Модельные алгоритмы подразумевают, что у нас есть некоторая модель кластера (его структуры), и мы стремимся найти и максимизировать сходства между этой моделью и имеющимися у нас данными, то есть выделить в данных такие модели, которые и будут кластерами. Часто при этом для представления моделей используется широко разработанный аппарат математической статистики.
Предполагается, что кроме известных нам из наших данных величин существуют еще и неизвестные нам, относящиеся к распределению по кластерам. То есть фактически эти неизвестные "создают" кластер, а мы наблюдаем только результат их деятельности. И именно эти неизвестные мы и стараемся максимально точно оценить.
Алгоритм использует широко известный метод максимизации ожиданий (Expectation Maximization). В наиболее простом случае предполагается, что кластер - это результаты наблюдений, распределенные нормально. Тогда для их характеристики можно применять многомерную функцию Гаусса (многомерное распределение Гаусса) - одно из распределений. И тогда основная задача - это определить, к какому из распределений принадлежит каждая конкретная точка, оценив параметры этих распределений исходя из реального распределения точек.
0. Инициализируем : - среднее отклонение распределений относительно начала координат (т.е. центры кластеров) и вероятности этих распределений для каждой точки. K - число кластеров - задаем.
1. E-шаг:
,
где -функция плотности распределения.
2. М-шаг:
3. Вычисление и сравнение с P(xi | μj)t, если да, то стоп - найден локальный максимум. Если нет, то переходим снова к шагу 1.
В алгоритме COBWEB реализовано вероятностное представление категорий. Принадлежность категории определяется не набором значений каждого свойства объекта, а вероятностью появления значения. Например, P(Aj = υij | Ck) - это условная вероятность, с которой свойство Aj, принимает значение υij, если объект относится к категории Ck. Для каждой категории в иерархии определены вероятности вхождения всех значений каждого свойства. При предъявлении нового экземпляра система COBWEB оценивает качество отнесения этого примера к существующей категории и модификации иерархии категорий в соответствии с новым представителем. Критерием оценки качества классификации является полезность категории (category utility). Критерий полезности категории был определен при исследовании человеческой категоризации. Он учитывает влияние категорий базового уровня и другие аспекты структуры человеческих категорий.
Критерий полезности категории максимизирует вероятность того, что два объекта, отнесенные к одной категории, имеют одинаковые значения свойств и значения свойств для объектов из различных категорий отличаются. Полезность категории определяется формулой
CU =
∑
∑
∑
P(A = υij | Ck)P(Ck | A = υij)P(A = υij)
k
i
j
Значения суммируются по всем категориям Ck, всем свойствам Aj и всем значениям свойств υij. Значение P(Aj = υij | Ck) называется предсказуемостью (predictability). Это вероятность того, что объект, для которого свойство Aj- принимает значение υij, относится к категории Ck. Чем выше это значение, тем вероятнее, что свойства двух объектов, отнесенных к одной категории, имеют одинаковые значения. Величина P(Ck | A = υij) называется предиктивностью (predictiveness). Это вероятность того, что для объектов из категории Ck свойство Aj принимает значение υij. Чем больше эта величина, тем менее вероятно, что для объектов, не относящихся к данной категории, это свойство будет принимать указанное значение. Значение P(A = υij) - это весовой коэффициент, усиливающий влияние наиболее распространенных свойств. Благодаря совместному учету этих значений высокая полезность категории означает высокую вероятность того, что объекты из одной категории обладают одинаковыми свойствами, и низкую вероятность наличия этих свойств у объектов из других категорий.
После некоторых преобразований (Байеса в частности) и некоторых агрументированных изменений мы получаем более правильную формулу:
N -число категорий.
Алгоритм COBWEB имеет следующий вид.
cobweb(Node, Instance) Begin if узел Node - это лист, then begin создать два дочерних узла L1 и L2 для узла Node; задать для узла L1 те же вероятности, что и для узла Node; инициализировать вероятности для узла L2 соответствующими значениями объекта Instance; добавить Instance к Node, обновив вероятности для узла Node ; end else begin добавить Instance к Node, обновив вероятности для узла Node; для каждого дочернего узла С узла Node вычислить полезность категории при отнесении экземпляра Instance к категории С; пусть S1 - значение полезности для наилучшей классификации C1; пусть S2 - значение для второй наилучшей классификации C2; пусть S3 - значение полезности для отнесения экземпляра к новой категории; пусть S4 - значение для слияния C1 и C2 в одну категорию; пусть S5 - значение для разделения C1 (замены дочерними категориями); end if S1 - максимальное значение CU, then cobweb(C1, Instance) %отнести экземпляр к C1 else if S3 - максимальное значение CU, then инициализировать вероятности для новой категории Cm значениями Instance else if S4 - максимальное значение CU, then begin пусть Cm - результат слияния C1 и C2; cobweb(Cm, Instance); end else if S5 - максимальное значение CU, then begin разделить C1; % Cm - новая категория cobweb(Cm, Instance) end; end
В алгоритме COBWEB реализован метод поиска экстремума в пространстве возможных кластеров с использованием критерия полезности категорий для оценки и выбора возможных способов категоризации.
Сначала вводится единственная категория, свойства которой совпадают со свойствами первого экземпляра. Для каждого последующего экземпляра алгоритм начинает свою работу с корневой категории и движется далее по дереву. На каждом уровне выполняется оценка эффективности категоризации на основе полезности категории. При этом оцениваются результаты следующих операций:
Отнесение экземпляра к наилучшей из существующих категорий.
Добавление новой категории, содержащей единственный экземпляр.
Слияние двух существующих категорий в одну новую с добавлением в нее этого экземпляра.
Разбиение существующей категории на две и отнесение экземпляра к лучшей из вновь созданных категорий.
Для слияния двух узлов создается новый узел, для которого существующие узлы становятся дочерними. На основе значений вероятностей дочерних узлов вычисляются вероятности для нового узла. При разбиении один узел заменяется двумя дочерними.
Этот алгоритм достаточно эффективен и выполняет кластеризацию на разумное число классов. Поскольку в нем используется вероятностное представление принадлежности, получаемые категории являются гибкими и робастными. Кроме того, в нем проявляется эффект категорий базового уровня, поддерживается прототипирование и учитывается степень принадлежности. Он основан не на классической логике, а, подобно методам теории нечетких множеств, учитывает "неопределенность" категоризации как необходимый компонент обучения и рассуждений в гибкой и интеллектуальной манере.

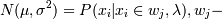 - одно из распределений. И тогда основная задача - это определить, к какому из распределений принадлежит каждая конкретная точка, оценив параметры этих распределений исходя из реального распределения точек.
- одно из распределений. И тогда основная задача - это определить, к какому из распределений принадлежит каждая конкретная точка, оценив параметры этих распределений исходя из реального распределения точек.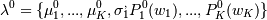 - среднее отклонение распределений относительно начала координат (т.е. центры кластеров) и вероятности этих распределений для каждой точки. K - число кластеров - задаем.
- среднее отклонение распределений относительно начала координат (т.е. центры кластеров) и вероятности этих распределений для каждой точки. K - число кластеров - задаем.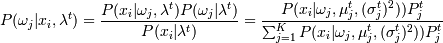 ,
,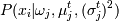 -функция плотности распределения.
-функция плотности распределения.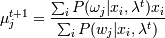
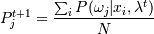
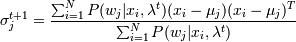
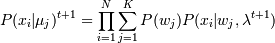 и сравнение с P(xi | μj)t, если да, то стоп - найден локальный максимум. Если нет, то переходим снова к шагу 1.
и сравнение с P(xi | μj)t, если да, то стоп - найден локальный максимум. Если нет, то переходим снова к шагу 1.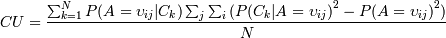 N -число категорий.
N -число категорий.