Для каждого продавца и его подчиненных вывести максимальную из минимальных стоимостей сделок по каждой дате.
Для каждого продавца и его подчиненных вывести максимальную из средних стоимостей сделок по каждой дате.
Для каждого продавца и его подчиненных вывести среднюю из минимальных стоимостей сделок по каждой дате.
Для каждого продавца и его подчиненных вывести среднюю из максимальных стоимостей сделок по каждой дате.
В главе «1.2. Технологии управления данными» OLAP рассматривалась в сравнении с другими технологиями управления данными. Было дано определение OLAP и хранилищ данных, приведены примеры задач и многомерный куб (см. Рис. 4). Рассмотрим эту технологию подробнее.
Хранилище данных(англ. Data Warehouse) — очень большая предметно-ориентированная информационная корпоративная БД, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес-процессов с целью поддержки принятия решений в организации. Строится на базе клиент-серверной архитектуры, СУБД и утилит поддержки принятия решений. Данные, поступающие в хранилище данных, становятся доступны только для чтения. Данные из OLTP-системы копируются в хранилище данных таким образом, чтобы построение отчётов и OLAP-анализ не использовал ресурсы промышленной системы и не нарушал её стабильность. Данные загружаются в хранилище с определённой периодичностью, поэтому их актуальность несколько отстает от OLTP-системы.
Свойства хранилищ данных:
Проблемно-предметная ориентация: данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые используют данные.
Интегрированность: объединяет данные таким образом, чтобы они удовлетворяли всем требованиям всего предприятия, а не единственной функции бизнеса.
Некорректируемость: данные в хранилище не создаются, а поступают из внешних источников, не корректируются и не удаляются.
Зависимость от времени: данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени.
Хранилище данных обычно содержит очень большой массив данных и зачастую разделяется на подмножества, называемые витрины данных(англ. Data Mart; другие варианты перевода: хранилище данных специализированное, киоск данных, рынок данных) — подмножества хранилища данных, представляющие собой массив тематической, узконаправленной информации, ориентированный, например, на пользователей одной рабочей группы или отдела.
Примером витрины данных является трехмерный куб, приведенный на Рис. 4, содержащий три измерения: продавцов, товаров и времени, в ячейках которого хранится информация о суммарном количестве товара, который продавец продал в единицу времени. Этот куб может быть построен над РБД (OLTP-система) и не требует специализированного хранилища. В принципе, он может быть реализован (по крайней мере, для выборки данных) на клиентском компьютере. Это пример настольного OLAP. Представителями настольного OLAP являются продукты, необязательно соединяющиеся с сервером. Они могут запускаться на клиентской части, хотя данные в форме куба могут загружаться и с сервера. Тот факт, что куб данных строится и хранится на машине пользователя, позволяет рекомендовать технологию тем, кто часто использует портативные компьютеры или кто редко запускает сложные отчеты. Архитектура настольного OLAP изображена на Рис. 16.
Рис. 16. Архитектура настольного OLAP
Во многих случаях вариант настольного OLAP может быть неэффективен. Данных может быть много и клиентский компьютер не справится с таким объемом данным. А перенос формирования куба на сервер OLTP может затормозить текущие транзакции. Кроме того, не всегда БД OLTP спроектирована подходящим образом для OLAP. Например, в таблице «Товары» на Рис. 3 есть атрибут –количество товара на складе (в текущий момент времени). Данные OLTP могут изменяться. Для анализа нам необходимы неизменяемые данные. Нужно, чтобы ИС делала с определенной периодичностью, например, раз в день, «снимки» БД OLTP и помещала нужную информацию в хранилище данных. Таким образом, для нашего примера нужно создать в хранилище данных витрину для отдела логистики, представляющую собой двумерный куб с измерениями «Даты» и «Товары». Архитектура информационной системы представлена на Рис. 17.
Рис. 17. Информационная система с OLTP и OLAP
Есть три архитектуры хранилища данных:
MOLAP(Multidimensional OLAP) - и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
ROLAP(Relational OLAP) - детальные данные остаются там, где они “жили” изначально - в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
HOLAP(Hybrid OLAP) - детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
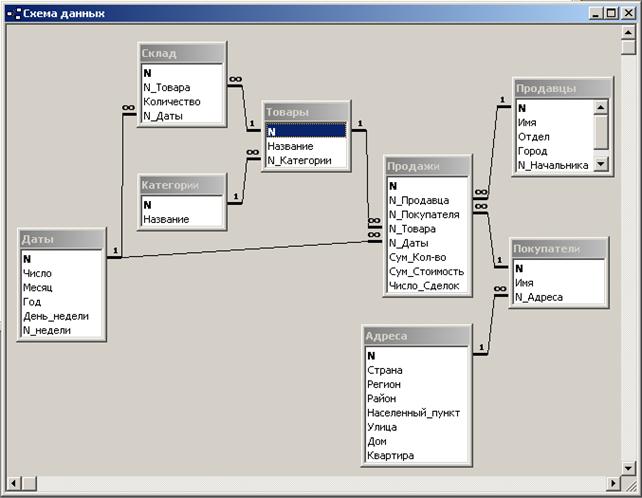
Если мы проектируем витрину логистики по архитектуре ROLAP, то она имеет структуру, изображенную на Рис. 18. Такой вариант построения схемы данных называется «звезда». Она состоит из таблицы фактов, обрамленной таблицами измерений. Таблица фактов имеет следующие атрибуты: суррогатный ключ, внешние ключи измерений и фактические данные (в нашем случае – атрибут «количество»). Таблицы измерений состоят из суррогатных ключей, возможно - названий и атрибутов агрегации, например, в таблице «даты» N – суррогатный ключ, остальные - атрибуты агрегации.
Рис. 18. Топология «звезда»
Иногда в БД в нормализованном виде некоторые атрибуты агрегации вынесены в отдельные таблицы, например – атрибут «Категория» из таблицы «Товары» (см. Рис. 19). Такая схема данных называется «снежинкой». В случае сложных схем БД для ускорения запросов их могут денормализовывать до схемы «звезда».
Рис. 19. Топология «снежинка»
Создание витрины отдела продаж по технологии ROLAP на основе таблицы «Сделки» из БД на Рис. 3 связано со следующей проблемой: при снимке таблицы «сделки» раз в сутки может оказаться, что данный продавец продал один и тот же товар одному и тому же покупателю несколько раз. В таком случае мы должны помещать в хранилище агрегированные данные (таблица «Сделки» отображается в таблицу «Продажи»). Наряду с суммами в ячейках OLAP-куба могут содержаться результаты выполнения иных агрегатных функций языка SQL, таких как MIN, MAX, AVG, COUNT, а в некоторых случаях — и других (дисперсии, среднеквадратичного отклонения и т.д.). Для описания значений данных в ячейках используется термин summary(в общем случае в одном кубе их может быть несколько), для обозначения исходных данных, на основе которых они вычисляются, — термин measure, а для обозначения параметров запросов — термин dimension(переводимый на русский язык обычно как "измерение", когда речь идет об OLAP-кубах, и как "размерность", когда речь идет о хранилищах данных). Значения, откладываемые на осях, называются членами измерений (members). Видно, что для полной витрины отдела продаж на Рис. 4 не хватает измерения «покупатели». На Рис. 20 показана схема хранилища ROLAP, соответствующая двум витринам – логистической и отдела продаж. У этих двух витрин есть два общих измерения – Товары и Даты. Такие измерения называются коллективными.
Рис. 20. Схема ROLAP
В отличие от ROLAP в MOLAP резервируется ячейка памяти для продавца, товара и даты, даже если продавец не продал данный товар в заданную дату (модель MOLAP), что требует избыточного объема памяти. Если посмотреть на БД Рис. 3, то в таблице «Продавцы» есть еще атрибут «Зарплата». Для представления зарплаты в хранилище требуется создать еще одну витрину – «отдел катров».
Говоря об измерениях, следует упомянуть о том, что значения, наносимые на оси, могут иметь различные уровни детализации. Например, нас могут интересовать продажи по городу, по отделу или даже продажи, выполненные отдельным продавцом. Эта иерархия представлена на Рис. 21, такие иерархии называются сбалансированными. Возможность получения агрегатных данных с различной степенью детализации соответствует одному из требований, предъявляемых к хранилищам данных, — требованию доступности различных срезов данных для сравнения и анализа.
Рис. 21. Сбалансированная иерархия
Если в иерархии уровни выделяются, но в конкретных случаях представители некоторых слоев могут отсутствовать, то такие иерархии называются неровными. Пример неровной иерархии – измерение «адрес», см. Рис. 22.
Рис. 22. Неровная иерархия
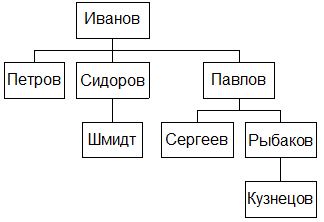
В несбалансированных иерархияхв каждой веточке может быть разное число уровней. Типичный пример несбалансированной иерархии — иерархия типа "начальник-подчиненный" (см. Рис. 23). Обычно такие иерархии возникают при рекурсивных связях. Иногда для таких иерархий используется термин Parent-child hierarchy (Иерархия «родитель-потомок»).
Рис. 23. Несбалансированная иерархия
Некоторые измерения могут иметь альтернативные иерархии. Например, измерение «Даты» могут группироваться следующим образом: число, месяц, год или день недели, номер недели, год.
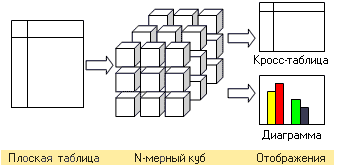
Витрина отдела продаж представляет собой четырехмерный куб. даже трехмерные кубы представлять непросто. Разработчиками предложено много инструментов для создания различных отчетов, кросс-таблиц и диаграмм, представляющих собой срезы многомерных кубов. Схема работы OLAP приведена на Рис. 24.
Рис. 24. Схема работы OLAP-системы
Продукты питания
Бытовая химия
Москва
Екатеринбург
Москва
Екатеринбург
Январь
Опт
Розница
Февраль
Опт
Розница
Кросс таблица строится следующим образом: выбирается нужный уровень детализации, затем измерения разбиваются на две группы. Первая группа откладывается по оси абсцисс, другая – ординат (см. Рис. 25).
Рис. 25. Кросс-таблица
Подробнее об OLAP см. [5, 6, 7]
Д/З 7. Для примера из Д/З 2 увеличьте хранилище данных двумя витринами данных. Для одной витрины используйте топологию «звезды», для другой – «снежинки» В примерах используйте измерения разного вида: коллективные, сбалансированные, неполные, несбалансированные. Приведите пример кросс-таблицы.
Вопросы для самопроверки:
1. Обязательно ли для OLAP хранилище данных?
2. Чем ROLAP отличается от HOLAP?
3. Чем топология «звезда» отличается от «снежинки»?
4. Нужна ли нормализация БД для ROLAP?
5. Чем несбалансированная иерархия отличается от неполной?