Проектирование баз данных информационных систем является достаточно трудоемкой задачей. Оно осуществляется на основе формализации структуры и процессов предметной области, сведения о которой предполагается хранить в БД. Различают концептуальное и схемно-структурное проектирование.
Концептуальное проектирование БД ИС является в значительной степени эвристическим процессом. Адекватность построенной в его рамках инфологической модели предметной области проверяется опытным путем, в процессе функционирования ИС.
· изучение предметной области для формирования общего представления о ней;
· выделение и анализ функций и задач разрабатываемой ИС;
· определение основных объектов-сущностей предметной области и отношений между ними;
· формализованное представление предметной области.
При проектировании схемы реляционной БД можно выделить следующие процедуры [14]:
· определение перечня таблиц и связей между ними;
· определение перечня полей, типов полей, ключевых полей каждой таблицы (схемы таблицы), установление связей между таблицами через внешние ключи;
· установление индексирования для полей в таблицах;
· разработка списков (словарей) для полей с перечислительными данными;
· установление ограничений целостности для таблиц и связей;
· нормализация таблиц, корректировка перечня таблиц и связей.
Проектирование БД осуществляется на физическом и логическом уровнях. Проектирование на физическом уровне реализуется средствами СУБД и зачастую автоматизировано.
Логическое проектирование заключается в определении числа и структуры таблиц, разработке запросов к БД, отчетных документов, создании форм для ввода и редактирования данных в БД и т. д.
Одной из важнейших задач логического проектирования БД является структуризация данных. Выделяют следующие подходы к проектированию структур данных [14]:
· объединение информации об объектах-сущностях в рамках одной таблицы (одного отношения) с последующей декомпозицией на несколько взаимосвязанных таблиц на основе процедуры нормализации отношений;
· формулирование знаний о системе (определение типов исходных данных и взаимосвязей) и требований к обработке данных, получение с помощью CASE-системы готовой схемы БД или даже готовой прикладной информационной системы;
· осуществление системного анализа и разработка структурных моделей.
Первый подход - классический.
Процесс проектирования начинается с выделения объектов-сущностей, информация о которых будет храниться в БД, и определения их атрибутов. Выделенные атрибуты объединяются в одной таблице (отношении).
Полная информация о сущности (таблица) дает избыточность (повторение) , Þ требуется преобразование , т.е. декомпозиция , т.е. разбиение на несколько таблиц, т.е. нормализация.
Þ Полученное отношение подвергается нормализации. Процедура нормализации является итерационной и заключается в последовательном переводе отношений из первой нормальной формы в нормальные формы более высокого порядка.
· усиленная третья нормальная форма, или нормальная форма Бойса-Кодда (БКНФ);
· четвертая нормальная форма (4НФ);
· пятая нормальная форма (5НФ).
(Требования к 2НФ)
соотносится только с первичным ключом. ÞКаждое данное хранится в БД только в 1ом месте. ÞДублируемые данные выносятся в др. таблицу, вместо них – внешние ключи.
(Требования к 3НФ)
Каждое неключевое поле не должно зависеть от другого неключевого поля (например, связь преподаватель-кафедра, или предмет-кафедра). Чтобы избежать, необходимо детально знать предметную область. Þ Убираем «факультет» из «Расписания», если там есть «Специальност».
3НФ обеспечивает декларативную ссылочность (данные из справочников).
(Требования к 4НФ)
и т.д.
Нормализация позволяет устранить информационную избыточность, которая приводит к аномалиям обработки данных.
Вместе с тем, следует различать неизбыточное и избыточное дублирование данных. Наличие первого из них в базах данных допускается. Приведем примеры обоих вариантов дублирования [49].
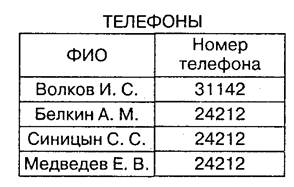
Пример неизбыточного дублирования данных представляет отношение «ТЕЛЕФОНЫ» (рис. 5.6) [49]. Предположим, что в одной комнате установлен только один телефон, тогда номера телефонов сотрудников, находящихся в одном помещении, совпадают. Номер телефона 24212 встречается несколько раз. В этом состоит дублирование. Однако для каждого сотрудника номер уникален и при удалении одного из номеров будет утеряна информация о том, по какому номеру можно дозвониться до того или иного сотрудника. В этом состоит неизбыточность.
Рис. 5.6. Неизбыточное дублирование данных
Избыточное дублирование данных имеет место в отношении «КОМНАТЫ», в которое добавлен атрибут «Номер комнаты» (рис. 5.7) [49].
ФИО
Номер телефона
Номер комнаты
Волков И. С.
Белкин А. М.
Синицын С. С.
Медведев Е. В.
Рис. 5.7. Избыточное дублирование данных
Сотрудники Белкин, Синицын и Медведев находятся в одной комнате и, следовательно, имеют одинаковые номера. То есть номер телефона Синицына и Медведева можно узнать из кортежа со сведениями о Белкине. В этом и состоит избыточность дублирования данных.
Избыточное дублирование данных приводит к проблемам обработки кортежей отношения, названным Э. Коддом «аномалиями обновления отношения».
Аномалии - такие ситуации в таблицах БД, которые приводят к противоречиям в БД или существенно усложняют обработку данных [49].
Выделяют три основных вида аномалий:
· аномалии модификации (редактирования);
· аномалии удаления;
· аномалии добавления.
Аномалии модификации проявляются в том, что изменение значения атрибута может повлечь за собой пересмотр всей таблицы с соответствующим изменением значений этого атрибута в других записях таблицы.
Так, изменение номера телефона в комнате 325 (рис. 5.7) [49] потребует пересмотра всей таблицы «КОМНАТЫ» и изменения значений атрибута «Номер телефона» в записях, в которых встречается этот номер.
Аномалии удаления проявляются в том, что при удалении какого-либо значения атрибута исчезнет другая информация, которая не связана напрямую с удаляемым значением.
Так, удаление записи о сотруднике Волкове (например, по причине увольнения) приводит к исчезновению информации о номере телефона, установленного в 320-й комнате (см. рис. 5.7).
Аномалии добавления проявляются в том, что невозможно добавить запись в таблицу, пока не будут известны значения всех ее атрибутов, а также в том, что вставка новой записи потребует пересмотра всей таблицы.
Например, в таблице «КОМНАТЫ» (см. рис. 5.7) невозможно отразить информацию о комнате с установленным в ней телефоном до тех пор, пока в нее не помещен ни один сотрудник (при условии, что поле «ФИО» является ключевым).
Кроме того, при добавлении в таблицу информации о новом сотруднике необходимо проверять таблицу на предмет противоречий, которые могут возникнуть при ошибочном вводе номера телефона или комнаты. Пример противоречия: сотрудники находятся в одной комнате, но имеют разные номера телефонов.
Способом устранения избыточного дублирования и нейтрализации аномалий является декомпозиция, то есть разбиение исходного отношения (таблицы). Декомпозиция должна быть обратимой, то есть осуществляться без потери информации