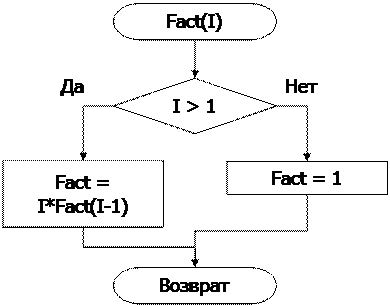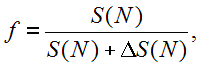Задача имеет рекурсивное решение, если его возможно сформулировать как известное преобразование другого, более простого решения той же задачи, хотя само решение (более простое) может быть неизвестно. Многократное повторение такого преобразования должно сходится к базисному утверждению.
Функция F является рекурсивной, если
1.F(N)=G(N,F(N-1)), где G известная функция;
2.F(1)–известно (базисное утверждение).
Алгоритм вычисления факториала N с использованием рекурсивной функции представляется в следующем виде:
Поиск - обнаружение нужного элемента в некотором наборе (структуре) данных. Элемент данных - это запись, состоящая из ключа (целое положительное число) и тела, содержащего некоторую информацию. Задача состоит в том, чтобы обнаружить запись с нужным ключом.
3.3.1.Линейный поиск. Элементы проверяются последовательно, по одному, до тех пор, пока нужный элемент не будет найден. Для массива из N элементов требуется, в среднем, (N+1)/2 сравнений (вычислительная сложность Оср(N)). Легко программируется, подходит для коротких массивов.
3.3.2.Двоичный (бинарный) поиск. Применим, если массив заранее отсортирован (по возрастанию ключей). Ключ поиска сравнивается с ключом среднего элемента в массиве. Если значение ключа поиска больше, то та же самая операция повторяется для второй половины массива, если меньше - то для первой. Операция повторяется до нахождения нужного элемента. На каждом шаге диапазон элементов в поиске уменьшается вдвое. Требуется, в среднем, (log2N+1)/2 сравнений (вычислительная сложность Оср(log2N)). Применяется для поиска (многократного) в больших массивах.
Сортировка (упорядочение) - переразмещение элементов данных в возрастающем или убывающем порядке. При выборе метода сортировки необходимо учитывать число сортируемых элементов (N) и до какой степени элементы уже отсортированы
Критерии оценки метода сортировки:
- количество необходимых операций сравнения в зависимости от числа элементов N, вычислительная сложность алгоритма характеризуется с помощью О-функции, аргументом которой является другая функция от N;
- эффективность использования памяти
где S(N) - объем памяти, занимаемый элементами данных до сортировки, DS(N) - объем дополнительной памяти, требуемой в процессе сортировки.
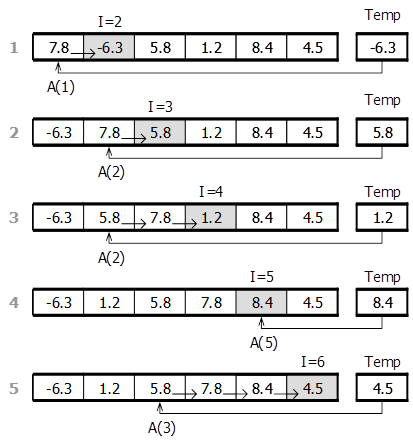
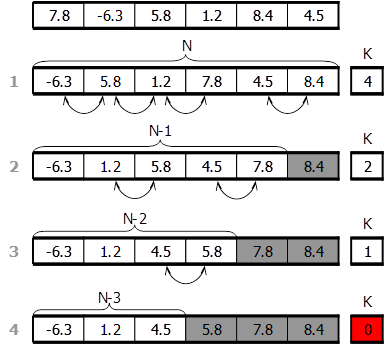
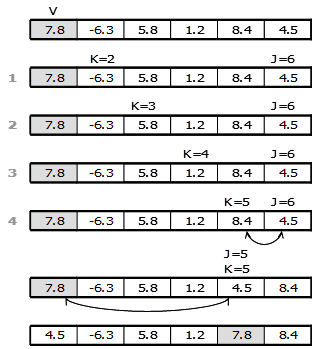
3.4.1.Сортировка методом выборки. Принцип: Из массива выбирается наименьший элемент и помещается на место первого элемента массива, затем выбирается наименьший элемент из оставшихся и помещается во второй элемент массива и т.д.
С использование псевдокода это можно записать как:
Ввести массив A(1..N)
for J = 1,N-1,1
do
Мин.Эл. = А(J)
Индекс Мин.Эл. = J
for I = J+1,N,1
do
if A(I) < Мин.Эл.
then
Мин.Эл. = A(I)
Индекс Мин.Эл. = I
end-if
end-do
A(Индекс Мин.Эл.) = A(J)
A(J) = Мин.Эл.
end-do
Вывести A(1..N)
Требуется, в среднем, N(N+1)/2 сравнений (вычислительная сложность O(N2), не зависит от начальной упорядоченности). Дополнительная память не нужна.
3.4.2.Сортировка включением. Принцип: Элементы выбираются по очереди и помещаются в нужное место.
С помощью псевдокода это запишется следующим образом:
Ввести массив A(1..N)
for I = 2,N,1
do
Temp = А(I)
A(0) = Temp
J = I-1
while A(J) > Temp
do
A(J+1) = A(J)
J = J-1
end-do
A(J+1) = Temp
end-do
Вывести A(1..N)
Требуется, в среднем, (N-1)(N/2+1)/2 сравнений (вычислительная сложность Оср(N2)).{ Осравнения } Скорость данного метода зависит от начальной упорядоченности массива. Не требуется дополнительной памяти.
3.4.3.Сортировка обменами. Принцип: Выбираются два элемента, и если друг по отношению к другу они не находятся нужном порядке, то меняются местами. Процесс продолжается пока никакие два элемента не нужно менять местами.
С помощью псевдокода это запишется следующим образом:
Ввести массив A(1..N)
K = 1, I = 1
while K <> 0
do
K = 0
for J = 1,N-I,1
do
if A(J) > A(J+1)
then
T = A(J),
A(J) = A(J+1),
A(J+1) = T, K = K+1
end-if
end-do
I = I +1
end-do
Вычислительная сложность данного метода сильно зависит от исходного расположения элементов. Минимальное значение числа сравнений – N-1 в полностью отсортированном массиве, максимальное – (N2-N)/2 при начальной сортировке в обратном порядке. Средняя вычислительная сложность Оср(N2). Дополнительная память не требуется.
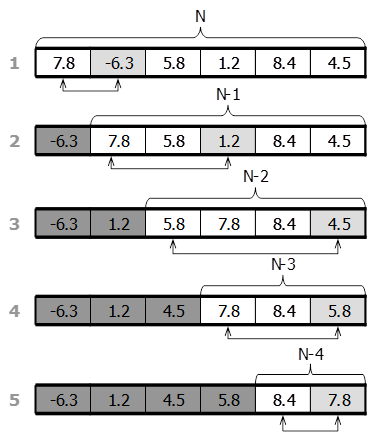
3.4.4.Сортировка распределением (метод корзин). Принцип: Элементы массива рассматриваются как совокупность цифр (символов), первый шаг - сортировка по значению старшей цифры, затем полученные подмножества (группы) сортируются по значению следующей цифры и т.д.
Каждый элемент массива А (1..N) - совокупность цифр С1С2С3…Сm, где m - количество цифр максимального элемента (если какой-то элемент содержит меньше цифр, то он слева дополняется нулями).
Средняя вычислительная сложность Оср(N log2N) и лучше, если m (число цифр) мало. Требуется дополнительный массив размером N, и еще массив размером 10, в котором подсчитывается число элементов с выделяемой цифрой 0,1,…9.
3.4.5.Быстрая сортировка. Принцип: Определенным образом выделяется пороговый элемент. На первом этапе элементы обмениваются так, что новый массив оказывается разделенным пороговым элементом на две части: в левой все элементы меньше порогового, а в правой – больше или равны пороговому. Затем подобный способ используется для разделения каждого из новых массивов на две части и т.д.
Алгоритм процедуры разбиения массива А(1..N) пороговым элементом, находящимся сначала на месте А(1).
С помощью псевдокода это запишется следующим образом:
Средняя вычислительная сложность - Оср(N log2N). Важное значение имеет выбор значения порогового элемента. В частности, если исходный массив близок к отсортированному, то при выборе пороговым элементом первого элемента (как в примере) вычислительная сложность алгоритма будет О(N2). Желательно, чтобы пороговый элемент в конечном итоге разделил массив приблизительно на две равные части.
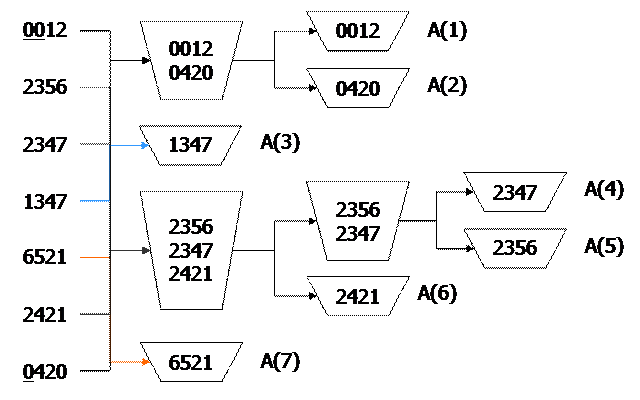
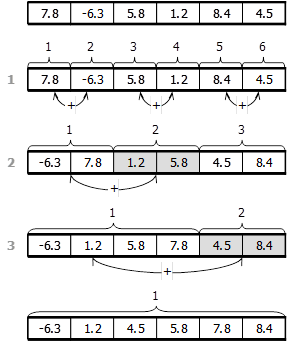
3.4.6.Сортировка слиянием. Принцип: Два отсортированных массива соединяются в один массив таким образом, чтобы и он стал отсортированным.
Алгоритм слияния отсортированных массивов B(1..M) и C(1..L) в массив A(1..M+L) заключается в следующем. В качестве А(1) выбираем наименьший из В(1) и С(1). Если это В(1), то в качестве А(2) - наименьший из В(2) и С(1) и т.д.
С помощью псевдокода это запишется следующим образом:
Ввести массивы B(1..M),С(1..L)
I = 1, J = 1
for K = 1,M+L,1
do
if I > M
then
A(K) = C(J), J = J + 1
else
if J > L
then
A(K) = B(I), I = I + 1
else
if B(I) < C(J)
then
A(K) = B(I),I = I + 1
else
A(K) = C(J),J = J + 1
end-if
end-if
end-if
end-do
Если имеется один неотсортированный массив А(1..N), то его можно рассматривать как совокупность N отсортированных массивов, каждый из которых состоит из одного элемента. Первый шаг - слияние массивов попарно, затем объединение пар в четверки и т.д.
Cредняя вычислительная сложность алгоритма - Оср(N log2N). Требуется дополнительный массив, содержащий N элементов.