Для расширения возможностей языка UML существует несколько механизмов и все они предназначены для того, чтобы разработчики могли адаптировать язык моделирования к своим конкретным нуждами не меняли при этом его метамодель. Механизмы расширения были спроектированы таким образом, чтобы инструменты моделирования могли их обрабатывать и сохранять, не обращая внимания на их семантику. По этой причине расширения могут обрабатываться и сохраняться в виде текстовых строк. Для инструментов моделирования, которые не понимают и не обрабатывают такое расширение языка, оно является всего лишь строкой текста. Эта строка сохраняется в виде части модели и может быть передана при необходимости другим инструментам. Так как любое расширение языка является отклонением от стандартов UML и может привести к появлению нового, не понятного для остальных диалекта этого языка, то прежде всего следует убедиться, что в стандартном языке нет возможностей для реализации этих особенностей.
Для расширения возможностей языка UML служат ограничения, именованные значения и стереотипы.
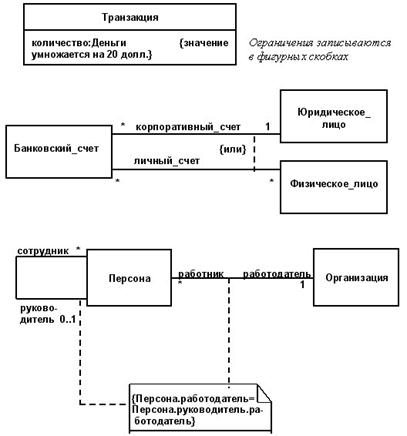
Ограничение. Ограничение (constraint) — это семантические условия, оформленные в виде текстового выражения. Каждое выражение интерпретируется каким-то языком. Это может быть формальная математическая нотация, некий компьютерный язык ограничений (например, OCL), язык программирования (например, C++), псевдокод или естественный язык (в последнем случае такие ограничения должны интерпретироваться людьми). Даже если ограничения выражены формальным языком, они не будут автоматически обрабатываться — пока это находится за пределами возможностей программирования. Однако, по крайней мере семантика этих ограничений будет передана в точности.
Ограничения определяют те отношения, которые невозможно выразить с помощью UML-нотации. Как правило, их используют для описания условий, которые влияют на работу нескольких элементов системы.
На диаграммах ограничения имеют вид текстовых строк, заключенных в фигурные скобки. Их можно отнести к списку элементов, присоединить к зависимости или записать в примечании (рис.29).
Рис 29. Ограничения
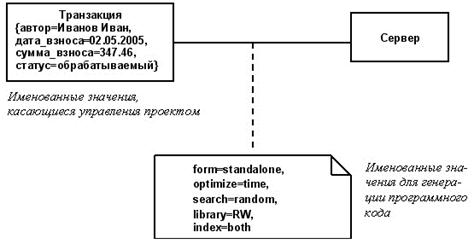
Именованные значения. Именованное значение (tagged value) — это две строки, в которых хранится информация о каком-либо элементе системы. Одна строка предназначается для имени (тег), другая — для содержимого (например, первая строка — автор, вторая — Джек Лондон). Таким образом, именованные значения могут нести информацию о любом элементе модели.
В именованных значениях располагается дополнительная информация об элементах системы. Особенно удобно хранить так информацию об управлении проектом (время создания элемента, статус разработки или тестирования, время окончания работы над ним и т.п.). В качестве имени тега можно использовать любую строку, кроме встроенных атрибутов метамодели, так как инструмент моделирования может неправильно это интерпретировать. Ряд таких имен в языке UML предопределен.
С помощью именованных значений можно указывать дополнительную информацию, касающуюся реализации элементов в программном коде. Как правило, существует несколько вариантов корректной реализации модели. Поэтому, чтобы создать программный код на основе модели, генератору кода потребуется дополнительная информация о том, какой из возможных вариантов выбрать. Эта дополнительная информация как раз и будет содержаться в именованном значении. Другие именованные значения могут хранить информацию для прочих дополнительных средств: генераторов отчетов и инструментов планирования. Кроме этого именованные значения несут информацию о стереотипах.
Именованные значения записываются в виде: тег - значение. Обычно все выражение заключено в фигурные скобки (рис. 30). На диаграммах именованные значения, как правило, опускаются, но указываются во всплывающих списках и формах.
Рис 30. Именованные значения
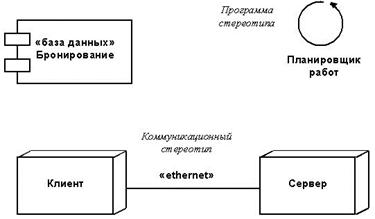
Стереотипы. Стереотип (stereotype) — это новый вид элемента модели, который определяется на основе уже существующего элемента. По содержанию и форме стереотип совпадает с этим существующим элементом, однако имеет другое значение и по-другому используется. Например, при проектировании бизнес-моделей разработчик может захотеть отделить бизнес-объекты от бизнес-процессов. И те, и другие представлены в виде отдельных видов элементов модели, причем каждый будет по-разному использоваться в рамках одного процесса разработки. Такие элементы могут рассматриваться как специальный вид классов, у которых есть общие атрибуты и операции, а также специальные ограничения на их использование и на отношения с другими элементами модели.
Благодаря тому, что стереотип создается только на основе существующего элемента модели, инструмент моделирования может «узнавать» стереотип и обращаться с ним таким же образом, как он обращается с исходным элементом.
Стереотип может иметь отдельную пиктограмму — любому инструменту моделирования это нетрудно поддерживать. Например, стереотип «организация» можно изобразить в виде схематической группы людей.
Стереотипы нередко обладают своими собственными ограничениями. Так, например, наша «организация» может иметь ассоциации только с другими «организациями», но ни с какими другими классами.
Инструмент моделирования общего назначения далеко не всегда правильно обрабатывает такие ограничения, поэтому их приходится применять вручную или с помощью специальной программы, которая «понимает» стереотипы.
Дополнительные свойства стереотипа, которых нет у исходного элемента, можно хранить в именованных значениях.
На диаграммах стереотипы представлены в виде текстовых строк, взятых в угловые кавычки («»). Разработчик может также создать для стереотипа отдельную пиктограмму (в противном случае используется та же пиктограмма, что и у исходного элемента (рис. 31).
Рис 31. Стереотипы
Описанные механизмы расширения возможностей языка позволяют адаптировать UML к различным специфическим предметным областям. Когда некая предметная область адаптирует для своиex нужд язык моделирования, это значит, что в нем сохраняются все базовые понятия и концепции, которые делают новый диалект общепонятным. Вместе с тем следует учитывать, что адаптация языка моделирования к конкретному приложению или предметной области является рискованной операцией, так как получившийся в результате адаптации диалект может быть не понятен остальным.
Литература к главе 2:
1.
Буч Гради. Объектно-ориентированный анализ и проектирование с примерами приложений на С++. Второе издание - "Издательство Бином", "Невский диалект".