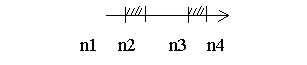Очевидно, что по мере заполнения хеш-таблицы будут происходить коллизии и в результате их разрешения методами открытой адресации очередной адрес может выйти за пределы адресного пространства таблицы. Что бы это явление происходило реже, можно пойти на увеличение длины таблицы по сравнению с диапазоном адресов, выдаваемым хеш-функцией.
Рис.3.5. Циклический переход к началу таблицы.
С одной стороны это приведет к сокращению числа коллизий и ускорению работы с хеш-таблицей, а с другой к нерациональному расходованию адресного пространства. Даже при увеличении длины таблицы в два раза по сравнению с областью значений хеш-функции нет гарантии того, что в результате коллизий адрес не превысит длину таблицы. При этом в начальной части таблицы может оставаться достаточно свободных элементов. Поэтому на практике используют циклический переход к началу таблицы.
Рассмотрим данный способ на примере метода линейного опробования. При вычислении адреса очередного элемента можно ограничить адрес, взяв в качестве такового остаток от целочисленного деления адреса на длину таблицы n.
Вставка
i = 0
a = (h(key) + c*i) mod n
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
i = i + 1, перейти к шагу 2
В данном алгоритме мы не учитываем возможность многократного превышения адресного пространства. Более корректным будет алгоритм, использующий сдвиг адреса на 1 элемент в случае каждого повторного превышения адресного пространства. Это повышает вероятность найти свободные элементы в случае повторных циклических переходов к началу таблицы.
Вставка
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
i = i + 1, перейти к шагу 2
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Рассматривая возможность выхода за пределы адресного пространства таблицы, мы не учитывали факторы заполненности таблицы и удачного выбора хеш-функции. При большой заполненности таблицы возникают частые коллизии и циклические переходы в начало таблицы. При неудачном выборе хеш-функции происходят аналогичные явления. В наихудшем варианте при полном заполнении таблицы алгоритмы циклического поиска свободного места приведут к зацикливанию. Поэтому при использовании хеш-таблиц необходимо стараться избегать очень плотного заполнения таблиц. Обычно длину таблицы выбирают из расчета двукратного превышения предполагаемого максимального числа записей. Не всегда при организации хеширования можно правильно оценить требуемую длину таблицы, поэтому в случае большой заполненности таблицы может понадобиться рехеширование. В этом случае увеличивают длину таблицы, изменяют хеш-функцию и переупорядочивают данные.
Производить отдельную оценку плотности заполнения таблицы после каждой операции вставки нецелесообразно, поэтому можно производить такую оценку косвенным образом по числу коллизий во время одной вставки. Достаточно определить некоторый порог числа коллизий, при превышении которого следует произвести рехеширование. Кроме того, такая проверка гарантирует невозможность зацикливания алгоритма в случае повторного просмотра элементов таблицы.
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = свободно или t(a) = удалено, то t(a) = key, записать элемент, стоп элемент добавлен
Если i > m , то стоп требуется рехеширование
i = i + 1, перейти к шагу 2
В данном алгоритме номер итерации сравнивается с пороговым числом m. Следует заметить, что алгоритмы вставки, поиска и удаления должны использовать идентичное образование адреса очередной записи.
Удаление
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = key, то t(a) =удалено, стоп элемент удален
Если t(a) = свободно или i>m, то стоп элемент не найден
i = i + 1, перейти к шагу 2
Поиск
i = 0
a = ((h(key) + c*i) div n + (h(key) + c*i) mod n) mod n
Если t(a) = key, то стоп элемент найден
Если t(a) = свободно или i>m, то стоп элемент не найден
i = i + 1, перейти к шагу 2
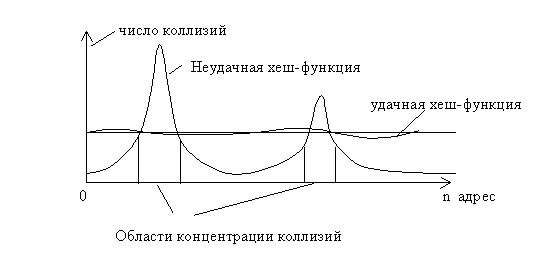
Как уже было отмечено, очень важен правильный выбор хеш-функции. При удачном построении хеш-функции таблица заполняется более равномерно, уменьшается число коллизий и уменьшается время выполнения операций поиска, вставки и удаления. Для того чтобы предварительно оценить качество хеш-функции можно провести имитационное моделирование. Моделирование проводится следующим образом. Формируется целочисленный массив, длина которого совпадает с длиной хеш-таблицы. Случайно генерируется достаточно большое число ключей, для каждого ключа вычисляется хеш-функция. В элементах массива просчитывается число генераций данного адреса. По результатам такого моделирования можно построить график распределения значений хеш-функции. Для получения корректных оценок число генерируемых ключей должно в несколько раз превышать длину таблицы.
Рис. 3.6. Распределение коллизий в адресном пространстве таблицы
Если число элементов таблицы достаточно велико, то график строится не для отдельных адресов, а для групп адресов. Например, все адресное пространство разбивается на 100 фрагментов и подсчитывается число попаданий адреса для каждого фрагмента. Большие неравномерности свидетельствуют о высокой вероятности коллизий в отдельных местах таблицы. Разумеется, такая оценка является приближенной, но она позволяет предварительно оценить качество хеш-функции и избежать грубых ошибок при ее построении.
Оценка будет более точной, если генерируемые ключи будут более близки к реальным ключам, используемым при заполнении хеш-таблицы. Для символьных ключей очень важно добиться соответствия генерируемых кодов символов тем кодам символов, которые имеются в реальном ключе. Для этого стоит проанализировать, какие символы могут быть использованы в ключе.
Например, если ключ представляет собой фамилию на русском языке, то будут использованы русские буквы. Причем первый символ может быть большой буквой, а остальные малыми. Если ключ представляет собой номерной знак автомобиля, то также несложно определить допустимые коды символов в определенных позициях ключа.
Рассмотрим пример генерации ключа из десяти латинских букв, первая из которых является большой, а остальные малыми.
Пример
: ключ 10 символов, 1-й большая латинская буква
2-10 малые латинские буквы
var i:integer; s:string[10];
begin
s[1]:=chr(random(90-65)+65);
for i:=2 to 10 do s[i]:=chr(random(122-97)+97);
end
В данном фрагменте используется тот факт, что допустимые коды символов располагаются последовательными непрерывными участками в кодовой таблице. Рассмотрим более общий случай. Допустим, необходимо сгенерировать ключ из m символов с кодами в диапазоне от n1 до n2.
Генерация ключа из m символов c кодами в диапазоне от n1 до n2
(диапазон непрерывный)
for i:=1 to m do str[i]:=chr(random(n2-n1)+n1);
На практике возможны варианты, когда символы в одних позициях ключа могут принадлежать к разным диапазонам кодов, причем между этими диапазонами может существовать разрыв.
Генерация ключа из m символов c кодами
в диапазоне от n1 до n4 (диапазон имеет разрыв от n2 до n3)
for i:=1 to m do
begin
x:=random((n4 - n3) + (n2 n1));
if x<=(n2 - n1) then str[i]:=chr(x + n1)
else str[i]:=chr(x + n1 + n3 n2)
end;
Рассмотрим еще один конкретный пример. Допустим известно, что ключ состоит из 7 символов. Из них три первые символа большие латинские буквы, далее идут две цифры, остальные малые латинские.
Пример: длина ключа 7 символов
3 большие латинские (коды 65-90)
2 цифры (коды 48-57)
2 малые латинские (коды 97-122)
var
key: string[7];
begin
for i:=1 to 3 do key[i]:=chr(random(90-65)+65);
for i:=4 to 5 do key[i]:=chr(random(57-48)+57);
for i:=6 to 7 do key[i]:=chr(random(122-97)+97);
end;
В рассматриваемых примерах мы исходили из предположения, что хеширование будет реализовано на языке Turbo Pascal, а коды символов соответствуют альтернативной кодировке.