Концепция предполагает изложение основных положений чего-либо. Описание концепции БД невозможно выполнить без учета хронологии.
1. Инженерные и экономические задачи. Первоначально (начало 60-х г. XXв.) использовалась файловая система хранения. Для решения преимущественно инженерных задач, характеризующихся небольшим количеством данных и значительным объемом вычислений, данные хранились непосредственно в программе. Применялся последовательный способ организации данных, имелась их высокая избыточность, идентичность логической и физической структур и полная зависимость данных.
С появлением экономико-управленческих задач (информационная система руководства — M1S), отличающихся большими объемами данных и малой долей вычислений, указанная организация данных оказалась неэффективной. Требовалось упорядочение данных, которое, как выяснилось, возможно было проводить по двум критериям: использование (информационные массивы); хранение (базы данных).
2. Информационно-поисковые и информационно-советующие системы управления. Следует отметить, что экономические задачи часто связаны с управлением организационными системами. По характеру применения компьютеров такие системы возможно разделить на информационно-поисковые (рис.1), получившие также название «традиционные», и информационно-советующие или современные (рис.2) системы.
Рис. 1. Информационно-поисковая система
Рис. 2. Информационно-советующая система
3. Информационные массивы и базы данных. Первоначально в информационно-поисковых системах применяли информационные массивы. При этом возникала необходимость хранения избыточной информации при дефиците компьютерной памяти. Выяснилось так же, что алгоритмы задач более подвижны, чем данные для них. При довольно частом изменении алгоритмов в процессе совершенствования систем управления каждый раз требовалось проводить трудоемкую процедуру создания новых массивов. В этих условиях стало ясно превосходство баз данных, несмотря на их более сложную структуру по сравнению с системой массивов. В дальнейшем базы данных стали снабжаться программной составляющей, позволяющей легко реализовать и оперативно изменять алгоритмы приложения.
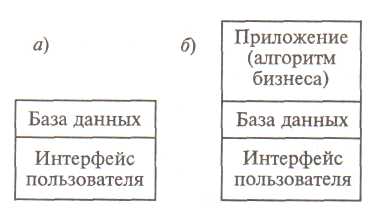
4. Модели данных. Использование файлов для хранения только данных (рис.3,а) предложено МакГри в 1959 г. Были разработаны методы доступа (в том числе — произвольного) к таким файлам, при этом физическая и логическая структуры уже различались, а физическое расположение данных можно было менять без изменения логического представления.
В 1963 г. С. Бахман построил первую промышленную базу данных IDS с сетевой моделью данных, которая все еще характеризовалась избыточностью данных и ее использованием только для одного приложения.
Рис. 3. Файловая система (а) и СУБД (б) для хранения данных
Доступ к данным осуществлялся с помощью соответствующего программного обеспечения.
В 1969 г. сформировалась группа, создавшая набор стандартов CODASYL (КОДАСИЛ) для сетевой модели данных. Фактически начала тогда использоваться (рис.3,6) современная архитектура базы данных. Существенный скачок в развитии технологии баз данных произошел в 1970 г., когда Э. Кодд предложил парадигму реляционной модели данных. Под парадигмой понимается научная теория, воплощенная в систему понятий, отражающих существенные черты действительности. Теперь логические структуры могли быть получены из одних и тех же физических данных, т. е. доступ к одним и тем же физическим данным мог осуществляться различными приложениями по разным путям. Стало возможным обеспечение целостности и независимости данных.
В конце 70-х годов XX в. появились современные СУБД, обеспечивающие физическую и логическую независимость, безопасность данных, обладающие развитыми языками БД.
В начале 90-х годов реляционные БД получили наиболее широкое распространение, особенно при использовании персональных компьютеров. Появились разнообразные СУБД, рассчитанные как на пользователя-профессионала (в программировании), так и на пользователя-непрофессионала, предназначенные для построения и небольших (по объему памяти), и сверхбольших БД, работающие как в локальном, так и в сетевом режимах. При этом базы данных строились как статические (в зарубежной терминологии — операционные, транзакционные, Online Transactional Processing — OLTP).
К середине 90-х годов в базах данных накопилось такое количество информации, что ее стало возможным использовать для аналитических процедур выработки решений-советов. Появились динамические (аналитические) базы данных, называемые за рубежом Online Analytical Processing — OLAP. Их основными составляющими стали электронный архив и хранилище данных (Data Warehouse).
Одновременно выявились недостатки реляционных БД, у которых появились конкуренты в виде объектно-ориентированных баз данных.
Последнее десятилетие характеризуется появлением распределенных и объектно-ориентированных баз данных, характеристики которых определяются приложениями средств автоматизации проектирования и интеллектуализации БД.
Прежде, чем рассматривать процедуры работы с базой данных, дадим набор характеристик БД и пояснения к нему.
5. Подходы к построению БД. Они базируются на двух подходах к созданию автоматизированной системы управления (АСУ). Первый из них, широко использовавшийся в 80-е годы и потому получивший название классического (традиционного), связан с автоматизацией документооборота (совокупность документов, движущихся в процессе работы предприятия). Исходными и выходными координатами являлись документы, как это видно из примера 1. Трансформация входных документов в выходные осуществляется по алгоритму преобразования.
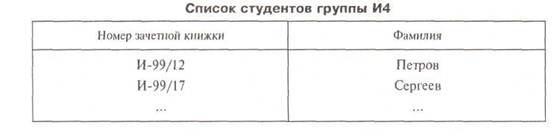
Пример1. Задача ставится следующим образом. Имеется система ручных документов, форма одного из которых показана в табл. 1. Необходимо с помощью БД получить — по регламенту или по запросу — информацию в виде другой системы документов, форма одного из которых приведена в табл. 2.2.
Таблица 1
Таблица 2
Использовался следующий тезис. Данные менее подвижны, чем алгоритмы, поэтому следует создать универсальную БД, которую затем можно использовать для любого алгоритма. Однако вскоре выяснилось, что создание универсальной БД проблематично. Господствовавшая до недавнего времени концепция интеграции данных при резком увеличении их объема оказалась несостоятельной. Более того, стали появляться приложения (например, текстовые, графические редакторы), базирующихся на широко используемых стандартных алгоритмах. Выявились стандартные алгоритмы и в управлении (бизнесе), как это следует из примера 2.
Пример 2. Используем компьютер для поддержки процедуры принятия решений менеджера в процедуре принятия специалистов на работу (комплектование кадрами исследовательской фирмы). Часть людей уже работает (в штате фирмы), необходимо провести доукомплекацию кадров. На основе анкетных данных о претендентах на вакантные места штатного расписания компьютер, в соответствии с заложенной проектировщиком системой правил, выдает менеджеру решения—советы о должностях, на которые следует принять поступающих. Окончательное решение остается за менеджером.
Если менеджер сомневается в правильности полученного компьютером решения, он может запросить объяснение в виде системы использованных при решении правил.
Если количество рекомендованных к приему превышает число вакансий в штатном расписании, менеджер может скорректировать либо правила (количественную составляющую), либо результаты их работы. Решения менеджера вводятся в компьютер.
Перечисленные процедуры имеют место на каждом из нескольких (по умолчанию — из трех) интервалов (циклов) времени.
В завершение компьютер выдает на экран итоговые результаты работы менеджера.
К 90-м годам XX в. сформировался второй, современный подход, связанный с автоматизацией управления. Он предполагает первоначальное выявление стандартных алгоритмов приложений (алгоритмов бизнеса в зарубежной терминологии), под которые определяются данные, а стало быть, и база данных. Объектно-ориентированное программирование только усилило значимость этого подхода. Состав БД для различных подходов представлен на рис.4.
Рис. 2.4. Схема классического (а) и современного (б) подхода при построении БД
В работе БД возможны одно- и многопользовательский режимы. В последнем случае несколько пользователей подключаются к одному компьютеру через разные порты.
6. Восходящее и нисходящее проектирование БД. Первое применяют в распределенных БД при интеграции спроектированных локальных баз данных, которые могут быть выполнены с использованием различных моделей данных. Более характерным для централизованных БД является нисходящее проектирование.
В последующих лекциях первоначально будет рассмотрен классический подход для централизованных БД, а затем — современный. Распределенным БД посвящены заключительные лекции.
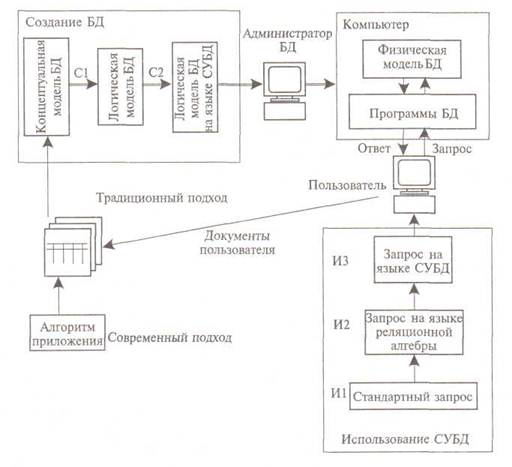
Работа с базами данных может быть представлена в виде схемы, приведенной на рис.5. Из нее видно, что следует выделять методологию создания, методологию использования и методологию функционирования БД.
Рис. 5. Этапы создания (Cl, C2) и использования (И1— ИЗ) БД
Методология БД определяется в процедуре проектирования, но проявляется и в процедуре использования.
7. Хранилище данных — предметно-ориентированный, интегрированный, привязанный ко времени и неизменный набор данных, предназначенный для поддержки принятия решений. В соответствии с определением хранилище данных ориентировано не на алгоритм приложения, как (операционная) БД, а на предметную область.
Интегрированность определяется тем фактом, что источниками данных могут быть несколько БД, которые могут иметь разные форматы данных и степень заполнения БД. Эти данные должны быть приведены к «стандарту», используемому в ХД.
Привязка ко времени означает, что исходные данные характеризуют какой-то интервал времени, при этом время присутствует в БД явно. В силу этого вновь поступающие данные не изменяют прежние данные в ХД, а дополняют их.

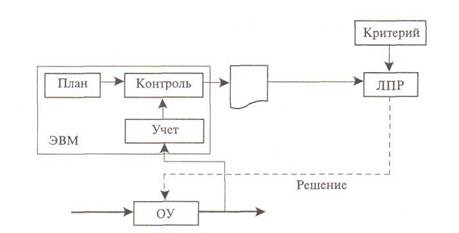 2. Информационно-поисковые и информационно-советующие системы управления. Следует отметить, что экономические задачи часто связаны с управлением организационными системами. По характеру применения компьютеров такие системы возможно разделить на информационно-поисковые (рис.1), получившие также название «традиционные», и информационно-советующие или современные (рис.2) системы.
2. Информационно-поисковые и информационно-советующие системы управления. Следует отметить, что экономические задачи часто связаны с управлением организационными системами. По характеру применения компьютеров такие системы возможно разделить на информационно-поисковые (рис.1), получившие также название «традиционные», и информационно-советующие или современные (рис.2) системы.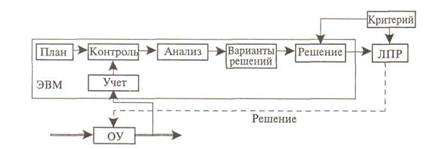
 В 1963 г. С. Бахман построил первую промышленную базу данных IDS с сетевой моделью данных, которая все еще характеризовалась избыточностью данных и ее использованием только для одного приложения.
В 1963 г. С. Бахман построил первую промышленную базу данных IDS с сетевой моделью данных, которая все еще характеризовалась избыточностью данных и ее использованием только для одного приложения. Таблица 1
Таблица 1