Еще одним распространенным случаем применения инструкции ALTER TABLE является изменение или добавление определений первичных и внешних ключей таблицы. Так как поддержка первичных и внешних ключей включена во многие новые реляционные СУБД, данная форма инструкции ALTER TABLE является особенно полезной. С ее помощью можно информировать СУБД о межтабличных связях, уже существующих в базе данных, но не определенных явно.
Используя инструкцию ALTER TABLE, определения первичного и внешних ключей (в отличие от определений столбцов) можно как добавлять в таблицу, так и удалять из нее. Предложения, добавляющие определения первичного и внешнего ключей, являются точно такими же, как в инструкции CREATE TABLE, и выполняют те же функции. Предложения, удаляющие первичный или внешний ключи, являются довольно простыми, как видно из приведенных ниже примеров. Отметим, что удалить внешний ключ можно только тогда, когда создаваемая им связь имеет имя (напомним, что ограничения, возможно, именовать посредством предложения CONSTRAINT инструкции CREATE TABLE, примерами “именованных” внешних ключей являются, например TAKEN_BY или IS_FOR приведенного выше демонстрационного примера с иллюстрацией отношений предок/потомок таблиц). Если имя присвоено не было, то задать эту связь в инструкции ALTER TABLE невозможно. В этом случае для удаления внешнего ключа необходимо удалить таблицу и воссоздать ее в новом формате. Вот пример, где в существующую таблицу добавляется определение внешнего ключа:
alter table salesreps
add constraint works_in
foreign key (region) references regions;
20. ПСЕВДОНИМЫ ТАБЛИЦ (ИНСТРУКЦИИ CREATE / DROP SYNONYM)
Промышленные базы данных часто бывают организованы так, что все основные таблицы собраны вместе и принадлежат администратору. Администратор базы данных дает другим пользователям разрешения на доступ к таблицам, руководствуясь правилами обеспечения безопасности. Поэтому и только в случае получения разрешения на доступ к таблицам другого пользователя, для ссылки на них необходимо использовать полные имена таблиц. На практике это означает, что в каждом запросе к таким таблицам следует указывать полные имена таблиц, в результате чего запросы становятся длинными, а их ввод – утомительным:
Для решения этой проблемы во многих СУБД вводится понятие псевдонима или синонима. Псевдоним – это назначаемое пользователем имя, которое заменяет имя некоторой таблицы.
В ORACLE для создания псевдонимов используется инструкция CREATE SYNONYM. В других СУБД для аналогичных целей используется инструкция CREATE ALIAS.
После создания псевдонима его можно использовать в запросах SQL как обычное имя таблицы. Применение псевдонимов смысл запроса не изменяет, так как и в этом случае необходимо иметь разрешение на доступ к таблицам других пользователей. Тем не менее, псевдонимы упрощают инструкции SQL, и последние приобретают такой вид, как если бы вы обращались к своим собственным таблицам. Если позднее вы решите, что больше не нуждаетесь в псевдонимах, то можете их удалить посредством инструкции DROP ALIAS.
21. ИНДЕКСЫ (ИНСТРУКЦИИ CREATE/DROP INDEX)
Одним из структурных элементов физической памяти, присутствующим в большинстве реляционных СУБД, является индекс. Индекс – это средство, обеспечивающее быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов. На рисунке 20 изображена таблица STAFF и два созданных для нее индекса. Один из индексов обеспечивает доступ к таблице на основе столбца LNAME. Другой обеспечивает доступ на основе первичного ключа таблицы (SNO).
СУБД пользуется индексом так же, как читатели пользуетесь предметным указателем книги. В индексе хранятся значения данных и указатели на строки, где эти данные встречаются. Данные в индексе располагаются в отсортированном по убыванию или возрастанию порядке, чтобы СУБД могла быстро найти требуемое значение. Затем по указателю СУБД может быстро локализовать строку, содержащую искомое значение.
Рисунок 20 Индексы таблицы БД
Наличие или отсутствие индекса совершенно незаметно для пользователя, обращающегося к таблице. Рассмотрим, например, такую инструкцию SELECT:
select tel_no, address
from staff
where lname = ‘Комаров’;
В инструкции ничего не говорится о том, имеется ли индекс для столбца LNAME или нет, и СУБД выполнит запрос в любом случае.
Если бы индекса для столбца LNAME не существовало, то СУБД была бы вынуждена выполнять запрос путем последовательного “сканирования” таблицы STAFF, строка за строкой, просматривая в каждой строке столбец LNAME. Для получения гарантии того, что она нашла все строки, удовлетворяющие условию отбора, СУБД должна просмотреть каждую строку таблицы. Если таблица имеет сотни тысячи строк, то ее просмотр может занять достаточно много времени.
Если для столбца LNAME имеется индекс, СУБД находит требуемые данные с гораздо меньшими усилиями. Она просматривает индекс, чтобы найти требуемое значение, а затем с помощью указателя находит требуемую строку (строки) таблицы. Поиск в индексе осуществляется достаточно быстро, так как индекс отсортирован (сортировка “строковых” столбцов осуществляется в лексикографическом порядке) и его строки достаточно коротки. Переход от индекса к строке (строкам) также происходит довольно быстро, поскольку в индексе содержится информация о том, где на диске располагается эта строка (строки).
Как видно из этого примера, индекс имеет то преимущество, что он в огромной степени ускоряет выполнение инструкций с условиями отбора, имеющими ссылки на индексный столбец (столбцы). К недостаткам индекса относится то, что, во – первых, он занимает на диске дополнительную память и, во – вторых, индекс необходимо .обновлять каждый раз, когда в таблицу добавляется строка или обновляется индексный столбец таблицы. Это требует дополнительных затрат на выполнение инструкций INSERT и UPDATE, которые обращаются к данной таблице.
В общем-то, полезно создавать индекс лишь для тех столбцов, которые часто используются в условиях отбора. Индексы удобны также в тех случаях, когда инструкции SELECT обращаются к таблице гораздо чаще, чем инструкции INSERT и UPDATE. СУБД всегда создает индекс для первичного ключа таблицы, так как ожидает, что доступ к таблице чаще всего будет осуществляться через первичный ключ.
В стандартах SQL ничего не говорится об индексах и о том, как их создавать. Они относятся к “деталям реализации”, выходящим за рамки ядра языка SQL. Тем не менее, индексы весьма важны для обеспечения требуемой производительности любой серьезной, корпоративной или промышленной, базы данных.
На практике в большинстве популярных СУБД (включая ORACLE, SQServer, INFORMIX, SYBASE) для создания индекса используется та или иная форма инструкции CREATE INDEX (рисунок 21). В инструкции указывается имя индекса и таблица, для которой он создается. Задается также индексируемый столбец и порядок его сортировки (по возрастанию или убыванию, на приведенной диаграмме данная возможность не отражена с целью придания ей по – возможности “большей” универсальности).

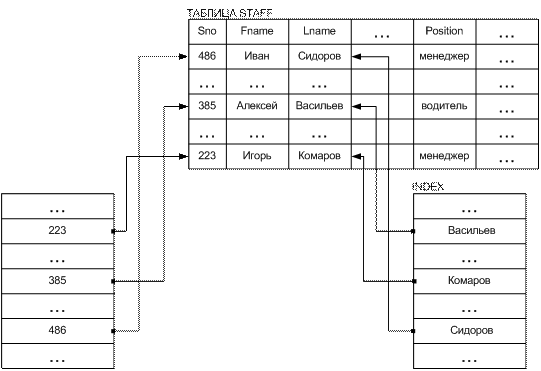
 Рисунок 21 Синтаксическая диаграмма инструкции
Рисунок 21 Синтаксическая диаграмма инструкции