Как было сказано выше (см. раздел 1.4.2), в SPSS все многовариантные вопросы рассматриваются как совокупность одновариантных переменных, обозначающий варианты ответа. Иными словами, многовариантный вопрос, содержащий три варианта ответа, в SPSS представляется как три дихотомические переменные, принимающие два значения-флага: отмечено/не отмечено.
Наиболее распространены два формата представления многовариантных переменных. В первом случае переменные, представляющие варианты ответа многовариантной переменной, принимают значение 1 (выбрано) или 0 (не выбрано); во втором случае — 1 (выбрано) или System Missing (не выбрано).
Как показывает опыт, первый способ предпочтительнее. Второй способ используется в специфических случаях (например, если необходимо использовать SPSS в качестве клиента автоматизации построения распределений при помощи программ на Sax Basic). Чтобы указать SPSS, какие переменные являются вариантами ответа для многовариантной переменной, наиболее часто используется описываемый далее способ, при котором после формирования многовариантной переменной ее можно использовать для построения линейных и перекрестных распределений.
Для иллюстрации мы построим линейное распределение по многовариантному вопросу Где Вы покупаете сметану? (q7) с вариантами ответа:
1. продмаг (q7_l);
2. рынок (q7_2);
3. супермаркет (q7_3);
4. палатка (q7_4);
5. универсам (q7_5).
Чтобы построить распределения по многовариантным вопросам, прежде всего необходимо сформировать многовариантную переменную. Это делается при помощи меню Analyze ► Multiple Response ► Define Sets. Открывшееся диалоговое окно позволяет сформировать многовариантные переменные (правый список) из общего списка доступных переменных (левый список), как показано на рис. 2.10.
Рис. 2.10. Диалоговое окно Define Multiple Response Sets со сформированной многовариантной переменной Торговые точки
Для создания многовариантной переменной, обозначающей типы торговых точек, сначала выберите в левом списке все дихотомические переменные, кодирующие множественные варианты ответов (q7_l — q7_5), и переместите их в правый список. Далее в области Variables Are Coded As оставьте выбранный по умолчанию параметр Dichotomies (он указывает, что переменные, обозначающие варианты ответа в многовариантном вопросе, являются дихотомическими) и в соответствующее поле введите цифру, указывающую, что вариант ответа выбран (в нашем случае 1). В поле Name введите имя для вновь создаваемой многовариантной переменной. Назовите ее q7 и присвойте метку Торговые точки (в поле Label). Затем, чтобы создать новую переменную, щелкните на кнопке Add. Обратите внимание, что к именам создаваемых многовариантных переменных добавляется префикс $ (этим они отличаются от обычных одновариантных переменных). Теперь вы можете создать еще одну или несколько многовариантных переменных, добавляя их в соответствующий список при помощи кнопки Add. Так как в нашем случае мы собираемся анализировать только один многовариантный вопрос, завершим процесс создания новых переменных щелчком на кнопке Close.
Необходимо отметить, что SPSS не сохраняет многовариантные переменные при закрытии рабочего файла с данными. Поэтому каждый раз, когда нужно проанализировать многовариантные вопросы, вам придется снова создавать соответствующие переменные.
Мы создали многовариантную переменную для анализа и теперь можем приступать к построению линейных распределений. Для этого воспользуемся меню Analyze ► Multiple Response ► Frequencies. Следует отметить, что данное меню позволяет строить только таблицы линейных распределений (и нет возможности вывести диаграммы). В открывшемся диалоговом окне в левом списке всех доступных многовариантных переменных (в нашем случае там только одна переменная Торговые точки) выберите интересующие переменные для анализа и перенесите их в правую область Table(s) for (рис. 2.11). Для того чтобы запустить процедуру построения линейных распределений, щелкните на кнопке ОК.
В окне SPSS Viewer будет создана таблица с линейными распределениями (частотами) по выбранным переменным (рис. 2.12). Столбец Count содержит количество респондентов, указавших каждый из возможных вариантов ответа на многовариантный вопрос. Столбец Pet of Cases показывает доли каждого варианта ответа от общего числа респондентов, ответивших на многовариантный вопрос (гистограмма). Данное число показано под таблицей (999 valid cases, то есть линейное распределение построено по 999 респондентам) и рассчитано как количество анкет, в которых выбран хотя бы один из возможных вариантов ответа на данный многовариантный вопрос. В той же строке (под таблицей) указано количество анкет, в которых не выбрано ни одного варианта ответа (4 missing cases, то есть четыре респондента не указали, в каких типах торговых точек они обычно приобретают сметану). Столбец Pet of Responses показывает доли каждого варианта ответа от общего числа ответов; их сумма всегда равна 100 % (сектограмма). Суммы по каждому столбцу анализируемой таблицы представлены в строке Total responses.
Multiple Response
Group $Q7 Торговые точки
(Value tabulated = 1)
Pet of
Pet of
Dichotomy label
Name
Count
Responses
Cases
Продмаг
Q7_l
39,4
SI,9
Рынок
Q7_2
23,3
30,6
Супермаркет
Q7_3
19,6
25,8
Палатка
Q7_4
12,6
16,6
Универсам
Q7_5
5,0
6,6
------
-----------
-----------
Total responses
100,0
131,5
4 missing cases; 999 valid cases
Рис. 2.12. Таблица Multiple Response, отражающая результаты построения линейного распределения по многовариантной переменной Торговые точки
В связи с тем, что линейные распределения по многовариантным вопросам в SPSS выводятся в текстовом формате (Plain text) и не могут быть перенесены в Microsoft Excel для построения диаграмм, далее мы рассмотрим, как можно строить диаграммы по многовариантным вопросам непосредственно в SPSS.
Если вам необходимо построить гистограмму или сектограмму по многовариантному вопросу, меню Define Sets не используется. Вместо него применяется меню Graphs ► Bar (для гистограмм) или Graphs ► Pie (для сектограмм). За один раз можно построить гистограмму или сектограмму только по одной многовариантной переменной.
Итак, давайте построим гистограмму по многовариантной переменной Торговые точки (параллельно мы построим и сектограмму). Для этого воспользуемся меню Graphs ► Bar. В открывшемся диалоговом окне (рис. 2.13) необходимо указать тип гистограммы Simple (если мы строим сектограмму, данный пункт отсутствует; см. рис. 2.14), а в группе Data in Chart Are выбрать пункт Summaries of separate variables. Затем необходимо щелкнуть на кнопке Define, чтобы перейти к следующему шагу построения диаграммы.
Рис. 2.13. Диалоговые окна Bar Charts с выбранными параметрами для построения гистограмм и сектограмм по многовариантной переменной
В открывшемся диалоговом окне Summaries of Separate Variables (оно одинаково и для гистограмм и для сектограмм) из левого списка всех доступных переменных, имеющихся в файле данных, переместите в правый список все варианты ответа на какой-либо один многовариантный вопрос (в нашем случае это переменные q7_l — q7_5). как видно на рис. 2.15.
Рис. 2.14. Диалоговые окна Pie Charts с выбранными параметрами для построения гистограмм и сектограмм по многовариантной переменной
Рис. 2.15. Диалоговое окно Summaries of Separate Variables с выбранной для построения многовариантной переменной Торговые точки
Рис. 2.16. Диалоговое окно Summary Function
Рис. 2.17. Диалоговое окно Options
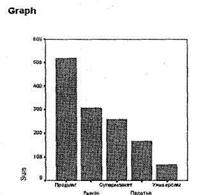
Рис. 2.18. Гистограмма по многовариантной переменной Торговые точки
Щелкните на кнопке Change Summary и в открывшемся диалоговом окне (рис. 2.16) выберите пункт Sum of values. Данный параметр указывает SPSS на необходимость построить гистограмму по суммарному количеству выбранных вариантов ответа в многовариантном вопросе. После этого закройте данное окно, щелкнув на кнопке Continue.
Теперь щелкните на кнопке Options и в открывшемся окне выберите пункт Exclude cases variable by variable; щелкните на Continue (рис. 2.17).
Щелкните на кнопке ОК в главном диалоговом окне Summaries of Separate Variables, и программа выведет результаты построения гистограммы в окне SPSS Viewer (рис. 2.18).
Как видите, столбцы построенной гистограммы отражают абсолютное количество респондентов, указавших ту или иную торговую точку. К сожалению, SPSS не позволяет строить гистограмму по многовариантным вопросам, отражающую проценты каждого варианта ответа от общего числа респондентов (или от общего числа ответов). Чтобы отобразить на нашей гистограмме точные количества респондентов, указавших ту или иную торговую точку, следует воспользоваться схемой действий, представленной выше.
Мы рассмотрели наиболее популярный метод статистического анализа данных в маркетинговых исследованиях — построение линейных распределений. Как показывает практика, именно на этом этапе в некоторых отечественных компаниях заканчивается работа с SPSS (иногда строятся также перекрестные распределения), в то время как описательный анализ является лишь начальным этапом анализа данных.
Цель анализа различий — выявление групп респондентов, статистически значимо различающихся между собой. Все статистические процедуры, относящиеся к группе процедур, которые позволяют выявить такие различия (t-тесты и дисперсионный анализ), сравнивают респондентов на основании средних значений переменных. Иными словами, провести различие можно на основании двух или более числовых переменных.
В практике маркетинговых исследований достаточно часто встречаются ситуации, когда в ходе предварительного анализа (на основании опыта исследователя, когнитивного или статистического анализа) появляется гипотеза о разделении всей выборочной совокупности на определенные группы на основании одного или нескольких признаков (например, при сегментировании потребителей продукта или при построении разрезов). Линейное распределение может показывать, что данные группы респондентов действительно различаются (например, мужчин в выборке в два раза больше, чем женщин). Однако визуального различия между категориями недостаточно для того, чтобы с уверенностью констатировать наличие статистически значимого различия. На установление статистической значимости различий между целевыми группами респондентов и направлены процедуры, объединенные под названием «Анализ различий».
Существует два основных метода определения различий между группами: t-тесты и дисперсионный анализ. Первый метод прост в использовании, и поэтому он применяется часто (в том числе и в маркетинговых исследованиях). Однако в связи с ограничением на количество тестируемых групп (между которыми устанавливается различие) t-тесты не могут применяться для решения всех задач, возникающих при проведении маркетингового анализа. Для преодоления данного ограничения используется дисперсионный анализ, являющийся универсальной методикой для определения статистически значимых различий между любым числом групп респондентов.
Т-тесты предназначены для установления различий между двумя группами респондентов. При этом сравниваются только два средних значения. SPSS предлагает три основных типа t-тестов:
■ для двух независимых выборок;
■ для двух зависимых выборок;
■ для одной выборки.
В последующих разделах мы подробно расскажем о каждом из них, но сначала приведем основные характеристики переменных, участвующих в t-тестах (табл. 3.1).
Т-тесты для независимых выборок
Зависимые переменные
Независимые переменные
Количество
Тип
Количество
Тип
Одна
Дихотомическая интервальная
Любое
Интервальная
Т-тесты для зависимых выборок
Зависимые переменные
Независимые переменные
Количество
Тип
Количество
Тип
-
-
Две
Интервальная
Т-тесты для одной выборки
Зависимые переменные
Независимые переменные
Количество
Тип
Количество
Тип
-
-
Любое
Интервальная
Обратите внимание: зависимая переменная есть только для t-тестов независимых выборок. Для других видов t-тестов (зависимых выборок и одной выборки) зависимая переменная отсутствует. Это связано с тем, что в последнем случае анализу подвергается фактически одна и та же выборка респондентов. В качестве тестируемых независимых переменных во всех случаях используются только переменные с интервальной шкалой. Порядковые переменные могут использоваться только после преобразования их к интервальному виду (см. раздел 2.1).
3.1.1. Т-тесты для независимых выборок
В случае t-тестов для независимых выборок под независимыми выборками понимаются бинарные категории (то есть варианты ответа) какой-либо переменной. Например, мужчины и женщины (вопрос Пол респондента), покупатели и не покупатели какого-либо продукта (вопрос Покупаете ли Вы данный продукт?) и т. д. То есть когда есть два уровня группирующей (зависимой) переменной и несколько независимых переменных, на основании которых и будет выполняться различие между группами зависимой переменной.
Рассмотрим методику проведения t-тестов для независимых выборок на следующем примере. Предположим, что мы оцениваем различия в частоте посещения игровых клубов между посетителями заведений марки X и других марок. Откройте диалоговое окно Independent-Samples T Test при помощи меню Analyze ► Compare Means ► Independent-Samples T Test (рис. 3.1). В область Test Variable(s) поместите переменные, являющиеся критерием для установления различий (в нашем случае это ql8_i Частота посещения). Затем в поле Grouping Variable переместите переменную, которая будет являться группирующей (зависимой). В нашем случае это переменная ql_8, кодирующая категории респондентов, посещающих/не посещающих игровые залы марки X.
Рис. 3.1. Диалоговое окно Independent-Samples T Test
Так как данная переменная является вариантом ответа на многовариантный вопрос Какие игровые клубы Вы посещаете?, она может принимать два значения:
■ 1 — посещают клубы X;
■ 0 — не посещают клубы X.
Эти два значения необходимо указать в специальном диалоговом окне Define Groups, вызываемом одноименной кнопкой (рис. 3.2). Обратите внимание, что если вместо дихотомии мы имеем группирующую переменную с интервальной шкалой, это диалоговое окно позволяет установить точку отсечения Cut point, которая буде! разделять все возможные значения данной переменной на две группы.
Рис. 3.2. Диалоговое окно Define Groups
С помощью кнопки Options в главном диалоговом окне рассматриваемой процедуры можно установить доверительный уровень для результатов расчета t-теста (рис. 3.3). По умолчанию установлен уровень доверия 95 %. Как было показано выше в разделе 1.2, этот уровень точности (достоверности) результатов является достаточным при проведении статистического анализа в маркетинговых исследованиях.
Рис. 3.3. Диалоговое окно Independent-Samples T Test: Options
После завершения процедуры расчета t-теста в окне SPSS Viewer будут отражены результаты (рис. 3.4). В первой таблице Group Statistics вы видите средние значения тестируемой переменной (частота посещения клубов) для обеих групп зависимой переменной X. Как следует из рисунка, для респондентов, посещающих игровые залы марки X, средняя частота посещения составляет 11,9 раз в месяц. Для респондентов, не посещающих данные залы, это значение равно 11,5. Вторая таблица Independent Samples Test позволяет установить статистическое различие между данными значениями.
Group Statistios
T-Test
X
N
Mean
Std. Deviation
Std. Emor Mean
Частота посещения
11,9288
10,43081
1,49140
11,5048
9,98682
,43546
Indeperdert Samples Test
Levene’s Test for Equality of Variances
t-test for Equality of Means
F
Sug.
t
df
Sig. (2-talid)
Mean Difference
Std. Emor Difference
Lower
Upper
Частота посеще-ния
Equal variances assumed
,382
,547
,283
,777
,4238
1,49745
-2,61734
3,36497
Equal variances not assumed
,273
56,495
,786
,4230
1,55367
-2,68795
3,51559
Рис. З.4. Результаты расчета t-теста для независимых выборок
Анализ этой таблицы начинается с определения значимости теста Ливина (Levene). Данный тест служит для тестирования гипотезы о равенстве дисперсий в тестируемых переменных. Если значение в столбце Sig. столбца Levene's Test for Equality of Variances показывает статистическую незначимость теста (в нашем случае — 0,547), то различие между двумя анализируемыми средними определяется из строки Equal variances assumed. В противном случае, если тест Levene статистически значим, различие между двумя средними определяется из строки Equal variances not assumed.
Поскольку в нашем примере тест Ливина является статистически незначимым, то определить значимость различия между двумя тестируемыми группами можно при помощи значения, находящегося на пересечении первой строки и столбца Sig. (2-tailed). Значение 0,777 говорит о том, что различие в частоте посещения игровых залов респондентами, посещающими и не посещающими клубы марки X, является статистически незначимым.