структуры данных разделяются на
1. простые – обычные переменные или константы языков программирования стандартных типов, а также динамические переменные этих же типов;
2. наборы однотипных данных – массивы, одно- и многомерные;
3. интегральные – записи и объекты классов и подобные структуры;
4. динамические структуры с внутренними связями – списки, деревья, графы.
По способу создания структуры данных можно разделить на
1. обычные – переменные стандартных типов, обычные (т.е. не динамические) массивы, записи и т.п.;
2. динамические (создаваемые и разрушаемые с помощью специальных операций или процедур динамического выделения и освобождения памяти) – динамические массивы, динамические переменные, связные списки, деревья.
2. прямоугольные структуры – двумерные и многомерные массивы;
3. кольцевые структуры – кольцевые списки, кольцевые очереди, некоторые реализации графов;
4. ветвящиеся структуры – деревья различных видов, некоторые реализации графов;
5. сетевые структуры – графы.
В зависимости от наличия или отсутствия связей различают:
1. несвязные структуры – векторы, массивы, строки, стеки, очереди;
2. связные – списки, деревья, графы.
В зависимости от постоянства во время работы программы различают:
1. статические (неизменяющиеся) структуры – переменные различных типов, записи, массивы, в том числе динамические.
2. динамические (изменяющиеся) – списки, деревья, очереди, стеки, в общем случае графы.
Здесь следует обратить внимание на то, что термин «динамические» употребляется в разных смыслах, и структуры, динамические по способу создания, могут быть статическими по своему поведению. Структуры, динамические по поведению, как правило, оказываются динамическими и по способу создания. Также следует обратить внимание на то, что термин «статические» используется и в некоторых языках программирования, например, в Си и Си++, и там его смысл в значительной степени отличается от подразумеваемого в приведённой классификации.
Следующий критерий классификации достаточно сложно назвать одним или несколькими словами, поэтому сразу приведём его варианты:
1. данные, создаваемые самим программистом (независимо от способа и времени создания), в англоязычной литературе по программированию часто обозначаемые словом persistent – «устойчивый» («постоянный», «постоянно существующий»). Таким являются структуры всех данных, явно созданных программистом при написании программы;
2. создаваемые и разрушаемые непосредственно во время работы программы без участия программиста, обычно во вспомогательных целях, например, при несовпадении типов данных в каких-либо операциях. Для них используется термин transient – «преходящий», «временный». Их действительно можно коротко назвать временными, поскольку они обычно уничтожаются сразу после их использования. Как правило, такие данные, как объекты в программе, являются безымянными. В некоторых языках программирования, например, Си++, такими данными могут быть данные любых типов. О временных структурах часто говорят, что они создаются не программистом, а самим компилятором (ещё один вариант – компилятор строит код программы так, чтобы эти данные были созданы и разрушены в нужные моменты работы программы).
По месту размещения:
1. существующие в памяти ЭВМ (или внутренние) – ими могут быть все ранее рассмотренные примеры структур данных;
2. хранящиеся на внешних носителях (внешних ЗУ) – файлы и системы файлов.
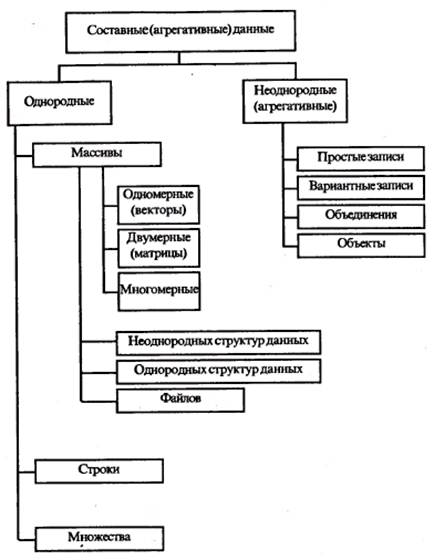
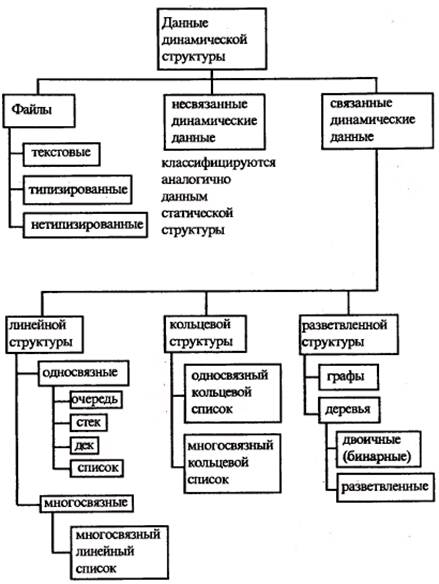
Приведём ещё один вариант классификации структур данных, совпадающий до некоторой степени с рассмотренным и представленный на рисунках:
Рис. 1.1. Простые статические структуры данных
Рис. 1.2. Составные статические структуры данных
Рис. 1.3. Динамические структуры данных
Базовой единицей информации является бит, который может принимать одно из двух взаимоисключающих значений.Для представления двух возможных состояний некоторого бита используются двоичные цифры – нуль и единица [слово " бит " ( английское bit ) есть сокращение от английских слов "двоичная цифра" ( binary digit )]. Более крупной единицей информации является байт. Группы смежных битов объединяются в поле. Поле, состоящее из 8 битов называется байтом, причем левый двоичный разряд имеет наибольший вес и считается старшим разрядом, а правый разряд – наименьший вес (младшим разрядом). Нумерация разрядов байтов осуществляется слева направо и начинается с нуля. Кроме 8 информационных битов байт может содержать дополнительный контрольный бит четности, невидимый для программиста.
Группа смежных байтов образуют поле байтов, характеризующееся длиной поля – числом входящих в него байтов и адресом поля – адресом старшего, самого левого, байта в поле, т.е. байта с наименьшим адресом. В общем случае поле байтов может иметь произвольную длину и адрес. Для некоторых частных видов полей имеются специальные названия:
– полуслово ( для поля, имеющего длину 2 байта),
– слово (4 байта) и
– двойное слово ( 8 байт ).
Графическое соотношение между битом, байтом, полусловом, словом, двойным словом для 16-разрядной вычислительной системы показано на рисунке.
Байт
Полуслово
Слово
Двойное слово
Рис. 1.4. Байты и машинные слова
Возможно также четверное слово, состоящее из двух двойных слов. Размер слова может определяться разрядностью системы. В 32-разрядной системе слово будет состоять из 4-х байт, а полуслово – из 2-х и, таким образом, не будет совпадать с байтом.
Поле байтов длиной 1024 байт имеет специальное обозначение – 1Кбайт, кроме того поле длиной 1024х1024 байт обозначается через 1Мбайт, а поле длиной 1024х1024х1024 через 1Гбайт.
Следует обратить внимание на то, что хотя здесь используются традиционные десятичные приставки «кило», «мега» и «гига» (а также, возможно, «тера»), они имеют значения не степеней числа 10 (103, 106 и 109 соответственно), а значения степеней числа 2 (210, 220=210 х 210 и 230 = 210 х 210 х 210). Такое использование десятичных приставок в двоичной системе счисления иногда приводит к неоднозначному толкованию значений данных. Например, емкость накопителей на жестких дисках может быть обозначена именно в десятичной системе счисления, и тогда объём в 10 Гбайт будет означать 10.000.000.000 байт, а не 10.737.418.240 байт. Как видно, разница составляет более 700 миллионов байт!