Имеется несколько алгоритмов, близких к алгоритму LRU, в которых реализованы различные идеи улучшений или упрощений, направленные на то, чтобы уменьшить недостатки LRU.
1. Бит ссылки (reference bit).В данном алгоритме с каждой страницей связывается бит, первоначально равный 0. При обращении к странице бит устанавливается в 1. Далее, при необходимости замещения страниц, заменяется та страница, у которой бит равен 0 (если такая существует), т.е. страница, к которой не было обращений. Данная версия алгоритма позволяет избежать поиска по таблице страниц. Однако она, очевидно, менее оптимальна, чем LRU.
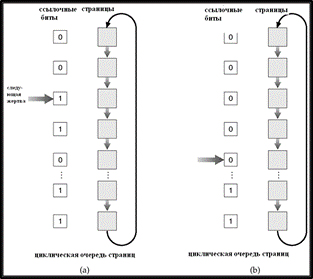
2. Второй шанс (second chance).В данной версии алгоритма используются ссылочный бит и показания часов, которые хранятся в каждом элементе таблицы страниц. Замещение страниц основано на показаниях часов. Если страница, которую следует заместить (по показаниям часов), имеет ссылочный бит, равный 1, то выполняются следующие действия:
o Установить ссылочный бит в 0;
o Оставить страницу в памяти;
o Заместить следующуюстраницу (по показаниям часов), по тем же самым правилам.
Данный алгоритм имеет следующее эвристическое обоснование. Странице, которая дольше всего не использовалась, как бы дается второй шанс на то, что она будет использована, т. е. делается эвристическое предположение, что, по мере возрастания времени, вероятность обращения к странице, к которой давно не было обращений, возрастает.
Схема алгоритма второго шанса изображена на рис. 18.14.
Рис. 18.14. Алгоритм второго шанса.
Идея, родственная идее алгоритма LRU, - хранить счетчикичисла обращений к каждой странице. На основе этой идеи существуют два алгоритма:
· - Алгоритм Least Frequently Used (LFU):замещать страницы с минимальным значением счетчика (к которым было меньше всего обращений);
· - Алгоритм Most Frequently Used (MFU):замещать страницы с максимальным значением счетчика. Данный алгоритм основан на соображении, что страница с минимальным счетчиком – возможно, лишь недавно загружена, и, видимо, в дальнейшем будет активно использоваться, поэтому она оставляется в памяти.
До сих пор мы рассматривали алгоритмы замещения страниц при определенном числе фреймов, выделенных каждому процессу. Рассмотрим теперь стратегии выделения фреймов. При их выделении ОС исходит из того, чтобы каждому процессу выделить минимально необходимое число страниц.
Однако различные аппаратные платформы имеют свои особенности, что тоже приходится учитывать. Например, в системе IBM 370 требуется 6 (!) страниц, чтобы обработать команду MOVE (пересылки) формата SS (Storage-Storage). В самом деле, длина команды - 6 байтов, так что она может размещается на двух соседних страницах. Кроме того, максимум две страницы требуются для обработки источника и максимум две страницы – для обработки получателя. Разумеется, подобный казус не может произойти в RISC-системах.
В операционных системах используются две основных схемы выделения фреймов - фиксированное выделениеи выделение по приоритетам.
Фиксированное выделение фреймов.Наиболее простой вариант - равномерное распределениефреймов процессам. Например, если имеется 100 фреймов и 5 процессов, каждому выделяется по 20 страниц. Используется также пропорциональное распределение– выделять фреймы в соответствии со следующим принципом: если общее число фреймов m, размер процесса – s, а общий размер всех процессов – S, то общее число фреймов, выделенных процессу, равно:
a = m * (s / S).
Выделение по приоритетам.Принцип данного распределения фреймов следующий: применять схему пропорционального распределения, но используя приоритеты, а не размер. Если процесс генерирует отказ страницы, то для замещения выделяется фрейм из процесса с более низким приоритетом.
Глобальное и локальное распределение. Глобальноезамещение фреймов означает, что процесс выбирает фрейм для замещения среди всехсуществующих фреймов всех процессов, т.е. один процесс может взять фрейм у другого. Локальноезамещение фреймов, наоборот, гарантирует, что каждый процесс выбирает фрейм для замещения только из числа выделенных ему фреймов.