Большое разнообразие возможных алгоритмов функционирования и сложность структур компьютерных сетей не всегда позволяют при проектировании свести устройство к математической модели, которая может быть исследована аналитическим методом даже с учетом возможных упрощающих предположений. Поэтому широкое распространение получили машинные методы исследования характеристик процесса функционирования компьютерных сетей на их имитационных моделях.
Имитационные модели позволяют рассматривать процессы, происходящие в устройствах СПИ, практически на любом уровне детализации. Для машинной реализации имитационной модели необходимо построить соответствующий моделирующий алгоритм, воспроизводящий в некотором масштабе времени процесс функционирования исследуемой системы (устройства) с той степенью детальности, которая необходима разработчику (исследователю), причем элементарные явления, составляющие процесс, имитируются с сохранением их логической структуры и последовательности протекания во времени.
При имитационном моделировании модель системы (устройства) задана на уровне связи реализаций входных и выходных процеcсов и внешних воздействий через характеристики проектируемой системы (характеристики блоков, составляющих систему и их связи); интересующие же разработчика характеристики выходных (в ряде случаев и промежуточных) процессов получают путем последующей обработки смоделированных реализаций этих процессов.
Термин «имитационное моделирование» не очень удачен, так как имитация сама по себе есть моделирование, а моделирование — имитация. Тем не менее этот термин устойчиво «прижился» в специальной технической литературе и часто отождествляется с терминами «машинная имитация», «машинный имитационный эксперимент», «имитационный эксперимент на ЭВМ», «моделирование на вычислительных машинах», «статистическое моделирование». Употребление последнего термина обусловлено тем, что статистическое моделирование как метод машинной реализации имитационных моделей систем, подверженных случайным воздействиям, в настоящее время наиболее употребим, хотя в детерминированных случаях имитационные модели реализуются и другими методами (например, метод «Динамо», метод ситуационного управления).
Статистическое моделирование представляет собой численный метод, дающий частное решение, отвечающее фиксированным значениям параметров системы, входной информации и начальным условиям. В основе его лежит процедура, применяемая для моделирования случайных величин и функций и носящая название метода статистических испытаний (метод Монте-Карло),
Общая схема метода Монте-Карло может быть записана в виде
. (2.6)
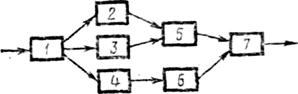
Результат ищется как математическое ожидание некоторой случайной величины Y, которая чаще всего является неслучайной функцией случайной величины X, имеющей распределение р(х). Нестрогое выражение «случайная величина X имеет распределение р(х)» и запись Xр(х) означают для непрерывной случайной величины, что ее плотность вероятности равна р(х); для дискретной случайной величины функцию р(х) надо понимать как функцию вероятности. Для дискретной случайной величины интеграл (2.6) заменяется суммой у(х)р{х)ув которой суммирование осуществляете;: по всем возможным значениям X. Функция у(х) может иметь несколько аргументов, т. е. зависеть от нескольких случайных величин. В таком случае запись (2.6) остается в силе, только интеграл надо считать многомерным, X рассматривать как вектор, а р(х)—как многомерную плотность (или функцию) вероятности. Приближенная оценка неизвестного математического ожидания, совпадающая с искомым результатом, находится как среднее арифметическое результатов независимых опытов. Это отражено в правой части (2.6). По закону больших чисел среднее арифметическое сводится к математическому ожиданию. В каждом опыте разыгрывается реалиация х случайной величины X (в i-м опыте реализация хi) в соответствии с распределением р(х) и вычисляется значение функции в виде y(хi). Индекс i подчеркивает, что для каждой (i-й) реализации процесса аргументы, составляющие вектор X, имеют свои случайные значения. Вычисленное очередное значение y(xi) добавляется к накапливаемой сумме у(хi). На этом заканчивается очередной опыт. После того как проведено М опытов, вычисляется итоговая оценка . Опыты повторяются до тех пор, пока дисперсия оценки не cнизится до требуемой величины, зависящей от допустимой погрешности и коэффициента доверия. Проиллюстрируем суть метода Монте-Карло относительно простым примером. Пусть требуется оценить надежность системы (рис. 2.11). Система выполняет свою функцию, если работают цепочки блоков: 1, 2, 5, 7; 1, 3, 5, 7; 4, 6, 7. Какие-то блоки могут отказать. Каждый блок характеризуется временем безотказной работы .
Рис. 2.11. Блочная структура системы
Пусть заданы плотности распределения . Какова надежность системы в целом? Рассмотрим случайную величину
= min {, max [min (,), min [max (,),]],} (2.7)
— время безотказной работы системы. В одном опыте разыгрывается значение в соответствии с . Через полученные реализации по формуле (2.7) вычисляем реализацию . Один опыт дает одну реализацию . Проводим М опытов (испытаний), получаем «статистический» материал (выборку). Берем среднее арифметическое времени безотказной работы системы ср в качестве оценки надежности системы. При необходимости можно построить и закон распределения случайной величины .
Таким образом, испытания реальной системы заменены на испытания математической модели. Каждое испытание сопровождается расчетом. Поэтому имитационное моделирование и называют численным экспериментом на ЭВМ с математической моделью (модель выступает как объект испытания). При реализации испытания возможны и логические операции. И расчетные и логические операции реализуются на ЭВМ с помощью соответствующих алгоритмов, которые в совокупности составляют определенный выше моделирующий алгоритм.
Структурная схема эксперимента по имитационному моделированию показана на рис. 2.12.
Традиционно модель рассматривается как «черный ящик», имеющий входы Х и выходы Y. В качестве входов подразумевают параметры входных сигналов (например, параметры входных сообщений — тип, категория срочности, длина, время возникновения сообщения), в качестве выходов — различные характеристики, интересующие разработчика.
После выбора X и Y определяется план эксперимента, т.е. процедура выбора входных параметров х1, х2,..., на которые желательно знать реакцию модели. Само вычисление значений у1, у2,... производится с помощью работы моделирующего алгоритма, позволяющего при заданных х1, х2, ... воспроизвести траекторию системы Z(t), noкоторой вычисляются показатели yi. В блоке обработки результатов происходит накопление сумм и статистическая обработка. Выбор плана эксперимента зависит от цели исследования. Если, например, интересует оптимизация некоторого критерия качества, то его значения являются выходом, а план заключается в выборе оптимизирующей последовательности х1, х2, ... в соответствии с определенным методом (например, градиентного поиска). Если необходимо выявить существенные параметры модели или выбрать структуру, то план заключается в изучении влияния того или иного параметра или вида структуры на выход модели.
Для формирования реализаций случайных объектов (событий, функций, процессов) используется датчик случайных чисел (ДСЧ), генерирующий в каждом опыте набор значений базовой случайной величины, на основе которых формируются реализации входных сигналов и влияющих внешних факторов. Функция влияния является характеристикой, отражающей действие внешних факторов на изменения параметров модели.
Рис. 2.12. Структурная схема эксперимента с моделью
Величина цикла (числопрогонов модели) может быть задана априори либо вычисляться по промежуточным результатам обработки; поэтому в ходе эксперимента может быть принято решение о прекращении исследования для заданного набора значений параметров модели.
Управление экспериментом сводится к установлению очередности системных событий, происходящих в процессе имитации, определению перехода к очередной реализации, к другому варианту исходных данных, изменению либо перестройке модели при смене задачи исследования.
При исследовании компьютерных сетей ставится задача определения большого числа показателей их функционирования. Эффективная оценка каждого показателя требует своей модели, своего моделирующего алгоритма. Здесь возможны два подхода. Первый связан с построением универсальной автоматизированной имитационной модели (УАИМ), модули которой могут настраиваться с разной степенью детализации, определяемой требованиями решаемой задачи. При этом каждый модуль и схема сопряжения должны быть реализованы с максимальной степенью детализации своих микрооператоров и связей, УАИМ в этом случае представляет сама по себе сложную программную систему, разработка и отладка которой требует значительных ресурсов, да и сам процесс настройки отдельных отлаженных модулей по ходу имитации сопряжен с большими затратами машинного времени. Второй подход связан с разработкой библиотеки стандартных программных модулей, реализованных с разной степенью детализации операторов. В этом случае каждому элементу соответствует множество модулей, характеристики каждого из которых строго соответствуют уровню решаемой задачи. При этом настройка моделей сводится к компоновке модели из названных модулей, отвечающих условиям задачи исследования. Если в первом случае избыточность описания элементов внесена в модель системы и взаимодействие элементов строится с учетом этой избыточности, то во втором случае избыточность проявляется на уровне представления элементов и во взаимодействии не проявляется. В практике имитационного моделирования встречаются оба подхода.
При анализе вероятностно-временных характеристик устройств компьютерных сетей приходится сталкиваться с необходимостью оценки малых вероятностей, например вероятности отказа системы или вероятности ошибочного декодирования. Для получения оценок таких вероятностей имитационную модель рекомендуется строить с использованием методов ускоренного моделирования. Ускорить моделирование – значит добиться большей точности при том же числе опытов или получить требуемую точность при меньшем числе опытов. Точность результата моделирования измеряется его дисперсией. Чем меньше дисперсия, тем выше точность. Поэтому методы ускоренного моделирования чаще называют методами снижения дисперсии. Если при одном и том же числе опытов один метод дает дисперсию в k раз меньшую, чем другой, значит для достижения заданной точности оценки первый метод требует в k раз меньше опытов. Обычно ускоренные методы требуют на один опыт примерно столько же времени, сколько обычный метод, а иногда даже меньше. Следовательно, при сопоставлении одного метода моделирования с другим вместо затрат машинного времени можно сравнивать дисперсии оценок при одном и том же числе опытов, если затраты времени на один опыт примерно одинаковы.
В практике ускоренного моделирования находят применение методы существенной выборки и расслоенной выборки. Идея метода существенной выборки заключайся в замене функции у(х) (2.6) другой функцией с тем же математическим ожиданием, но с меньшей дисперсией. Для сохранения математического ожидания необходимо соответственно изменить распределение аргумента. Схема метода существенной выборки выражается следующей записью
Математическое ожидание оценки qсовпадает с . Поскольку у(х) и р(х) считаются выбранными при первоначальной постановке задачи, необходимо выбрать q(x) так, чтобы дисперсия оценки q была как можно меньше. При этом должны быть выполнены требование q(x), если у(х)р(х) и условие нормировки
(2.7)
Желательно q(x) выбирать в виде
q(x) = q0(x)=, (2.8)
где постоянная с находится из условия (2.7), т.е.
с=. (2.9)
При таком выборе q(x) оценка q =0будет обладать наименьшей дисперсией. В действительности это возможно в принципе, но не реализуемо. Для нахождения q(x) в виде (2.8) необходимо вычислить константу с по формуле (2.9), а это задача не менее трудная, чем исходная, так как интеграл в (2.9) очень похож на искомый интеграл (2.6). Тем не менее, хотя оптимальное распределение (2.8) невозможно реализовать, его вид указывает, к чему надо стремиться при выборе q(x).
Чтобы уменьшить дисперсию оценки с помощью метода существенной выборки, надо использовать функцию q(x), по возможности пропорциональную произведению и при этом удовлетворяющую условиям нормировки. Если исходное распределение р(х) предполагает примерно одинаковые вероятности выбора х во всем диапазоне возможных значений, то новое распределение q(x), пропорциональное , предписывает чаще выбирать существенные значения х — те, при которых осредняемая функция у(х) принимает большие значения; при этом учитывается и исходное распределение. Этим объясняется и название метода.
На практике, когда функция у(х) задается сложным алгоритмом, а аргумент х представляет собой вектор со случайным числом элементов, можно попытаться, не опираясь на приведенную выше рекомендацию, подобрать q(x) методом проб и ошибок. Поиск q(x) удобно вести в некотором классе распределений, зависящих от параметра. Важно, чтобы случайные числа с таким распределением легко генерировались на ЭВМ. В широко распространенном случае, когда аргументы являются равномерно распределенными в интервале [0,1] случайными числами, удобно использовать семейство распределений с плотностью вероятности
Случайные числа с таким распределением получаются из равномерно распределенных чисел и по формуле
.
Значение параметра а, дающее наименьшую дисперсию оценки, ищется методом проб и ошибок на основе предварительных опытов.
Другим более распространенным методом ускоренного моделирования является метод расслоенной (стратифицированной) выборки (рис. 2.13).
Рис. 2.13. Кусочно-непрерывная функция у(х) случайного аргумента х
Видно, что область значений аргумента х может быть разбита на участки так, что изменение функции в пределах участка значительно меньше, чем в пределах всей области. В таком случае целесообразно сначала осреднить функцию на каждом участке отдельно, а затем из частных средних получить общее среднее с учетом неодинаковых вероятностей участков. Предполагается, что вероятности слоев pr, r=легко вычисляются через заданное распределение р(х):
pr = p(xBr)= r=,
где Br, r=— подмножества множества {х} значений аргумента х, называемые слоями (стратами).
Искомый результат представляется по формуле полной вероятности через условные математические ожидания
опыты проводятся, как в обычной схеме (2.6), но по слоям. Для каждого слоя вычисляются оценки условных математических ожиданий (частные оценки)
где Мr — количество опытов в r-м слое.
В конце вычисляется суммарная оценка
Теория показывает: чтобы оценка имела меньшую дисперсию, чем обычная оценка (без расслоения), достаточно, чтобы объем выборки распределялся по слоям пропорционально их вероятностям и чтобы условные средние по слоям не были одинаковы. При разбиениям по слоям надо стремиться к тому, чтобы средние по слоям как можно больше отличались друг от друга. В реальных задачах аргумент X является вектором и разбиение на слои надо проводить в многомерном пространстве. Обычно это делают с помощью некоторой функции h(х) называемой параметром расслоения. Разбивают множество значений h(х) на подмножества и считают х, относящимсяк слою B( r), если h(х). Зависимость осредняемой функции у(х)
от параметра расслоения h(х), как правило, носит вероятностный характер. Поэтому в качестве параметра расслоения следует выбирать функцию, сильно коррелированную с осредняемой функцией, и назначать слои путем разбиения множества значений параметра расслоения на последовательно расположенные отрезки.
Часто возникают трудности с определением вероятности слоев, что является основным препятствием метода расслоенной выборки. Здесь может помочь преобразование исходного распределения по аналогии с методом существенной выборки или расслоение после выборки. В последнем случае можно генерировать х в сответствии с исходным распределением р(х) и определять принадлежность х к тому или иному слою после того, как значение получено. При этом объемы выборок по слоям окажутся случайными, но в среднем они будут пропорциональны вероятностям слоев, так что при удачном выборе параметра расслоения оценка должна иметь меньшую дисперсию.
Оптимальный вариант метода существенной выборки не удается реализовать. Неоптимальный вариант подчас приводит к широкому диапазону значений усредняемой функции. Можно попытаться компенсировать большой разброс осредняемой функции путем расслоения выборки, для чего необходимо знать вероятности слоев. После применения метода существенной выборки (в неоптимальном варианте) новое распределение оказывается иногда более простым, чем исходное. Это дает возможность вычислить вероятности слоев аналитически. В этом смысле оба метода могут эффективно дополнять друг друга.
Независимо от конкретных способов моделирования и разных модификаций в области машинной реализации моделирующих алгоритмов существуют некоторые общие методологические принципы имитационного моделирования на ЭВМ. За основу такой методики обычно принимают следующие этапы имитационного моделирования: 1) изучение объекта моделирования; 2) формулировка задачи исследования; 3) построение математической модели; 4) составление программы для ЭВМ; 5) оценка достоверности и пригодности модели; 6) планирование и обработка эксперимента.
В процессе создания имитационной модели выделяют три уровня описания; концептуальный, математический и программный, именуемые соответственно: концептуальная модель, математическая модель и программная модель.
На этапе построения концептуальной модели формулируется замысел модели. Основным содержанием этого этапа является переход от общего описания системы к ее математической модели, т. е. процесс формализации. Этот этап является эвристическим, т. е. разработчик в основном руководствуется лишь собственной интуицией, опирающейся на накопленные знания и понимание процесса функционирования системы. Достоверность полученной новой информации зависит от адекватности модели, т. е. от того, насколько правильно и полно модель отражает черты исследуемой системы, влияющие на искомый результат. Модель всегда дает упрощенное представление о системе. Говорить об адекватности модели можно лишь по отношению к определенной задаче. Поэтому при построении концептуальной модели очень важно четко конкретизировать: что моделируется и для чего (с какой целью).
Распространенными математическими схемами формализации функционирования ВС, к классу которых можно отнести микропроцессорные устройства СПИ, являются системы и сети массового облуживания, высказывательные формы, вероятностные автоматы, сети Петри, Е-сети, агрегаты. Наибольшее применение нашли СМО и сети СМО, сети Петри и их модификации, Е-сети.
Основным результатом этапа построения математической модели является моделирующий алгоритм, позволяющий имитировать функционирование системы во времени и осуществлять программную реализацию модели.
Программные средства построения имитационных моделей, применяемые в практике имитационного моделирования, развиваются в основном по двум направлениям: создание и использование языков моделирования и разработка специализированных систем моделирования с использованием алгоритмических языков общего назначения. Каждое из этих направлений имеет свои достоинства и недостатки.
В процессе применения моделирования выявились многочисленные проблемы его использования, вызванные не способом записи модели, а ее содержанием. Кардинальными являются вопросы адекватности, точности, чувствительности к вариациям различных параметров модели. Для созданной модели возникают проблемы использования ее «внутренних» свойств, таких, как устойчивость, надежность, управляемость и др. Решение указанных проблем предполагает проведение целенаправленных экспериментов, использующих не только возможности ЭВМ по имитации, но и аналитические результаты исследования соответствующих математических моделей, проведенные качественными методами. Перспективными с точки зрения ускорения моделирования являются комбинированные методы определения вероятностных характеристик, базирующиеся на совместном использовании оценок, полученных аналитическим и имитационным методами [5].
Литература
1. В.К. Морозов, А.В. Долганов Основы теории информационных сетей. Учеб. для студентов вузов. – М.: Высш. шк., 1987. – 271 с.
2. Г.Ф. Янбых, Б.А. Столяров Оптимизация информационных сетей. – М.: Радио и связь, 1987. – 232 с.
3. А.В. Бутрименко Разработка и эксплуатация сетей ЭВМ. – М.: Финансы и статистика, 1981. – 256 с.
4. Л.Р. Форд, Д.Р. Фалкерсон Потоки в сетях /перевод с английского И.А. Вайнштейна – М.: Мир, 1966. – 276 с.
5. Пугачев В.Н. Комбинированные методы определения вероятностных характеритсик. – м. Сов. Радио, 1973. – 226 с.

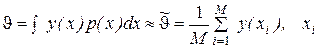
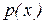 . (2.6)
. (2.6)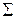 у(х)р{х)у в которой суммирование осуществляете;: по всем возможным значениям X. Функция у(х) может иметь несколько аргументов, т. е. зависеть от нескольких случайных величин. В таком случае запись (2.6) остается в силе, только интеграл надо считать многомерным, X рассматривать как вектор, а р(х)—как многомерную плотность (или функцию) вероятности. Приближенная оценка неизвестного математического ожидания, совпадающая с искомым результатом, находится как среднее арифметическое результатов независимых опытов. Это отражено в правой части (2.6). По закону больших чисел среднее арифметическое сводится к математическому ожиданию. В каждом опыте разыгрывается реалиация х случайной величины X (в i-м опыте реализация хi) в соответствии с распределением р(х) и вычисляется значение функции в виде y(хi). Индекс i подчеркивает, что для каждой (i-й) реализации процесса аргументы, составляющие вектор X, имеют свои случайные значения. Вычисленное очередное значение y(xi) добавляется к накапливаемой сумме
у(х)р{х)у в которой суммирование осуществляете;: по всем возможным значениям X. Функция у(х) может иметь несколько аргументов, т. е. зависеть от нескольких случайных величин. В таком случае запись (2.6) остается в силе, только интеграл надо считать многомерным, X рассматривать как вектор, а р(х)—как многомерную плотность (или функцию) вероятности. Приближенная оценка неизвестного математического ожидания, совпадающая с искомым результатом, находится как среднее арифметическое результатов независимых опытов. Это отражено в правой части (2.6). По закону больших чисел среднее арифметическое сводится к математическому ожиданию. В каждом опыте разыгрывается реалиация х случайной величины X (в i-м опыте реализация хi) в соответствии с распределением р(х) и вычисляется значение функции в виде y(хi). Индекс i подчеркивает, что для каждой (i-й) реализации процесса аргументы, составляющие вектор X, имеют свои случайные значения. Вычисленное очередное значение y(xi) добавляется к накапливаемой сумме 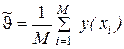 . Опыты повторяются до тех пор, пока дисперсия оценки
. Опыты повторяются до тех пор, пока дисперсия оценки 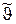 не cнизится до требуемой величины, зависящей от допустимой погрешности и коэффициента доверия. Проиллюстрируем суть метода Монте-Карло относительно простым примером. Пусть требуется оценить надежность системы (рис. 2.11). Система выполняет свою функцию, если работают цепочки блоков: 1, 2, 5, 7; 1, 3, 5, 7; 4, 6, 7. Какие-то блоки могут отказать. Каждый блок характеризуется временем безотказной работы
не cнизится до требуемой величины, зависящей от допустимой погрешности и коэффициента доверия. Проиллюстрируем суть метода Монте-Карло относительно простым примером. Пусть требуется оценить надежность системы (рис. 2.11). Система выполняет свою функцию, если работают цепочки блоков: 1, 2, 5, 7; 1, 3, 5, 7; 4, 6, 7. Какие-то блоки могут отказать. Каждый блок характеризуется временем безотказной работы  .
.
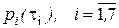 . Какова надежность системы в целом? Рассмотрим случайную величину
. Какова надежность системы в целом? Рассмотрим случайную величину = min {
= min {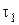 , max [min (
, max [min (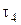 ,
, ), min [max (
), min [max (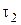 ,
, ),
), ]],
]], } (2.7)
} (2.7)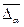 параметров модели.
параметров модели.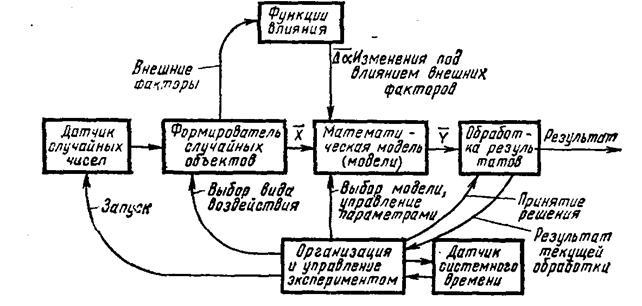

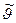 q совпадает с
q совпадает с 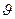 . Поскольку у(х) и р(х) считаются выбранными при первоначальной постановке задачи, необходимо выбрать q(x) так, чтобы дисперсия оценки
. Поскольку у(х) и р(х) считаются выбранными при первоначальной постановке задачи, необходимо выбрать q(x) так, чтобы дисперсия оценки 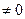 , если у(х)р(х)
, если у(х)р(х) 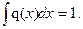 (2.7)
(2.7)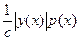 , (2.8)
, (2.8)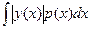 . (2.9)
. (2.9)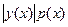 и при этом удовлетворяющую условиям нормировки. Если исходное распределение р(х) предполагает примерно одинаковые вероятности выбора х во всем диапазоне возможных значений, то новое распределение q(x), пропорциональное
и при этом удовлетворяющую условиям нормировки. Если исходное распределение р(х) предполагает примерно одинаковые вероятности выбора х во всем диапазоне возможных значений, то новое распределение q(x), пропорциональное 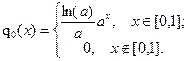
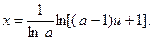 .
.
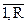 легко вычисляются через заданное распределение р(х):
легко вычисляются через заданное распределение р(х):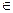 Br)=
Br)= 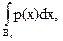 r=
r=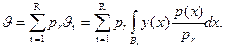
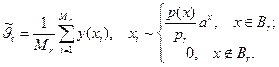

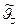 имела меньшую дисперсию, чем обычная оценка (без расслоения), достаточно, чтобы объем выборки распределялся по слоям пропорционально их вероятностям и чтобы условные средние по слоям не были одинаковы. При разбиениям по слоям надо стремиться к тому, чтобы средние по слоям как можно больше отличались друг от друга. В реальных задачах аргумент X является вектором и разбиение на слои надо проводить в многомерном пространстве. Обычно это делают с помощью некоторой функции h(х) называемой параметром расслоения. Разбивают множество значений h(х) на подмножества
имела меньшую дисперсию, чем обычная оценка (без расслоения), достаточно, чтобы объем выборки распределялся по слоям пропорционально их вероятностям и чтобы условные средние по слоям не были одинаковы. При разбиениям по слоям надо стремиться к тому, чтобы средние по слоям как можно больше отличались друг от друга. В реальных задачах аргумент X является вектором и разбиение на слои надо проводить в многомерном пространстве. Обычно это делают с помощью некоторой функции h(х) называемой параметром расслоения. Разбивают множество значений h(х) на подмножества 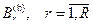 и считают х, относящимсяк слою B( r), если h(х)
и считают х, относящимсяк слою B( r), если h(х)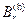 . Зависимость осредняемой функции у(х)
. Зависимость осредняемой функции у(х)