Классификация - системное распределение изучаемых предметов, явлений, процессов по родам, видам, типам, по каким-либо существенным признакам для удобства их исследования; группировка исходных понятий и расположение их в определенном порядке, отражающем степень этого сходства. Под классификацией будем понимать отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
Классификация требует соблюдения следующих правил:
в каждом акте деления необходимо применять только одно основание;
деление должно быть соразмерным, т.е. общий объем видовых понятий должен равняться объему делимого родового понятия;
члены деления должны взаимно исключать друг друга, их объемы не должны перекрещиваться;
деление должно быть последовательным.
Различают:
вспомогательную (искусственную) классификацию, которая производится по внешнему признаку и служит для упорядочивания множества предметов (процессов, явлений);
естественную классификацию, которая производится по существенным признакам, характеризующим внутреннюю общность предметов и явлений. Она является результатом и важным средством научного исследования, так как предполагает и закрепляет результаты изучения закономерностей классифицируемых объектов, а значит .
В зависимости от выбранных признаков, их сочетания и процедуры деления понятий классификация может быть:
простой - деление родового понятия только по признаку и только один раз до раскрытия всех видов. Примером такой классификации является дихотомия, при которой членами деления бывают только два понятия, каждое из которых является противоречащим другому (т.е. соблюдается принцип: "А и не А");
сложной - применяется для деления одного понятия по разным основаниям и синтеза этих простых делений в единое целое. Примером такой классификации является периодическая система химических элементов.
Классификация относится к задачам, требующим обучения с учителем. При обучении с учителем набор исходных данных (или выборку данных) разбивают на два множества: обучающее и тестовое. Обучающее множество (training set) - множество, которое включает данные, использующиеся для обучения (конструирования) модели. Тестовое (test set) множество также содержит входные и выходные значения примеров. Здесь выходные значения используются для проверки работоспособности модели.
Процесс классификации состоит из двух этапов: конструирования модели и ее использования.
1. Конструирование модели: описание множества предопределенных классов.
Каждый пример набора данных относится к одному предопределенному классу.
На этом этапе используется обучающее множество, на нем происходит конструирование модели.
Полученная модель может быть представлена классификационными правилами, деревом решений или математической формулой.
2. Использование модели: классификация новых или неизвестных значений.
Оценка правильности (точности) модели.
2.1. Известные значения из тестового примера сравниваются с результатами использования полученной модели.
2.2. Уровень точности - процент правильно классифицированных примеров в тестовом множестве.
2.3. Тестовое множество, т.е. множество, на котором тестируется построенная модель, не должно зависеть от обучающего множества.
Если точность модели допустима, возможно использование модели для классификации новых примеров, класс которых неизвестен.
Для классификации используются различные методы. Основные из них:
классификация с помощью деревьев решений;
байесовская (наивная) классификация;
классификация при помощи искусственных нейронных сетей;
классификация методом опорных векторов;
статистические методы, в частности, линейная регрессия;
классификация при помощи метода ближайшего соседа;
классификация CBR-методом;
классификация при помощи генетических алгоритмов.
Оценка точности классификации может проводиться при помощи кросс-проверки. Кросс-проверка (Cross-validation) - это процедура оценки точности классификации на данных из тестового множества, которое также называют кросс-проверочным множеством. Точность классификации тестового множества сравнивается с точностью классификации обучающего множества. Если классификация тестового множества дает приблизительно такие же результаты по точности, как и классификация обучающего множества, считается, что данная модель прошла кросс-проверку. Разделение на обучающее и тестовое множества осуществляется путем деления выборки в определенной пропорции, например обучающее множество - две трети данных и тестовое - одна треть данных.
Метод деревьев решений (decision trees) является одним из наиболее популярных методов решения задач классификации и прогнозирования. Иногда этот метод Data Mining также называют деревьями решающих правил, деревьями классификации и регрессии. Если зависимая, т.е. целевая переменная принимает дискретные значения, при помощи метода дерева решений решается задача классификации. Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает зависимость этой переменной от независимых переменных, т.е. решает задачу численного прогнозирования.
В наиболее простом виде дерево решений - это способ представления правил в иерархической, последовательной структуре. Основа такой структуры - ответы "Да" или "Нет" на ряд вопросов. Корень - исходный вопрос, внутренний узел дерева является узлом проверки определенного условия. Далее идет следующий вопрос и т.д., пока не будет достигнут конечный узел дерева, являющийся узлом решения. Бинарные деревья являются самым простым, частным случаем деревьев решений. В остальных случаях, ответов и, соответственно, ветвей дерева, выходящих из его внутреннего узла, может быть больше двух. На этапе построения модели, собственно, и строится дерево классификации или создается набор неких правил. На этапе использования модели построенное дерево, или путь от его корня к одной из вершин, являющийся набором правил для конкретного клиента, используется для ответа на поставленный вопрос. Правилом является логическая конструкция, представленная в виде "если : то :".
Внутренние узлы дерева являются атрибутами базы данных. Эти атрибуты называют прогнозирующими, или атрибутами расщепления (splitting attribute). Конечные узлы дерева, или листы, именуются метками класса, являющимися значениями зависимой категориальной переменной. Каждая ветвь дерева, идущая от внутреннего узла, отмечена предикатом расщепления. Последний может относиться лишь к одному атрибуту расщепления данного узла. Характерная особенность предикатов расщепления: каждая запись использует уникальный путь от корня дерева только к одному узлу-решению. Объединенная информация об атрибутах расщепления и предикатах расщепления в узле называется критерием расщепления (splitting criterion). Качество построенного дерева решения весьма зависит от правильного выбора критерия расщепления.
Классификационная модель, представленная в виде дерева решений, является интуитивной и упрощает понимание решаемой задачи. Деревья решений дают возможность извлекать правила из базы данных на естественном языке. Алгоритм конструирования дерева решений не требует от пользователя выбора входных атрибутов (независимых переменных). На вход алгоритма можно подавать все существующие атрибуты, алгоритм сам выберет наиболее значимые среди них, и только они будут использованы для построения дерева.
В виде формулы: у = a0 + a1*x1 + ... + an*xn, логические и категориальные переменные кодируют числами.
Пусть у нас есть независимые переменные A1...Aj...Ak, принимающие значения соответственно, и зависимая переменная C, принимающая значения c1...cr. Для любого возможного значения каждой независимой переменной формируется правило, которое классифицирует объект из обучающей выборки. В если-части правила указывают значение независимой переменной (Если ). В то-части правила указывается наиболее часто встречающееся значение зависимой переменной у данного значения независимой переменной(то C = cr). Ошибкой правила является количество объектов, имеющих данное значение рассматриваемой независимой переменной (), но не имеющих наиболее часто встречающееся значение зависимой переменной у данного значения независимой переменной(). Оценив ошибки, выбирается переменная, для которой ошибка набора минимальна.
В случае непрерывных значений манипулируют промежутками. В случае пропущенных значений - достраивают. Наиболее серьезный недостаток - сверхчувствительность, алгоритм выбирает переменные, стремящиеся к ключу (т.е. с максимальным количеством значений, у ключа ошибка вообще 0, но он не несет информации). Эффективен, если объекты классифицируются по одному атрибуту.

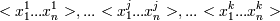 соответственно, и зависимая переменная C, принимающая значения c1...cr. Для любого возможного значения каждой независимой переменной формируется правило, которое классифицирует объект из обучающей выборки. В если-части правила указывают значение независимой переменной (Если
соответственно, и зависимая переменная C, принимающая значения c1...cr. Для любого возможного значения каждой независимой переменной формируется правило, которое классифицирует объект из обучающей выборки. В если-части правила указывают значение независимой переменной (Если  ). В то-части правила указывается наиболее часто встречающееся значение зависимой переменной у данного значения независимой переменной(то C = cr). Ошибкой правила является количество объектов, имеющих данное значение рассматриваемой независимой переменной (
). В то-части правила указывается наиболее часто встречающееся значение зависимой переменной у данного значения независимой переменной(то C = cr). Ошибкой правила является количество объектов, имеющих данное значение рассматриваемой независимой переменной (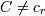 ). Оценив ошибки, выбирается переменная, для которой ошибка набора минимальна.
). Оценив ошибки, выбирается переменная, для которой ошибка набора минимальна.